







✅博主简介:本人擅长数据处理、建模仿真、程序设计、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
一、锅炉燃烧系统建模
在CFB(循环流化床)锅炉燃烧中,燃烧过程是一个多变量、非线性、强耦合的复杂过程。为了实现燃烧优化,关键在于建立一个准确描述燃烧系统输入与输出关系的模型。针对这个问题,我们使用了深度学习中的长短时记忆神经网络(LSTM)来构建模型。LSTM在处理时间序列数据方面具有独特的优势,能够捕捉到燃烧过程中的动态特性。
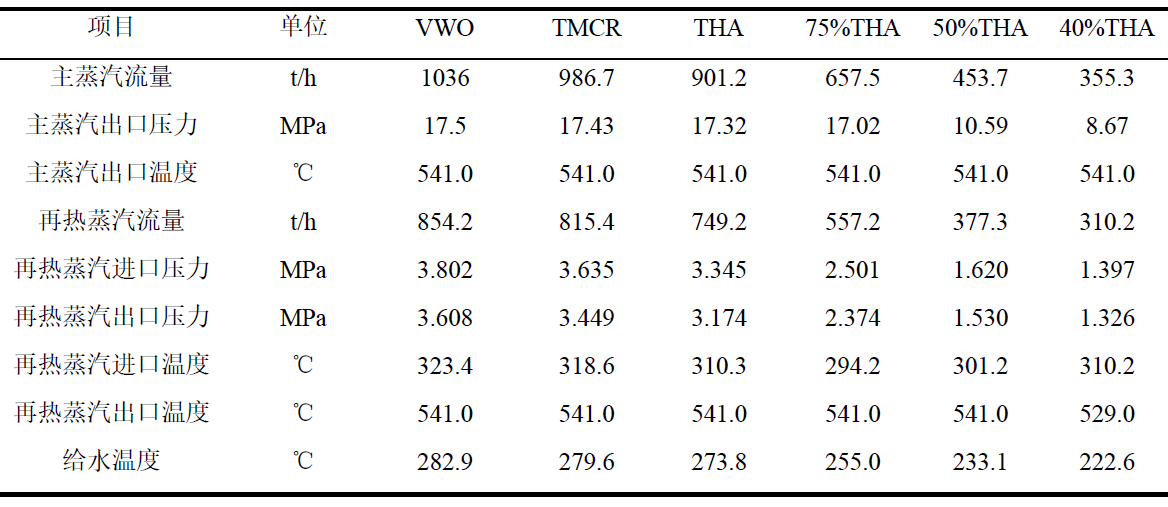
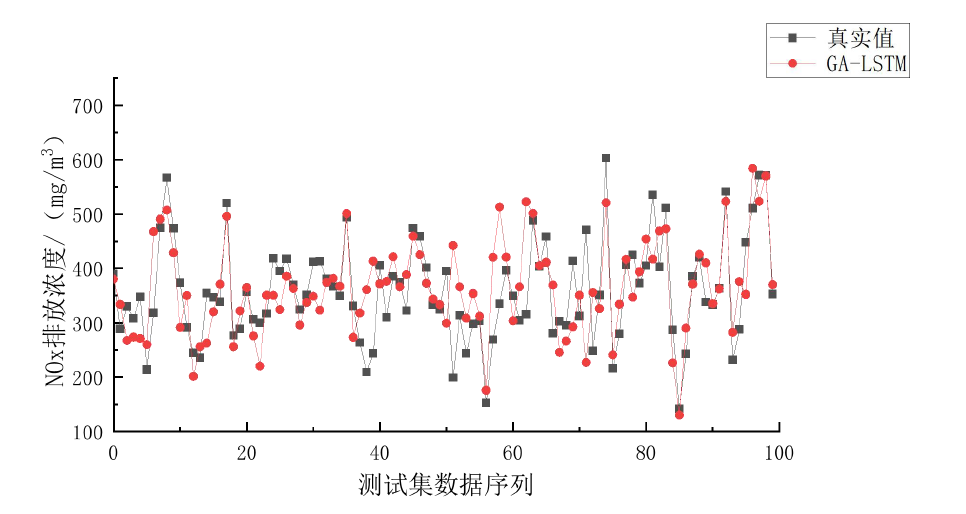
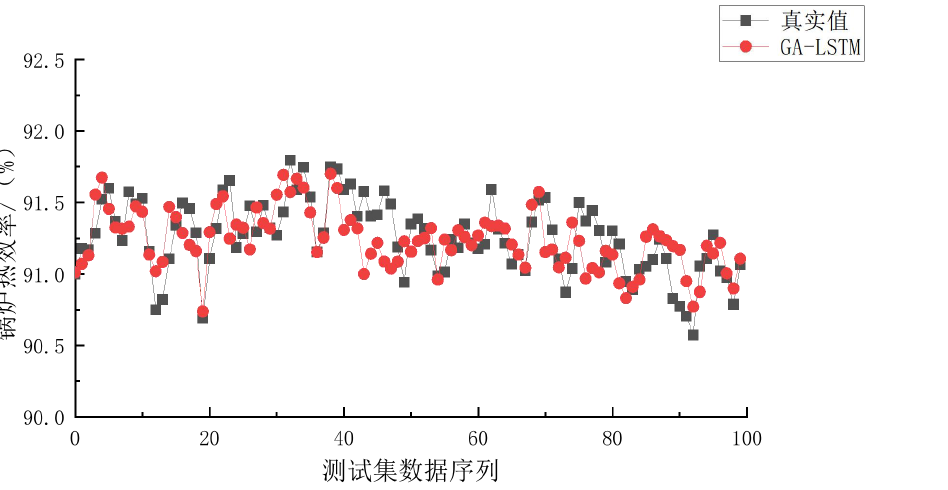
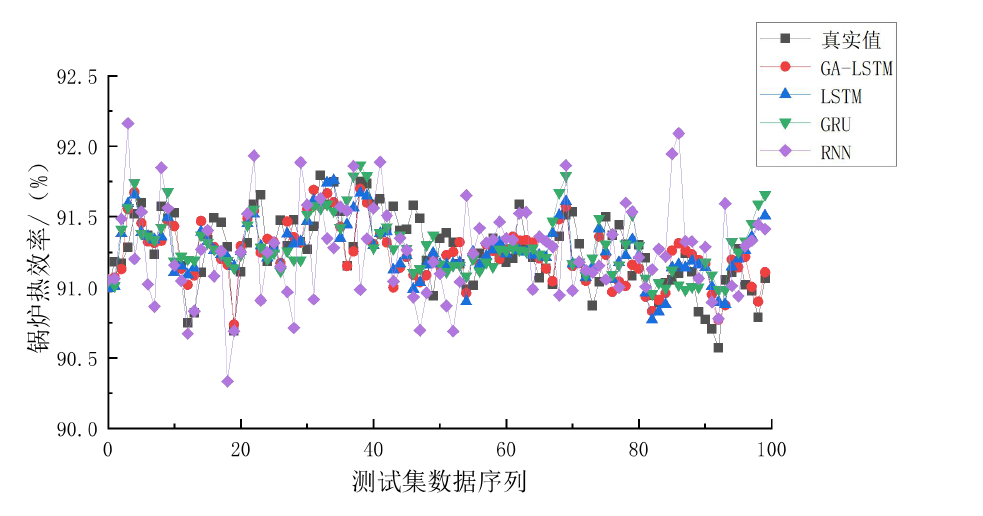
通过对DCS(分散控制系统)中的历史运行数据进行分析,我们为某300MW亚临界CFB锅炉建立了两个预测模型:一个用于预测锅炉的热效率,另一个用于预测NOx炉膛出口原始生成浓度。然而,LSTM模型的性能高度依赖于其参数的选择。为了优化LSTM模型的参数,我们引入了遗传算法(GA),通过GA对LSTM模型参数进行全局寻优,确保模型在预测精度和泛化能力上都能达到最佳状态。
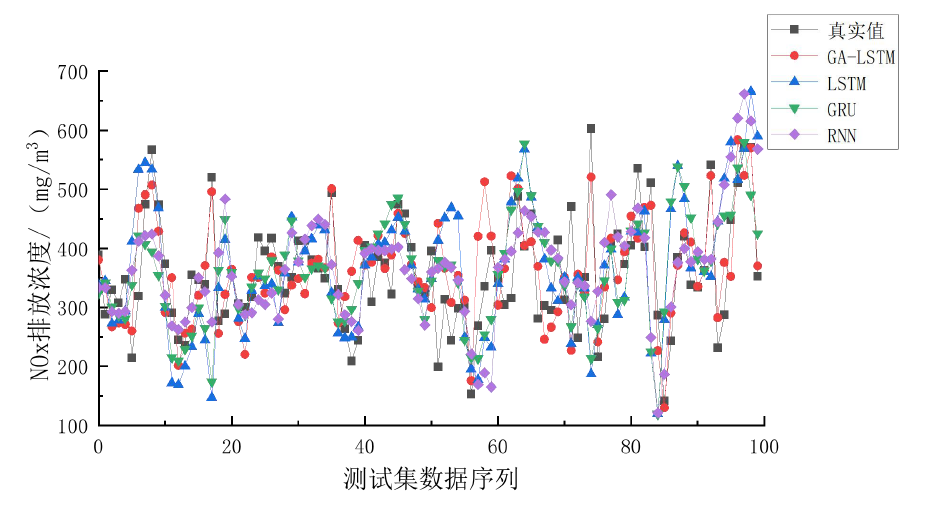
在模型对比中,GA-LSTM模型的性能显著优于其他模型。具体来说,NOx炉膛出口原始生成浓度预测模型在测试样本集上的RMSE(均方根误差)为33.128,MAPE(平均绝对百分比误差)为0.013,R-square(决定系数)为0.9962;而锅炉热效率预测模型的RMSE为0.271,MAPE为0.012,R-square为0.9973。这些指标表明,经过数据预处理和遗传算法参数寻优后的GA-LSTM模型在测试集上的预测能力和拟合精度均优于其他模型,能够更好地完成多变量非线性拟合。
二、多目标优化算法的应用
在建立了锅炉热效率和NOx浓度预测模型的基础上,我们进一步采用了基于指标和拥挤距离的多目标进化算法(IDBEA)对一次风量、二次风门开度、给煤率和炉膛出口氧量进行优化。多目标优化的目的是在确保锅炉热效率的同时,尽可能降低NOx的生成量。IDBEA通过增加拥挤距离选择策略,提高了算法的多样性,使得在优化过程中可以更好地探索不同参数组合的最优解。
针对低、中、高负荷下的9组工况,IDBEA对NOx炉膛出口原始生成浓度进行了优化。结果显示,经过优化后,NOx浓度最高比实际运行工况减少了96.37mg/m³,平均下降17.35%,优化效果显著;同时,锅炉热效率最高提升1.9%,平均提升0.88%。这表明IDBEA不仅有效降低了NOx的生成浓度,而且在一定程度上提高了锅炉的热效率,实现了以NOx浓度为主要优化目标的燃烧优化。
三、锅炉燃烧优化系统的设计与实现
在上述多目标优化进化算法的基础上,我们设计并开发了锅炉燃烧优化系统。该系统的主要功能是实时监测锅炉运行状态、维护燃烧过程,并通过优化算法对燃烧过程进行控制,以达到降低污染物排放和提高燃烧效率的目的。
系统采用了B/S(浏览器/服务器)架构,前端基于Vue框架,后端基于Spring Boot框架,整体系统模块化设计,包含系统登录模块、运行监控模块、预测对比模块、系统监控模块以及系统管理模块。这样的架构设计确保了系统的可扩展性和可维护性。
在实际应用中,锅炉燃烧优化系统可以直接读取电厂DCS控制系统采集的锅炉运行参数,并利用底层多目标优化算法进行燃烧控制优化。通过系统的操作界面,运行人员可以清晰地看到燃烧多目标优化数学模型的计算结果,以及对实际生产过程的优化效果。这样,燃烧多目标优化数学模型不仅可以被有效地应用于实际生产过程,还可以为运行人员提供直观的指导,提高燃烧过程的控制精度。
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error, r2_score
from sklearn.model_selection import train_test_split
from geneticalgorithm import geneticalgorithm as ga
# 数据预处理
def preprocess_data(data, target_column):
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
X, y = [], []
for i in range(60, len(scaled_data)):
X.append(scaled_data[i-60:i])
y.append(scaled_data[i, target_column])
return np.array(X), np.array(y), scaler
# 构建LSTM模型
def create_lstm_model(input_shape):
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=input_shape))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
return model
# 遗传算法优化
def ga_optimize(params):
units, batch_size, epochs = params
model = Sequential()
model.add(LSTM(units=int(units), return_sequences=True, input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(LSTM(units=int(units), return_sequences=False))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(X_train, y_train, epochs=int(epochs), batch_size=int(batch_size), verbose=0)
predictions = model.predict(X_test)
return mean_squared_error(y_test, predictions)
# 读取数据
data = pd.read_csv('boiler_data.csv')
X, y, scaler = preprocess_data(data.values, target_column=0)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 遗传算法参数
algorithm_param = {'max_num_iteration': 30,
'population_size': 10,
'mutation_probability': 0.1,
'elit_ratio': 0.01,
'crossover_probability': 0.5,
'parents_portion': 0.3,
'crossover_type':'uniform',
'max_iteration_without_improv':10}
model = ga(function=ga_optimize, dimension=3, variable_type='int', variable_boundaries=np.array([[20, 100], [16, 64], [10, 100]]), algorithm_parameters=algorithm_param)
model.run()
# 获取最优参数
best_params = model.output_dict['variable']
units, batch_size, epochs = best_params
# 使用最优参数训练模型
lstm_model = create_lstm_model((X_train.shape[1], X_train.shape[2]))
lstm_model.fit(X_train, y_train, epochs=int(epochs), batch_size=int(batch_size), verbose=1)
# 预测与评估
predictions = lstm_model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, predictions))
mape = mean_absolute_percentage_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'RMSE: {rmse}')
print(f'MAPE: {mape}')
print(f'R^2: {r2}')


















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











