






1.介绍
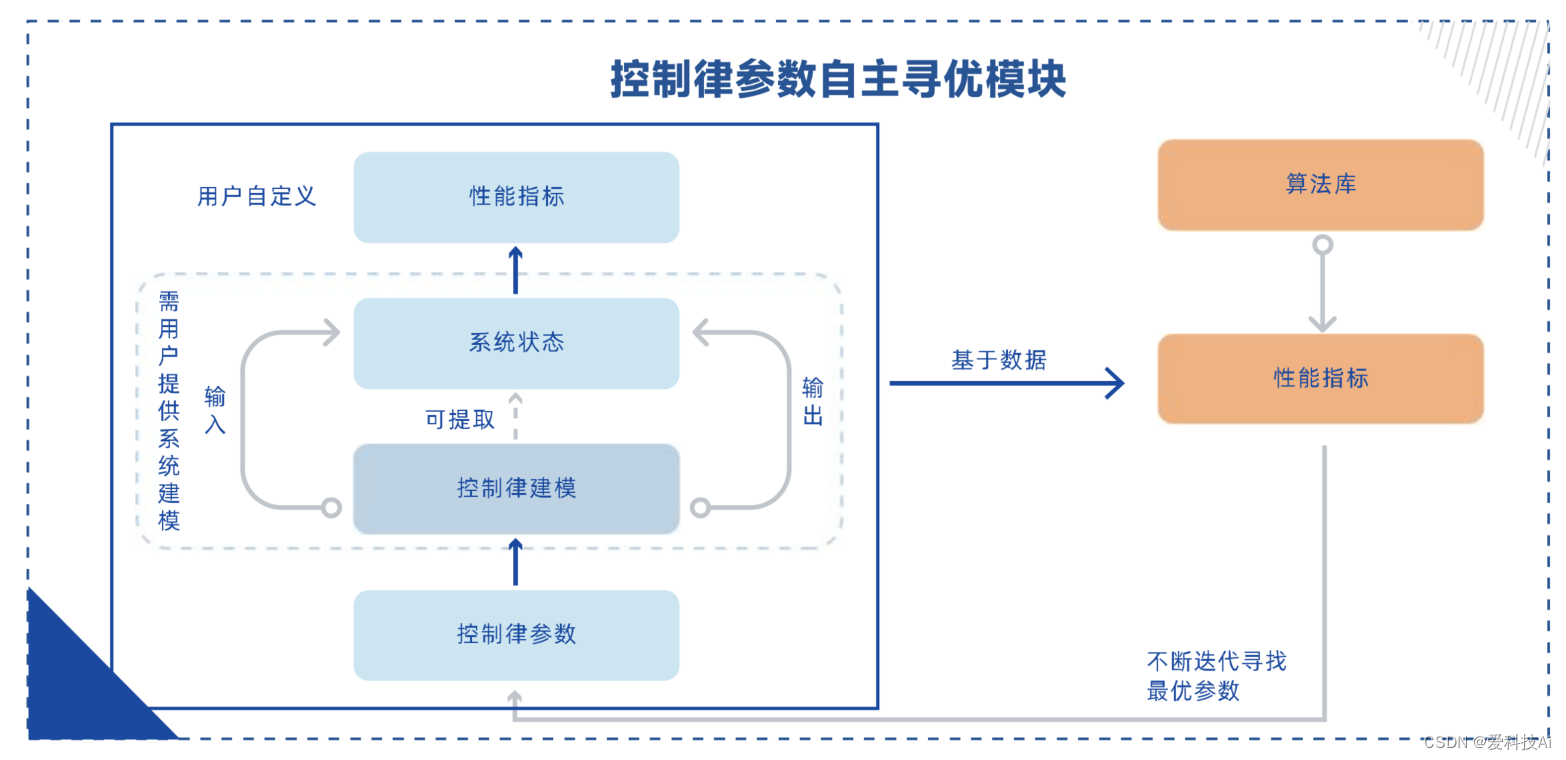
针对控制建模与设计场景中控制参数难以确定的普遍问题,提出了一种基于强化学习的控制律参数自主优化解决方案。该方案以客户设计的控制律模型为基础,根据自定义的控制性能指标,自主搜索并确定最优的、可状态依赖的控制参数组合。
可用于各类飞行器、机器人等类的控制系统优化。无论是经典的PID控制,还是其他先进的控制方法,该模块都能提供一种通用的参数优化方案。通过与控制律参数自主优化模块的结合,工程师们将获得更多的精力用于控制策略的设计和算法的创新,而将繁琐的参数调试工作交给智能化优化系统完成。
2.应用场景
面向复杂系统的控制建模与控制律设计研发场景,适用于需要频繁进行控制律设计、控制律调整、控制参数调整的研发场景,包括各类机器人设计(机械臂、机械狗、特殊结构如水上水下机器人、拟人机器人等)、各类飞行器设计(固定翼、四旋翼、航天器等)、其他机械设施(汽车、发动机等)。
3.参考示例-基于强化学习的PID参数整定
在控制系统控制器性能分析中,系统阶跃响应对应的超调量、上升时间、调节时间等动态性能指标是关于控制器参数矢量 X 的非线性函数,评价控制器设计优劣的关键性因素。
结合强化学习理论和控制理论知识,设计一种基于强化学习(reinforcement learning, RL)的控制器参数自整定及优化算法。算法将控制参数矢量 X作为智能体的动作,控制系统的响应结果作为状态,引入动态性能指标计算奖励函数,通过在线学习周期性阶跃响应数据、梯度更新控制器参数的方式改变控制器的控制策略,直至满足优化目标,实现参数的自整定及优化。算法原理如下图所示。
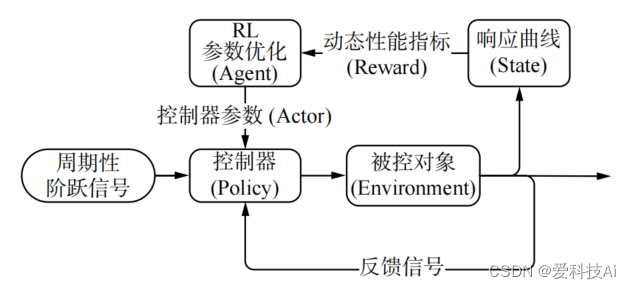
根据原理图,参数自整定及优化算法将控制器参数整定问题定义为,求解满足下列不等式约束条件的可行解:
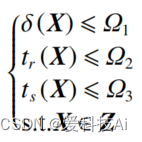
式中: Z为待优化的参数矢量X的取值范围;Ωi(i=1,2,3) 为优化目标的约束值。基于控制系统动态性能指标超调量 δ、上升时间 tr、调节时间 ts,算法定义奖励函数为
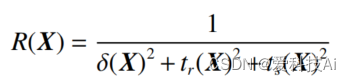
算法的参数整定及优化流程如下:
- 根据实际条件和需求设定优化目标 Ωi和参数 X的搜索范围 Z,随机初始化参数 X;
- 返回步骤 2),重复上述步骤。
- 利用梯度下降法更新参数;X=X+α⋅∇X+σ,其中 σ为高斯白噪声,α为自适应学习率;
- 计算 m个样本的参数平均梯度 ∇X;
- 从经验回放集 S 中随机批量抽取 m 个经验样本,将 2) 中数据存入经验回放集 S;
- 获得系统在参数 X下的周期阶跃响应数据,计算动态性能指标 δ、tr 、ts和奖励函数 R;若满足优化目标,则终止迭代,输出参数 X;
为了尽可能获得全局最优的参数,参数自整定及优化算法在更新参数的过程中引入高斯白噪声,增加参数的探索度。同时,算法利用经验回放技术,对过去的经验样本进行随机批量抽样,减弱经验数据的相关性和不平稳分布的影响,增加优化过程的准确性和收敛速度。实践试验中,为避免算法陷入局部死循环,当可行解的变异系数小于一定阈值时,即认为算法已获得局部收敛(近似全局)的相对最优解,保留当前结果并重新搜索。
案例参考自:

















 2565
2565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









