







©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
今天我们分享一下论文《Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation》[1],顾名思义,这是一篇探讨如何更快更好地蒸馏扩散模型的新论文。
即便没有做过蒸馏,大家应该也能猜到蒸馏的常规步骤:随机采样大量输入,然后用扩散模型生成相应结果作为输出,用这些输入输出作为训练数据对,来监督训练一个新模型。
然而,众所周知作为教师的原始扩散模型通常需要多步(比如 1000 步)迭代才能生成高质量输出,所以且不论中间训练细节如何,该方案的一个显著缺点是生成训练数据太费时费力。此外,蒸馏之后的学生模型通常或多或少都有效果损失。
有没有方法能一次性解决这两个缺点呢?这就是上述论文试图要解决的问题。

思路简介
论文将所提方案称为 “Score identity Distillation(SiD)”,该名字取自它基于几个恒等式(Identity)来设计和推导了整个框架。但事实上,它的设计思想跟几个恒等式并没有直接联系,其次几个恒等式都是已知的公式而不是新的,所以怎么看这都是一个相当随意的名字。
本文标题将其称之为“重出江湖”,是因为 SiD 的思路跟之前在《从去噪自编码器到生成模型》介绍过的论文《Learning Generative Models using Denoising Density Estimators》[2](简称 “DDE”)几乎一模一样,甚至最终形式也有五六分相似。
只不过当时扩散模型还未露头角,所以 DDE 是将其作为一种新的生成模型提出的,在当时反而显得非常小众。而在扩散模型流行的今天,它可以重新表述为一种扩散模型的蒸馏方法,因为它需要一个训练好的去噪自编码器——这正好是扩散模型的核心。
接下来笔者用自己的思路去介绍 SiD。假设我们有一个在目标数据集训练好的教师扩散模型 ,它需要多步采样才能生成高质量图片,我们的目标则是要训练一个单步采样的学生模型 ,也就是一个类似 GAN 的生成器,输入指定噪声 就可以直接生成符合要求的图像。
如果我们有很多的 对,那么直接监督训练就可以了(当然损失函数和其他细节还需要进一步确定,读者可以自行参考相关工作),但如果没有呢?肯定不是不能训,因为就算没有 也能训,比如 GAN,所以关键是怎么借助已经训练好的扩散模型提供更好的信号。
SiD 及前作 DDE 使用了一个看上去很绕但是也很聪明的思路:
如果 产生的数据分布跟目标分布很相似,那么拿 生成的数据集去训练一个扩散模型 的话,它也应该跟 很相似?

初级形式
这个思路的聪明之处在于,它绕开了对教师模型生成样本的需求,也不需要训练教师模型的真实样本,因为“拿 生成的数据集去训练一个扩散模型”只需要学生模型 生成的数据(简称“学生数据”),而 是一个单步模型,用它来生成数据时间上比较友好。
当然,这还只是思路,将其转换为实际可行的训练方案还有一段路要走。首先回顾一下扩散模型,我们采用《生成扩散模型漫谈:DDPM = 贝叶斯 + 去噪》的形式,我们使用如下方式对输入 进行加噪:
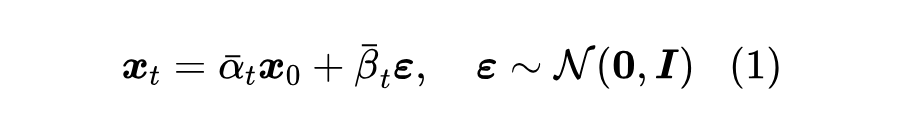
换言之 。训练 的方式则是去噪:
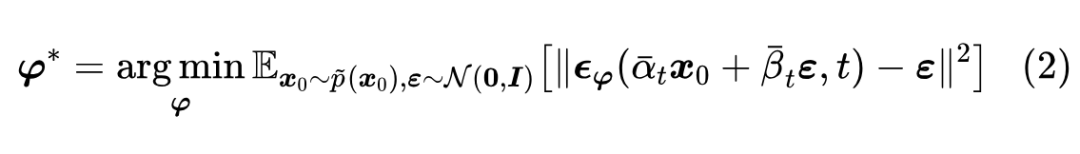
这里的 就是教师模型的训练数据。同样地,如果我们想用 的学生数据一个扩散模型,那么训练目标是
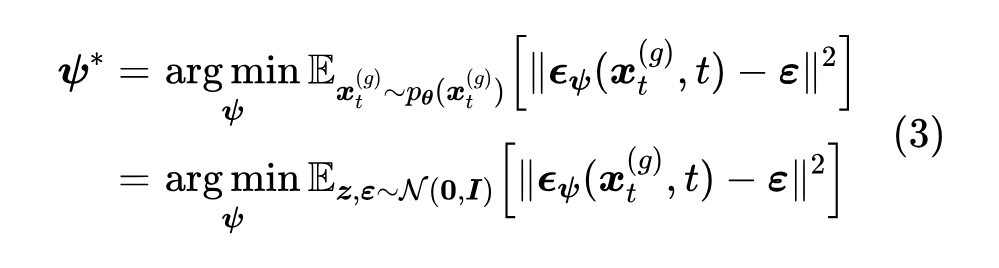
这里 ,是由学生数据加噪后的样本,其分布记为 ;第二个等号用到了“ 直接由 和 决定”的事实,所以对 的期望等价于对 的期望。现在我们有两个扩散模型,它们之间的差异一定程度上衡量了教师模型和学生模型生成的数据分布差异,所以一个直观的想法是通过最小化它们之间的差异,来学习学生模型:
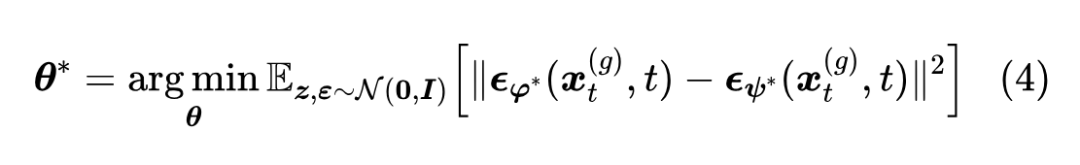
注意式(3)的优化依赖于 ,所以当 通过式(4)发生改变时, 的值也随之改变,因此式(3)和式(4)实际上需要交替优化,类似 GAN 一样。

点睛之笔
谈到 GAN,有读者可能会“闻之色变”,因为它是出了名的容易训崩。很遗憾,上述提出的式(3)和式(4)交替训练的方案同样有这个问题。首先它理论上是没有问题的,问题出现在理论与实践之间的 gap,主要体现在两点:
1. 理论上要求先求出式(3)的最优解,然后才去优化式(4),但实际上从训练成本考虑,我们并没有将它训练到最优就去优化式(4)了;
2. 理论上 随 而变,即应该写成 ,从而在优化式(4)时应该多出一项 对 的梯度,但实际上在优化式(4)时我们都只当 是常数。
这两个问题非常本质,它们也是 GAN 训练不稳定的根本原因,此前论文《Revisiting GANs by Best-Response Constraint: Perspective, Methodology, and Application》也特意从第 2 点出发改进了 GAN 的训练。
看上去,这两个问题哪一个都无法解决,尤其是第 1 个,我们几乎不可能总是将 求到最优,这在成本上是绝对无法接受的,至于第 2 个,在交替训练场景下我们也没什么好办法获得 的任何有效信息,从而更加不可能获得它关于 的梯度。
幸运的是,对于上述扩散模型的蒸馏问题,SiD 提出了一个有效缓解这两个问题的方案。SiD 的想法可谓非常“朴素”:既然 取近似值和 当成常数都没法避免,那么唯一的办法就是通过恒等变换,尽量消除优化目标(4)对 的依赖了。只要式(4)对 的依赖足够弱,那么上述两个问题带来的负面影响也能足够弱了。
这就是 SiD 的核心贡献,也是让人拍案叫绝的“点睛之笔”。

恒等变换
接下来我们具体来看做了什么恒等变换。我们先来看式(2),它的优化目标可以等价地改写成
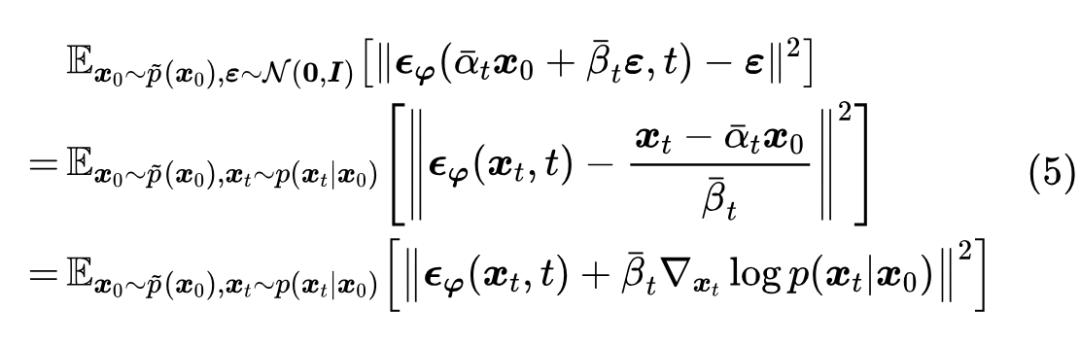
根据《生成扩散模型漫谈:一般框架之SDE篇》的得分匹配相关结果,上述目标的最优解是 ,同理式(3)的最优解是 。此时式(4)的目标函数可以等价地改写成
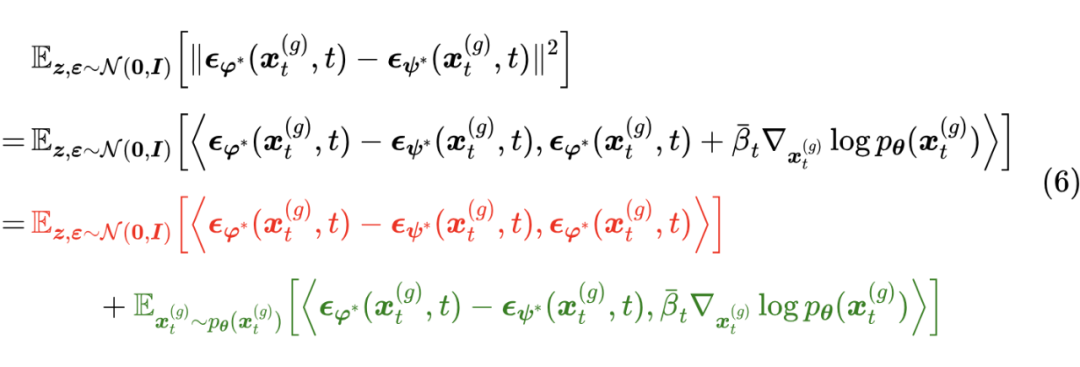
接下来要用到在《生成扩散模型漫谈:得分匹配 = 条件得分匹配》证明过的一个恒等式,来化简上式的绿色部分:
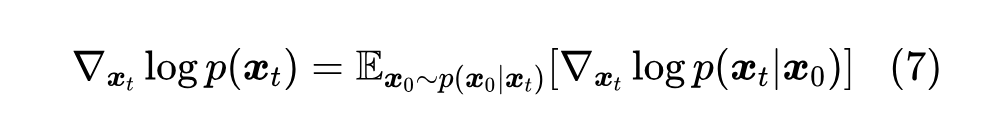
这是由概率密度定义以及贝叶斯公式推出的恒等式,不依赖于 的形式。将该恒等式代入到绿色部分,我们有
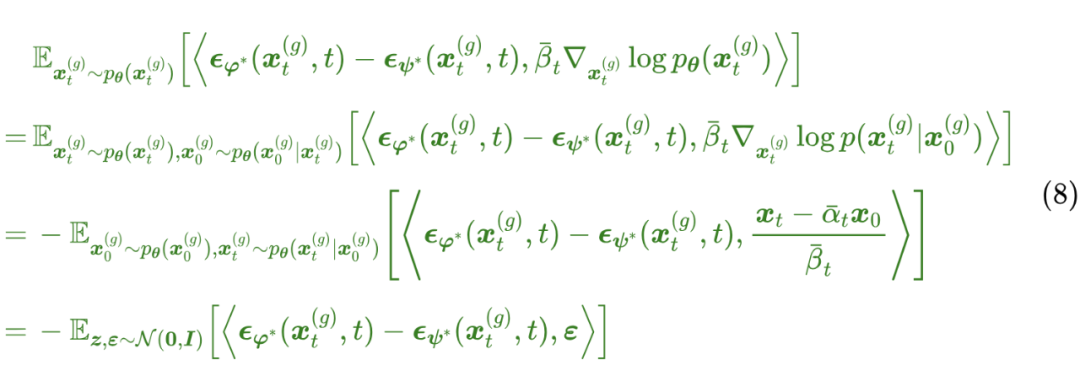
跟红色部分合并,就得到学生模型新的损失函数
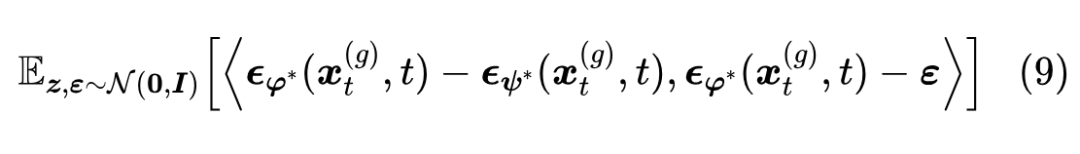
这就是 SiD 的核心结果,原论文的实验结果显示它能够高效地实现蒸馏,而式(4)则没有训练出有意义的结果。
相比式(4),上式(9)出现 的次数显然更少,也就是对 的依赖更弱。此外,上式是基于最优解 恒等变换而来的,也就是说相当于(部分地)预先窥见了 的精确值,这也是它更优越的原因之一

其他细节
到目前为止,本文的推导基本上是原论文推导的重复,但出了个别记号上的不一致外,还有一些细节上的不同,下面简单澄清一下,以免读者混淆。
首先,论文的推导默认了 ,这是沿用了《Elucidating the Design Space of Diffusion-Based Generative Models》[3] 一文的设置。然而尽管 很有代表性,并且能简化形式,但并不能很好地覆盖所有扩散模型类型,所以本文的推导保留了 。其次,论文的结果是以 为标准给出的,这显然跟扩散模型常见的以 为准不符,笔者暂时没有领悟原论文的表述方式的优越所在。
最后,原论文发现损失函数(4)实在太不稳定,往往对效果还起到负面作用,所以 SiD 最终取了式(4)的相反数作为额外的损失函数,加权到改进的损失函数(9)上,这在个别情形还能取得更优的蒸馏效果。至于具体实验细节和数据,读者自行翻阅原论文就好。
相比其他蒸馏方法,SiD 的缺点是对显存的需求比较大,因为它同时要维护三个模型 、 和 ,它们具有相同的体量,虽然并非同时进行反向传播,但叠加起来也使得总显存量翻了一倍左右。针对这个问题,SiD 在正文末尾提出,未来可以尝试对预训练的模型加 LoRA 来作为额外引入的两个模型,以进一步节省显存需求。

延伸思考
笔者相信,对于一开始的“初级形式”,即式(3)和式(4)的交替优化,那么不少理论基础比较扎实并且深入思考过的读者都有机会想到,尤其是已经有 DDE “珠玉在前”,推出它似乎并不是那么难预估的事情。但 SiD 的精彩之处是并没有止步于此,而是提出了后面的恒等变换,使得训练更加稳定高效,这体现了作者对扩散模型和优化理论非常深刻的理解。
同时,SiD 也留下了不少值得进一步思考和探索的问题。比如,学生模型的损失(9)的恒等化简到了尽头了吗?并没有,因为它的内积左边还有 ,还可以用同样的方式进行化简。具体来说,我们有
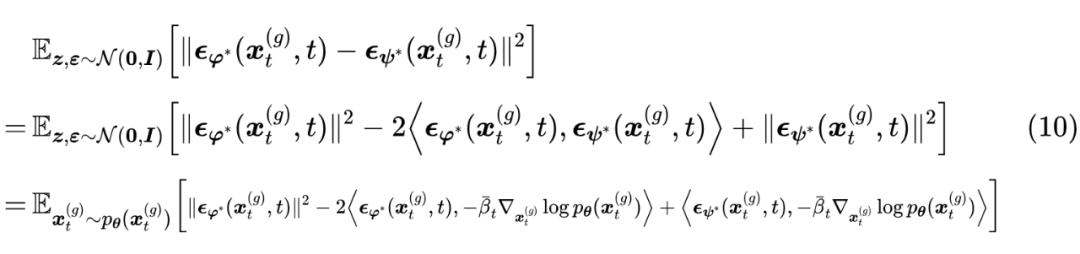
这里的每一个 都可以用相同的恒等变换(7)最终转化为单个 (但要注意 只能转换一个,不能都转),而式(9)相当于只转了一部分,如果全部转会更好吗?因为没有实验结果,所以暂时不得而知。但有一个特别有意思的形式,就是只转换上面的中间部分的话,该损失函数可以写成
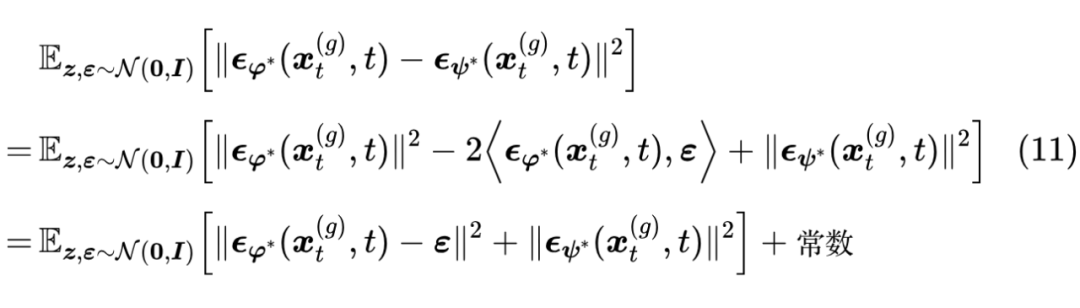
这是学生模型,也就是生成器的损失,然后我们再对比学生数据去噪模型的损失(3):
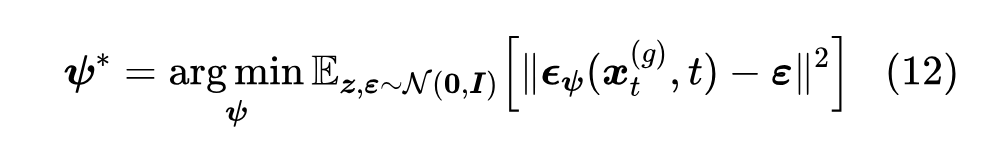
这两个式子联合起来看,我们可以发现学生模型实则在向教师模型看齐,并且试图远离学生数据所训练的去噪模型,形式上很像 LSGAN, 类似 GAN 的判别器,不同的地方是,GAN 的判别器一般是两项损失相加而生成器是单项损失,SiD 则反过来了。这其实体现了两种不同的学习思路:
1、GAN:一开始造假者(生成器)和鉴别者(判别器)都是小白,鉴别者不断对比真品和赝品来提供自己的鉴宝水平,造假者则通过鉴别者的反馈不断提高自己的造假水平;
2、SiD:完全没有真品,但有一个绝对权威的鉴宝大师(教师模型),造假者(学生模型)不断制作赝品,同时培养自己的鉴别者(学生数据训练的去噪模型),然后通过自家鉴别者跟大师的交流来提高自己造假水平。
可能有读者会问:为什么 SiD 中的造假者不直接向大师请教,而是要通过培养自己的鉴别者来间接获得反馈呢?
这是因为直接跟大师交流的话,可能会出现的问题就是长期都只交流同一个作品的技术,最终只制造出了一种能够以假乱真的赝品(模式坍缩),而通过培养自己的鉴别者一定程度上就可以避免这个问题,因为造假者的学习策略是“多得到大师的好评,同时尽量减少自家人的好评”,如果造假者还是只制造一种赝品,那么大师和自家的好评都会越来越多,这不符合造假者的学习策略,从而迫使造假者不断开发新的产品而不是固步自封。
此外,读者可以发现,SiD 整个训练并没有利用到扩散模型的递归采样的任何信息,换句话说它纯粹是利用了去噪这一训练方式所训练出来的去噪模型,那么一个自然的问题是:如果单纯为了训练一个单步的生成模型,而不是作为已有扩散模型的蒸馏,那么我们训练一个只具有单一噪声强度的去噪模型会不会更好?
比如像 DDE 一样,固定 、某个常数 取训练一个去噪模型,然后用它来重复 SiD 的训练过程,这样会不会能够简化训练难度、提高训练效率?这也是一个值得进一步确认的问题。

文章小结
在这篇文章中,我们介绍了一种新的将扩散模型蒸馏为单步生成模型的方案,其思想可以追溯到前两年的利用去噪自编码器训练生成模型的工作,它不需要获得教师模型的真实训练集,也不需要迭代教师模型来生成样本对,而引入了类似 GAN 的交替训练,同时提出了关键的恒等变换来稳定训练过程,整个方法有颇多值得学习之处。

参考文献
[1] https://papers.cool/arxiv/2404.04057
[2] https://papers.cool/arxiv/2001.02728
[3] https://papers.cool/arxiv/2206.00364
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·















 4130
4130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









