







中文标题: 分辨自适应自监督单目深度估计
提出问题
- 传统的无监督深度估计方法如果在固定分辨率上训练,则迁移到其他分辨率上存在严重退化。
创新点
- 提出一种分辨率自适应的无监督深度学习框架(RA-Depth)来学习场景深度尺度不变性。具体地说,来为同一场景生成任意尺度的图像。
- 设计了一个双高分辨率网络,利用多路径编码器和解码器来聚合多尺度特征,以进行精确的深度推断。
- 为了明确地学习场景深度的尺度不变性,在不同尺度的深度预测中建立了一个跨尺度的深度一致性损失。
算法简介

任意比例的数据增强

- 原始尺寸图像被resize 成低,中, 高分辨率图像,然后打补丁,复制,裁切成低,中, 高分辨率原始尺寸的输入图像。
- I M I^M IM是由原图直接缩放到 ( c , h , w ) (c,h,w) (c,h,w), I L I^L IL将缩放的I拼接到 I L I^L IL左上角,再向右向下不齐。
- I H I^H IH是将原图先扩大,然后裁切成 ( c , h , w ) (c,h,w) (c,h,w)。
- 从代码来看,内参矩阵交矩无变化,只与缩放比例有关。
- 数据增强后的图像也都遵循Pose的位姿变换。
- 这样的数据增强方式在其他论文中也有看到,在基于双目匹配的无监督深度估计中,为了让单目预测网络克服对水平方向的惯性记忆,将水平方向进行嫁接。参考博文。

- 但是参考方法中仅仅在单一分辨率下进行嫁接,而本文则在不同分辨率随机空间位置下嫁接。
Dual HRNet
- 使用HRnet18作为编码器,类HRnet结构作为解码器。
- HRNet的特点:1.参数量少。2. 特征沟通多。
- 一个自下而上的High-Resolution Decoder(纯CNN).
跨尺度深度一致性损失
- 约束预测结果中 D t L 、 D t M 、 D t H D^L_t、D^M_t、D^H_t DtL、DtM、DtH中对应区域的深度应该相同。
实验结果
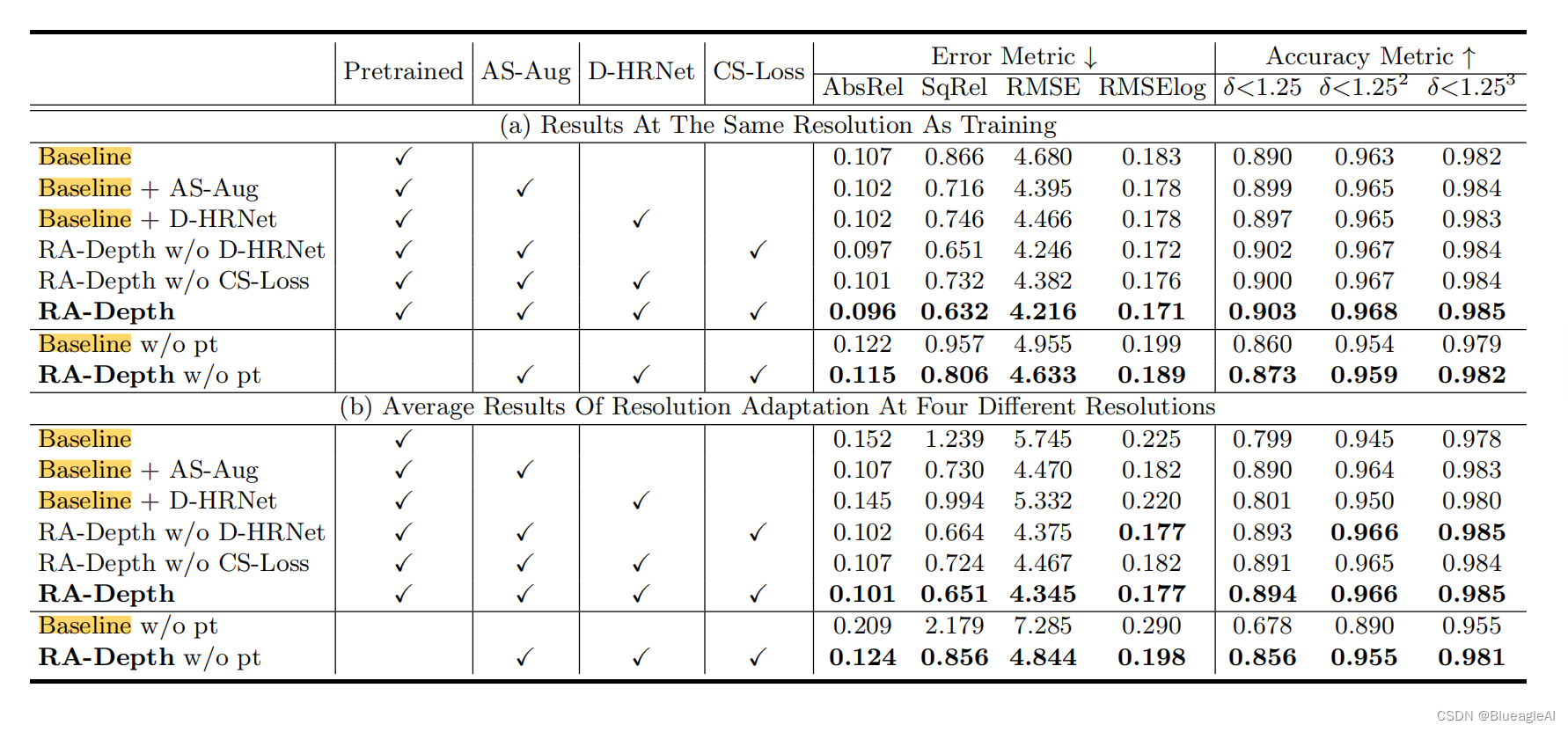
- 消融实验中的BaseLine是HRnet18+Mono2-Decoder。
参考文献
He M, Hui L, Bian Y, et al. RA-Depth: Resolution Adaptive Self-supervised Monocular Depth Estimation[C]//Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVII. Cham: Springer Nature Switzerland, 2022: 565-581.
















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











