







Authors

Oren Rippel(有趣的是作者喜欢中文)
Manohar Paluri
Piotr Dollar
Lubomir Bourdev
Abstract
本文介绍了一种Distance Metric Learning (DML),效果比triplet还要好,而且需要的迭代次数更少。
1 Introduction
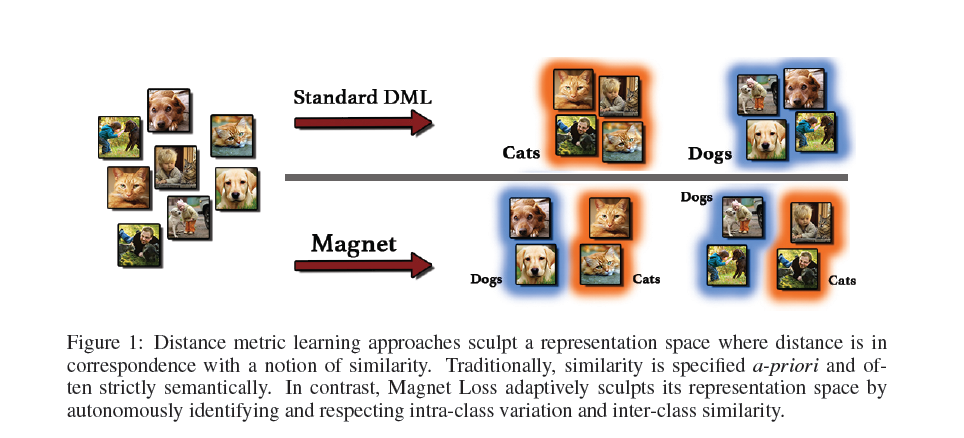
与传统的DML相比,Magenet不仅考虑intra-class variation 而且还考虑inter-class similarty。
2 Motivation
- target neighborhood structure是先验predefined的,大多数只考虑label的语义,忽略了类内的区别,应该将设置为adaptively
- objective formulation ,传统的目标函数只是针对一对或者是triplets,所以这会造成1性能下降short sightedness 2需要更多的迭代次数、
3 Magnet Loss
本文的DML算法是找出不同类别overlap的区域并将其分开。
3.1 Model Formulation
作者建立的objective如下:

公式里标注的小类就是一个大类之间的子类。
其中 rn代表某个点的representation,u(r)代表其聚类中心,K代表一个大类中利用k-means得到k个子类。与标准的dml方法不同的是这里使用了variance standardiztion。这就使得不同问题之间有了可比性,
α
可以看作是cluster separation gap。
3.2 Training Procedure
上面的模型是针对整个样本总体的,训练过程中我们要construct 一个 minibatch来实现我们的objective。
3.2.1 neighbourhood sampling
分为以下三步:
- samples a seed cluster
I1
- 相近的选取m个cluster
- 对于每个cluster选取D个example
然后计算loss
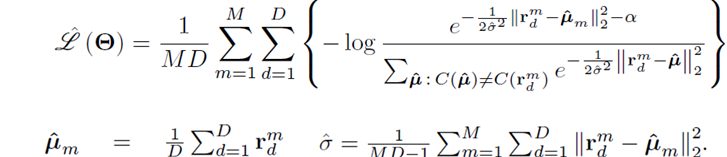
3.2.2 cluster index
训练到一定程度更新cluster index。
3.3 Evaluation Procedure

这里L=128
3.4 Relation to existing models
- triplet 将D设为2,M=2,忽略方差,就会得到triplet的公式
- Neighborhood component analysis
- Nearest class Mean
学习线性矩阵W
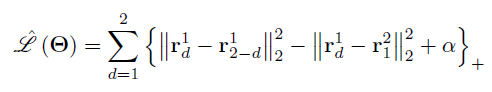
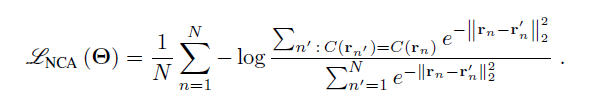
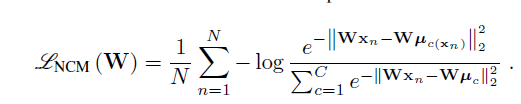
4 Experiment
作者使用带batch normalization的GoogLeNet,但是是partly trained(3 epochs),测试时用了16个augmentation的average。
试验说明Magnet loss 在多数情况下都会好于triplet和softmax,训练速度快于triplet,而且使用的kNC再Magent loss上也好于KNN
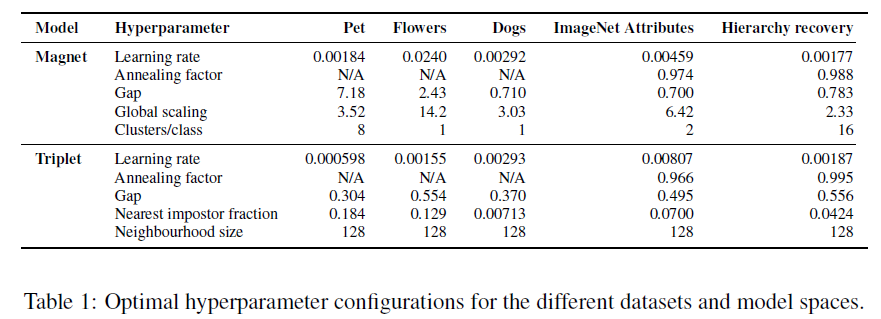
Appendix B
momentum 0.9
smaller dataset refresh index every epoch 。 for ImageNet Attributes every 1000 iterations

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









