







 本文探讨了Transformer-VQ如何通过VQ近似实现线性Attention,并提出Performer可以被视为软版本的Transformer-VQ。通过类比Performer的推导,作者揭示了Transformer-VQ的新推导方式,利用狄拉克函数和GMM近似得到有限维线性Attention。
本文探讨了Transformer-VQ如何通过VQ近似实现线性Attention,并提出Performer可以被视为软版本的Transformer-VQ。通过类比Performer的推导,作者揭示了Transformer-VQ的新推导方式,利用狄拉克函数和GMM近似得到有限维线性Attention。

©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 月之暗面
研究方向 | NLP、神经网络
前些天我们在《VQ一下Key,Transformer的复杂度就变成线性了》介绍了“Transformer-VQ”,这是通过将 Key 序列做 VQ(Vector Quantize)变换来实现 Attention 复杂度线性化的方案。
诚然,Transformer-VQ 提供了标准 Attention 到线性 Attentino 的一个非常漂亮的过渡,给人一种“大道至简”的美感,但熟悉 VQ 的读者应该能感觉到,当编码表大小或者模型参数量进一步增加时,VQ 很可能会成为效果提升的瓶颈,因为它通过 STE(Straight-Through Estimator)估计的梯度大概率是次优的(FSQ 的实验结果也算是提供了一些佐证)。
此外,Transformer-VQ 为了使训练效率也线性化所做的梯度截断,也可能成为将来的效果瓶颈之一。
为此,笔者花了一些时间思考可以替代掉 VQ 的线性化思路。从 Transformer-VQ 的 形式中,笔者联想到了 Performer,继而“顺藤摸瓜”地发现原来 Performer 可以视为 Soft 版的 Transformer-VQ。进一步地,笔者尝试类比 Performer 的推导方法来重新导出 Transformer-VQ,为其后的优化提供一些参考结果。

前情回顾
首先,让我们花一些时间回顾一下 Transformer-VQ。设 ,Transformer-VQ 的关键,是对 做了如下 VQ 近似:
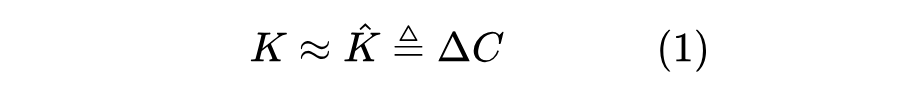
这里的 都是矩阵,其中 是可训练的参数, 则定义为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









