






前言:
前面讲的都是线性降维,本篇主要讨论一下非线性降维.
流形学习(mainfold learning)是一类借鉴了拓扑流行概念的降维方法.

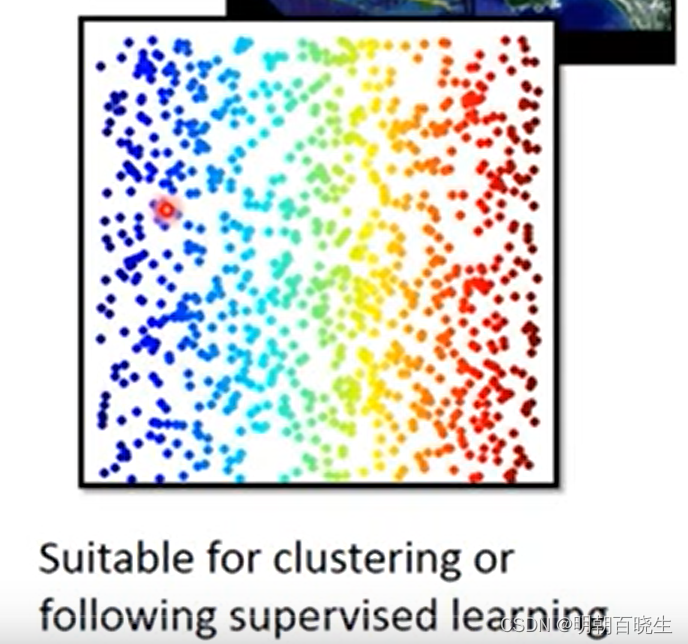
如上图,欧式距离上面 A 点跟C点更近,距离B 点较远
但是从图形拓扑结构来看, B 点跟A点更近
目录:
- LLE 简介
- 高维线性重构
- 低维投影
- Python 例子
一 局部线性嵌入(LLE Locally Linear Embedding )
局部线性嵌入(Locally Linear Embedding,以下简称LLE)也是非常重要的降维方法。和传统的PCA,LDA等关注样本方差的降维方法相比,LLE关注于降维时保持样本局部的线性特征,由于LLE在降维时保持了样本的局部特征,它广泛的用于图像图像识别,高维数据可视化等领域。下面我们就对LLE的原理做一个总结。
1.1 LLE 思想
比如我们有一个样本 我们在它的原始高维邻域里用K-近邻算法(k=3)找到和它最近的三个样本
然后我们假设
可以由
线性表示,即:
,
为权重系数。
在我们通过LLE降维后,我们希望 在低维空间对应的投影
′和
对应的投影
也尽量保持同样的线性关系,即
LLE算法的主要优点有:
1)可以学习任意维的局部线性的低维流形
2)算法归结为稀疏矩阵特征分解,计算复杂度相对较小,实现容易。
LLE算法的主要缺点有:
1)算法所学习的流形只能是不闭合的,且样本集是稠密均匀的。
2)算法对最近邻样本数的选择敏感,不同的最近邻数对最后的降维结果有很大影响。

二 高维线性重构
设有m个n维的样本
使用均方差作为损失函数
其中:
: 按照欧式距离作为度量, 计算和样本点
最近的的k个最近邻
: 权重系数为标量,
则
例:

设
(对称矩阵)
则:
加上约束条件
其中
k行全1的列向量
现在我们将矩阵化的两个式子用拉格朗日子乘法合为一个优化目标:
对求导并令其值为0,我们得到
(前半部分 利用了
的对称性简化了)
(公式1)
(公式2)
公式2的解原理
由约束条件:
已知:
则
重新带入公式1 ,即得到公式2
三 低维投影
我们得到了高维的权重系数W,那么我们希望这些权重系数对应的线性关系在降维后的低维一样得到保持。假设我们的n维样本集{}在低维的d维度对应投影为{
}, 则我们希望保持线性关系,也就是希望对应的均方差损失函数最小,即最小化损失函数J(Y)如下:
注意:
低维的损失函数中: 权重系数W已知,目标是求最小值对应的数据z
W: 是[m,m]矩阵,我们将那些不在邻域位置的的位置取值为0,将W扩充到m×m维度。
一般我们也会加入约束条件如下:
: 单位矩阵
3.1 原理推导
损失函数为
(步骤一)
备注: 步骤一原理
其中
为m 行一列的列向量
下面一步推导用到了该知识:
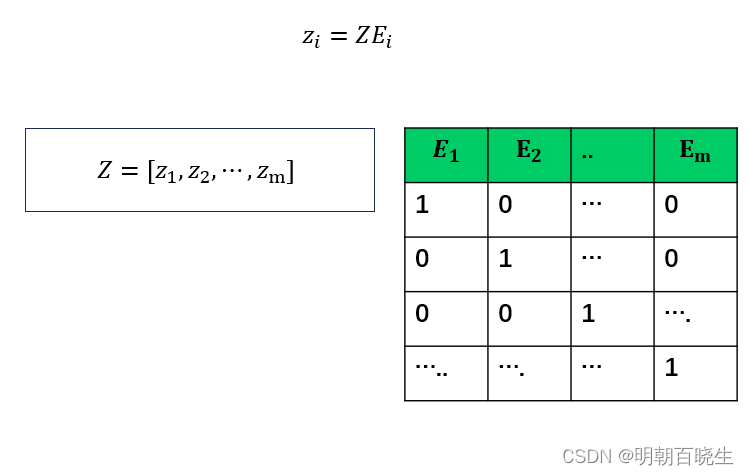

设
加上约束条件,得到拉格朗日函数
对Z 求微分
要得到最小的d维数据集,我们需要求出矩阵M最小的d个特征值所对应的d个特征向量组成的矩阵
由于M的最小特征值为0不能反应数据特征,此时对应的特征向量为全1。我们通常选择M的第2个到第d+1个最小的特征值对应的特征向量
2.2 为什么M的最小特征值为0呢?
前面知道约束条件: ,
(注意大E和小e 不一样,前面是单位矩阵,后面是全1的列向量)
所以最小的特征值为0,对应的特征向量为全1的列向量。
把该最小特征值丢弃
四 Python 例子
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 7 17:02:55 2024
@author: chengxf2
"""
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import manifold, datasets
from sklearn.utils import check_random_state
def generateData(m = 500):
random_state = check_random_state(0)
p = random_state.rand(m) * (2 * np.pi - 0.55)
t = random_state.rand(m) * np.pi
# 让球体不闭合,符合流形定义
indices = ((t < (np.pi - (np.pi / 8))) & (t > ((np.pi / 8))))
colors = p[indices]
x, y, z = np.sin(t[indices]) * np.cos(p[indices]), \
np.sin(t[indices]) * np.sin(p[indices]), \
np.cos(t[indices])
fig = plt.figure()
ax = Axes3D(fig, elev=30, azim=-20,auto_add_to_figure=False)
fig.add_axes(ax)
ax.scatter(x, y, z, c=p[indices], marker='o', cmap=plt.cm.rainbow)
plt.show()
return x,y,z,colors
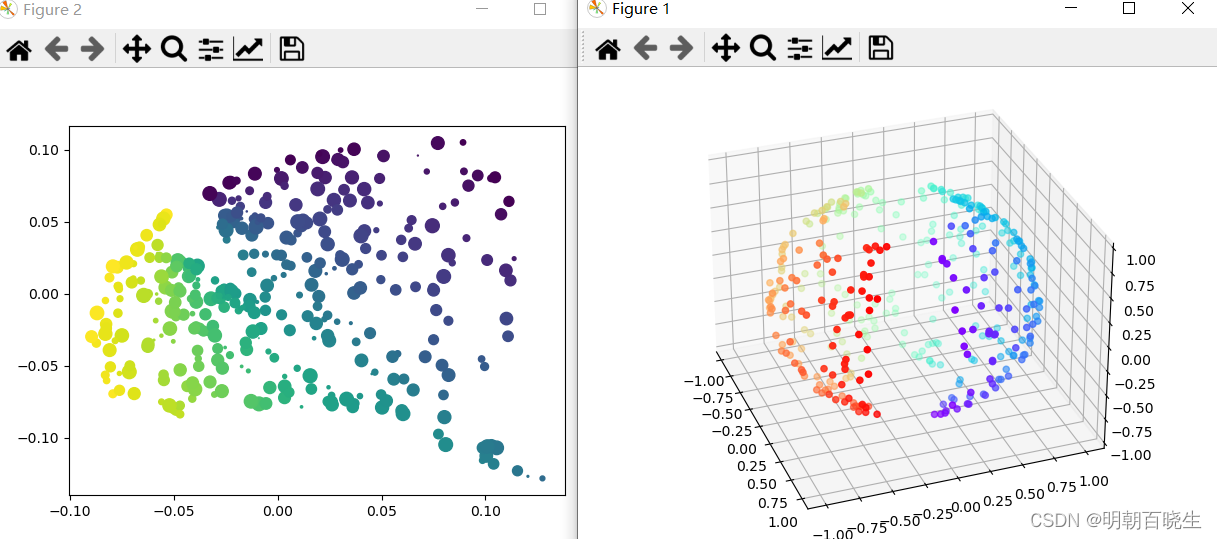
def LLE():
x,y,z,colors= generateData()
train_data = np.array([x,y,z]).T
print("\n 高维空间shape",np.shape(train_data))
#n_neighbors: 高维空间K邻近选择的点个数
#n_components:低维空间的维度
#[362,2]
trans_data = manifold.LocallyLinearEmbedding(n_neighbors =10, n_components = 2,
method='standard').fit_transform(train_data)
print("\n 低维空间shape",np.shape(trans_data))
size = np.random.rand(363)*100
fig = plt.figure()
plt.scatter(trans_data[:, 0], trans_data[:, 1],s=size, marker='o',c=colors)
LLE()
参考:
15: Unsupervised Learning - Neighbor Embedding_哔哩哔哩_bilibili














 38万+
38万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









