







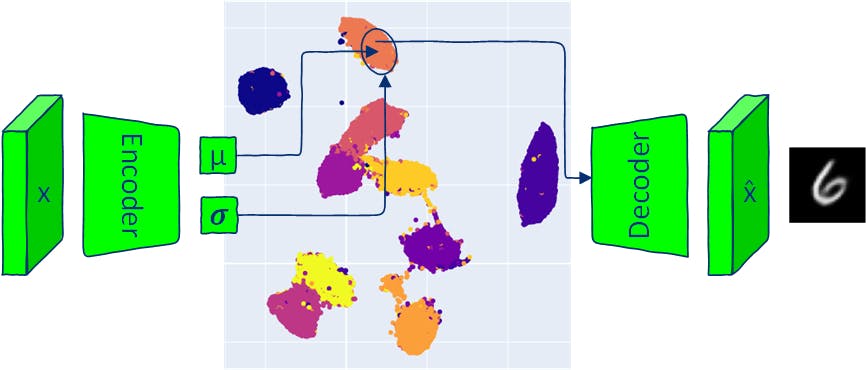
与传统的自动编码器一样,VAE架构有两个部分:编码器和解码器。传统的AE模型将输入映射到一个潜在空间向量,并从这个向量重建输出。
VAE将输入映射到一个多元正态分布(multivariate normal distribution)中(编码器输出每个潜在维度的均值和方差)。
由于VAE编码器产生一个分布,因此可以通过从该分布中采样并将采样的潜在向量传递给解码器来生成新数据。从生成的分布中采样以生成输出图像意味着VAE允许生成与输入数据相似但相同的新数据。
本文探讨了VAE体系结构的组件,并提供了几种使用VAE模型生成新图像(采样)的方法。所有的代码都可以在Google Colab获得。
1、VAE模型实现
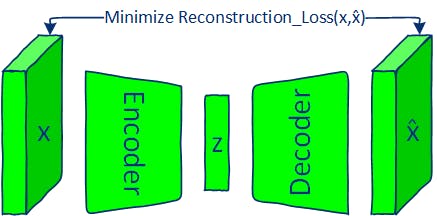
通过最小化重构损失(例如BCE或MSE)来训练AE模型。
自动编码器和变分自动编码器都有两个部分:编码器和解码器。AE的编码器神经网络学习将每个图像映射到潜在空间中的单个向量,解码器学习从编码器的潜在向量重建原始图像。
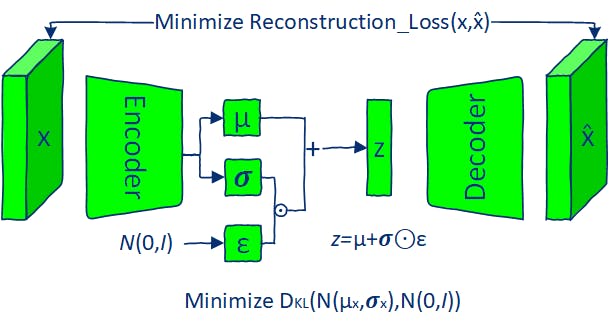
通过最小化重构损失和KL-散度来训练VAE模型。
VAE的编码器神经网络输出的参数定义了潜在空间的每个维度的概率分布(多元分布)。对于每个输入,编码器为潜在空间的每个维度产生平均值和方差。
输出均值和方差用于定义多元高斯分布。解码器神经网络与AE模型相同。
① VAE损失
训练VAE模型的目标是最大化从提供的潜在向量生成真实图像的可能性。在训练过程中,VAE模型将两个损失最小化。
- reconstruction loss:输入图像和解码器输出之间的差异。
- Kullback-Leibler散度损失(KL散度是两个概率分布之间的统计距离):编码器输出的概率分布与先验分布(标准正态分布)之间的距离,有助于正则化潜在空间。
② Reconstruction Loss
常见的重构损失有二院交叉熵(binary cross-entropy,BCE)和均方误差(mean squared error,MSE)。本文中,我将使用MNIST数据集进行演示。MNIST图像只有一个通道,像素值在0到1之间。
reconstruction_loss = nn.BCELoss(reduction='sum')
③ Kullback-Leibler Divergence
如上所述,KL散度评估两个分布之间的差异。注意它不具有距离的对称性质: K L ( P ∣ ∣ Q ) ! = K L ( Q ∣ ∣ P ) KL(P||Q)!=KL(Q||P) KL(P∣∣Q)!=KL(Q∣∣P)。
需要比较的两个分布是:
- 给定输入图像 x x x的编码器输出的潜在空间: q ( z ∣ x ) q(z|x) q(z∣x)
- 潜在空间先验 p ( z ) p(z) p(z),它被假设为一个正态分布,在每个潜在空间维度 N ( 0 , 1 ) N(0,1) N(0,1)中均值为0,标准差为1。
这样的假设简化了KL散度的计算,并鼓励潜在空间遵循已知的、可管理的分布。
from torch.distributions.kl import kl_divergence
def kl_divergence_loss(z_dist):
return kl_divergence(z_dist,
Normal(torch.zeros_like(z_dist.mean),
torch.ones_like(z_dist.stddev))
).sum(-1).sum()
④ 编码器
class Encoder(nn.Module):
def __init__(self, im_chan=1, output_chan=32, hidden_dim=16):
super(Encoder, self).__init__()
self.z_dim = output_chan
self.encoder = nn.Sequential(
self.init_conv_block(im_chan, hidden_dim),
self.init_conv_block(hidden_dim, hidden_dim * 2),
# double output_chan for mean and std with [output_chan] size
self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True),
)
def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False):
layers = [
nn.Conv2d(input_channels, output_channels,
kernel_size=kernel_size,
padding=padding,
stride=stride)
]
if not final_layer:
layers += [
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
]
return nn.Sequential(*layers)
def forward(self, image):
encoder_pred = self.encoder(image)
encoding = encoder_pred.view(len(encoder_pred), -1)
mean = encoding[:, :self.z_dim]
logvar = encoding[:, self.z_dim:]
# encoding output repres 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4767
4767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









