









Today I intend to discuss gradient explosion and vanishing issues. 🧐
1. An intuitive understanding of what gradient explosion and gradient disappearance are. 🤔
You and I know about when the person who does more things than yesterday and develops himself can get crazy successful. I want to organize this thing to map with math.
what is the 0.99 to 100th power and 1.1 to 100th power?
(0.99 ** 100 = 0.3660323413) And (1.1 ** 100 = 13,780.6123398223) What a big difference! 🤠 If you know anything about calculus, you know that if you multiply successively by a number greater than 1 you will get close to infinity (Gradient exploding), and conversely multiplying by a number less than 1 you will get close to 0 (Gradient vanishing).
2. Why the neural network should multiply successively by a number? (Causes gradient vanishing and gradient explosion.🤨)
When we train a neural network, it involves chain rule and gradient descent (All of these require multiplication).😭 Usually, the neural network we are about to train will almost always contain nonlinear activation functions (sigmoid, tanh, etc.).
This ‘sigmoid’ graph is from here.
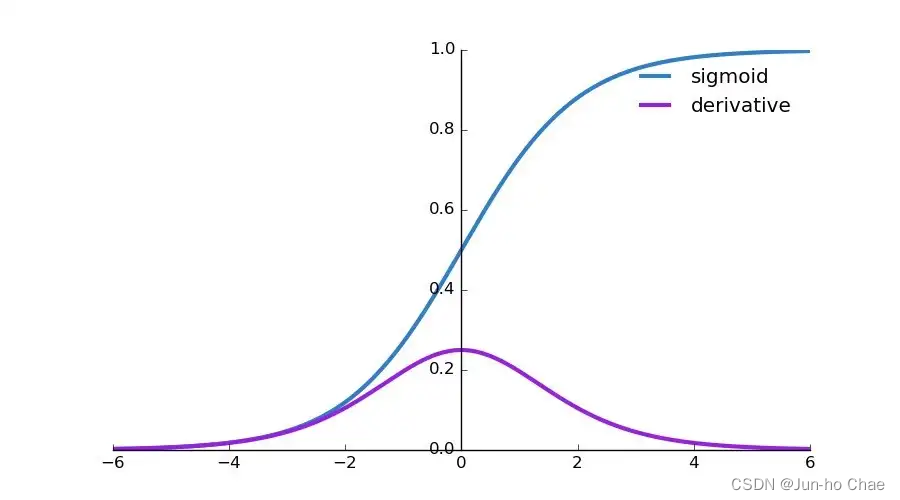
This ‘tanh’ graph is from here.
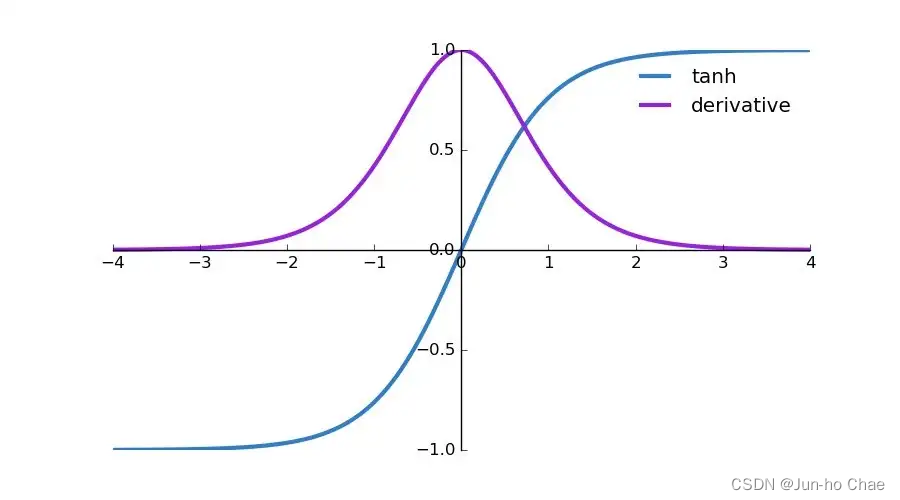
This ‘ReLu’ graph is from here.

Based on the three graphs above, I can conclude that there is a risk of gradient vanishing if the sigmoid function and the tanh function are used. Because their values are less than 1, but the ReLu function is an exception.🥲
3. How do I solve the gradient explosion? 🤕(Gradient clipping)
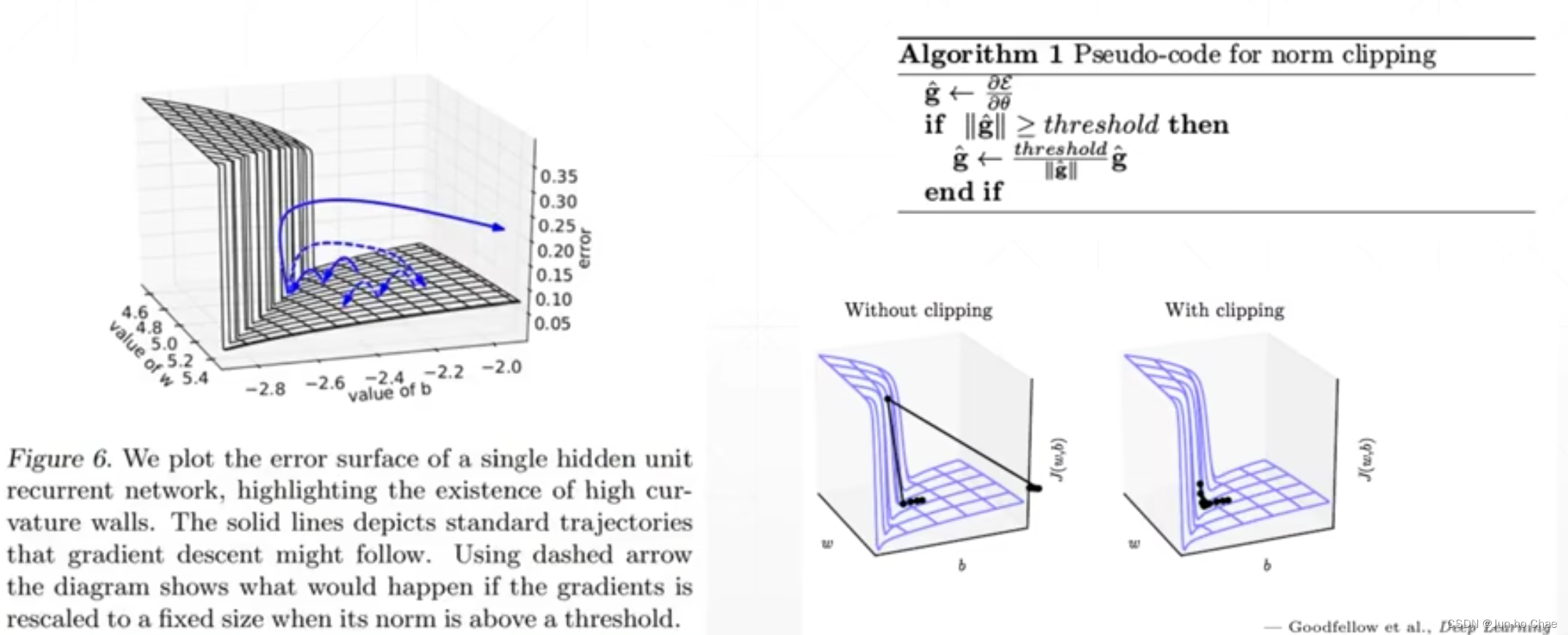
I will choose to use gradient clipping. first, I will set a gradient threshold, suppose it is set to 15. after that, I need to check the gradient of weight, if this gradient is greater than 15, I will process it according to the formula in the picture above. In detail, I will divide the tensor of the current gradient by the norm of this tensor. According to this formula, we will get a tensor of size 1 and the same direction as before, and then multiply it by 15. The result is that we can constrain it to 15. Because the direction represents the direction of gradient descent and the norm represents the length of the step. 🤗
How do I use gradient clipping in PyTorch? 🤠
loss = criterion(output, y)
model.zero_grad()
loss.backward()
for p in model.parameters():
print(p.grad.norm())
torch.nn.utils.clip_grad_norm(p, max_norm=10)
optimizer.step()
4. List some solutions that can mitigate gradient explosion and gradient vanishing. 🧐
- Gradient clipping.
- Weight decay.
optimizer = optim.Adam(model.parameters(),lr=0.05,weight_decay=0.01)
- Batchnorm: The distribution of the input values of the neurons in the backpropagation is changed to a standard normal distribution with a mean of 0 and a variance of 1. This treatment leads to a large change in the loss function, which makes the gradient larger and avoids the gradient disappearance problem.
- Use activation functions such as ReLu, ELu, etc.
- Shortcut
- Some neural networks with “gates”. (LSTM, GRU, etc.)
- Appropriate control of the number of layers of the neural network.
- And so on…
Complete Code
import numpy as np
import torch
from torch import nn
import torch.optim as optim
from matplotlib import pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
num_time_steps = 50
input_size = 1
hidden_size = 16
output_size = 1
lr = 0.01
class Net(nn.Module):
def __init__(self)-> None:
super().__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True,
)
for p in self. rnn.parameters():
nn.init.normal_(p, mean=0.0, std=0.001)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev)
# [1, seq, h] => [seq, h]
out = out.view(-1, hidden_size)
out = self.linear(out) # [seq, h] => [seq, 1]
out = out.unsqueeze(dim=0) # => [1, seq, 1]
return out, hidden_prev
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)
hidden_prev = torch.zeros(1, 1, hidden_size)
for iter in range(6000):
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start+10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps -1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps -1, 1)
output, hidden_prev = model(x, hidden_prev)
hidden_prev = hidden_prev.detach()
loss = criterion(output, y)
model.zero_grad()
loss.backward()
for p in model.parameters():
print(p.grad.norm())
torch.nn.utils.clip_grad_norm(p, max_norm=10)
optimizer.step()
if iter % 100 ==0:
print(f"Iteration:{iter} loss{loss.item()}")
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):
input = input.view(1, 1, 1)
(pred, hidden_prev) = model(input, hidden_prev)
input = pred
predictions.append(pred.detach().numpy().ravel()[0])
x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x.ravel(), s=90)
plt.plot(time_steps[:-1], x.ravel())
plt.scatter(time_steps[1:], predictions)
plt.show()
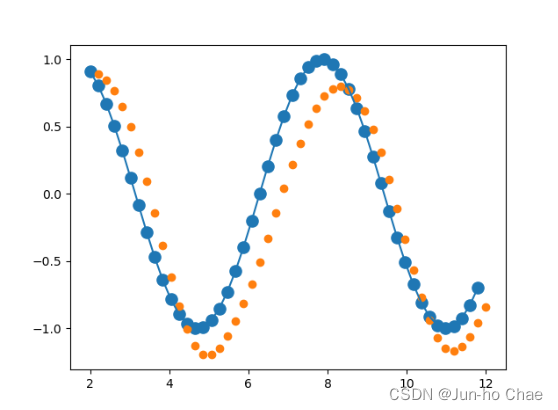
Finally 🤩
Thank you for the current age of knowledge sharing and the people willing to share it, thank you! The knowledge on this blog is what I’ve learned on this site, thanks for the support! 😇


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











