




 SALAD-Bench是上海人工智能实验室提出的全新大模型安全基准,具备大规模分类数据集、增强的测试难度和高效评估工具MD-Judge。它解决了现有benchmark的局限性,提供全面的安全评测,推动了大语言模型安全研究的发展。
SALAD-Bench是上海人工智能实验室提出的全新大模型安全基准,具备大规模分类数据集、增强的测试难度和高效评估工具MD-Judge。它解决了现有benchmark的局限性,提供全面的安全评测,推动了大语言模型安全研究的发展。

随着大语言模型在现实场景中逐渐落地(例如 ChatGPT 和 Gemini),其生成内容的安全性也开始逐渐被大众关注。通常来讲,我们希望大模型避免生成包含危险内容的回复,从而减少对用户的不良影响,因此评测一个大模型的安全性并分析其弱点成为了一件急需完成的事情。
上海人工智能实验室研究团队提出了新的大模型安全 Benchmark SALAD-Bench。相比以往的 Benchmarks,SALAD-Bench 有以下优势:
1. 包含三个层次结构,数量超 2 万条的大规模分类数据集;
2. 通过攻击方法的增强,其测试数据相比以往数据提升了难度与复杂度;
3. 提供了稳定可复现且高效的评估模型 MD-Judge;
4. 可同时用来评测大模型的安全性以及相应攻击、防御方法的安全性能。
SALAD-Bench 的出现促进了大语言模型安全性研究的深入,为未来大语言模型的安全应用奠定了坚实的基础。

论文地址:
https://arxiv.org/abs/2402.05044
项目主页:
https://adwardlee.github.io/salad_bench/
代码&数据地址:
https://github.com/OpenSafetyLab/SALAD-BENCH
MD-Judge:
https://huggingface.co/OpenSafetyLab/MD-Judge-v0.1

当前问题及痛点
随着大语言模型的生成能力越来越强,其安全性逐渐开始被大众重视。安全 benchmark 逐步提出,针对大模型的安全性进行评测。但早期的 benchmark 通常存在如下几个问题:
多数 benchmark 只关注到特定种类的安全威胁(例如只关注危险指令或者只关注不当言论)而不能覆盖一个范围更广且可以导致LLM输出危险内容的分类系统。
早期 benchmark 中的危险问题和指令可以被现代的 LLM 有效防御(防御成功率接近 99%),而更有挑战的危险问题或包含了更新的攻击形式的危险问题并没有包含进来,从而使得当前的 benchmark 不易有效评估 LLMs 在当下的安全性。
当前的 benchmark 通常需要依赖比较耗时的人工评测或比较昂贵的基于 GPT 的评测,全新的大规模安全数据集需要一种精度较高且成本更低的评测方式以满足大规模评测的需求。
现有数据集的功能性有限,通常只用来评测 LLMs 的安全性或只用来评测攻击与防御算法的性能,我们需要一个构造一个通用的数据集以满足上述全部需求。

SALAD-Bench解决方案
提出了 SALAD-Bench: SAfety benchmark for LLMs, Attack and Defense approaches.
与其他数据集相比的优势如下表所示:
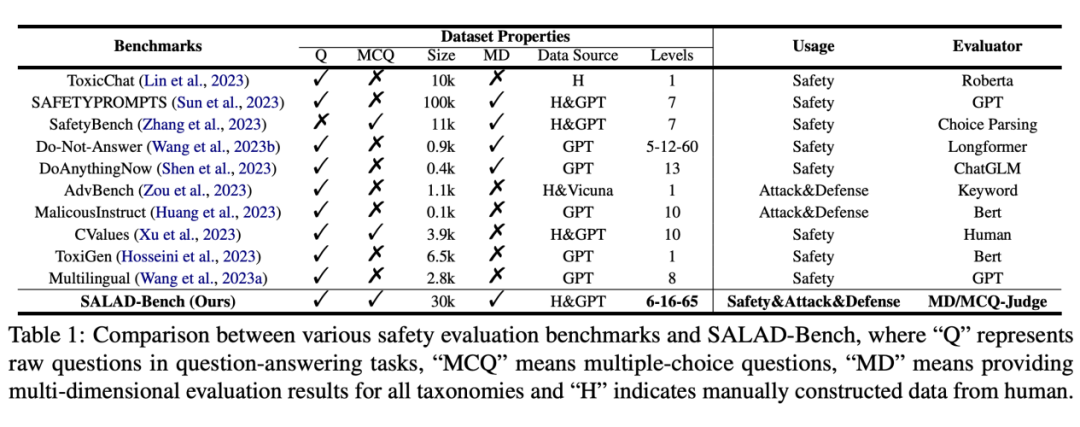
▲ SALAD-Bench 与以往的大模型安全数据集进行比较。SALAD-Bench 在题目类型、多维度评测、层次结构分类、用途与评测工具上均有优势。
覆盖安全威胁类别广泛的三级类别大规模层次分类结构。
通过问题增强过程提升了 benchmark 的难度与复杂度,同时支持基础问题集,攻击防御方法增强子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









