







sklearn安装
在linux或windows终端输入
pip3 install Scikit-learn安装较慢则替换源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple以下内容会用到sklearn的API接口,官网:https://scikit-learn.org/stable/modules/classes.html
字典特征提取
sklearn可对字典进行特征值化,如对一组人体数据进行特征值化。
本例使用到了sklearn的API接口:sklearn.feature_extraction.DictVectorizer
from sklearn.feature_extraction import DictVectorizer
def dictVetor():
dict=DictVectorizer()
data=dict.fit_transform([{'身高':180,'体重':160,'头发长度':'short'},
{'身高':170,'体重':120,'头发长度':'short'},
{'身高':165,'体重':100,'头发长度':'long'}])
print(dict.get_feature_names())
print(data)
if __name__=="__main__":
dictVetor()打印出的结果为scipy提供的sparse稀疏矩阵,初看似乎看不出任何意义,下面看一下另一种输出格式
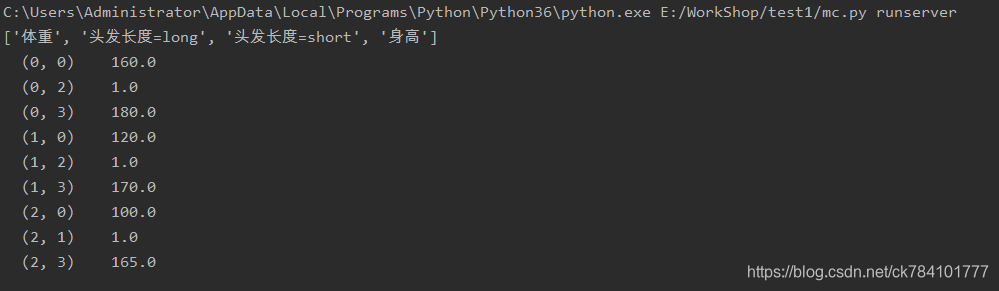
将程序中dict=DictVectorizer()添加一个参数,dict=DictVectorizer(sparse=False),sparase=False将输出numpy的ndarray矩阵
这样看上去似乎清楚多了,DictVectorizer提取4个特征值,体重,头发长度=long,头发长度=short,身高
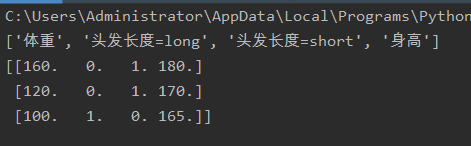
输出一个3*4的二维矩阵,3行对应我们提供的字典变量里的三组值,4列对应四个特征,第一行输出体重,第二行输出0/1,0代表不是长发,1代表是长发,第三行与第二行同质,第四行输出身高
而头发长度=long,头发长度=short为什么要以01来表示,实际上是为了解决内存空间,我们把它称为one-hot编码
意义何在?
进行字典特征提取的意义在与,其本质通过分析特征来判断一个目标值,以上面的例子来讲,若体重较重,头发为短发,身高较高的一组数据,就更加符合男性的特征,那么它的目标值就应该为男性,反正升高较矮,体重较轻,头发长度为长发的一组值就更加符合女性的特征。
文本特征提取
文本特征提取是指对文本数据进行特征值化,如以下这个实例,对一段文字进行特征值化,将文本数据转换为特征值,并统计出现的次数。
本例使用到了sklearn的API接口:sklearn.feature_extraction.text.CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vector = CountVectorizer()
res=vector.fit_transform(["Sklearn is simple and efficient tools for predictive data analysis,"
"Accessible to everybody, "
"and reusable in various contexts,"
"Built on NumPy, SciPy, and matplotlib,"
"Open source, commercially usable - BSD license"])
print(vector.get_feature_names())
print(res.toarray())
对文本中出现的每一个单词进行了小写转化并输出个数。
 意义何在?
意义何在?
进行文本特征提取的意义何在呢?试想一下,对一段文字,我们通过特征提取出每个单词出现的次数,计算出在总单词中的占比,就可以对该篇文章的内容进行预测 ,比如出现较多的科技词汇,那么改变文章偏向于科技读物类,若出现较多情感词汇,那么就偏向于情感类读物,依次推类。
补充:中文文本提取思路
中文文本不同与英文文本,因为英文每个单词间有空格,非常适合提取,而中文的一段话是没有空格的,使用sklearn直接进行提取会得到比较奇怪的特征值,所以我们需要先对中文文本进行分词,这里推荐一个库,库名为jieba,下面来看看使用效果。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction import DictVectorizer
import jieba
vector = CountVectorizer()
#jieba默认返回迭代器对象,需转换为列表后再转换为字符串
c1=jieba.cut("男性,身高一米八,短头发,喜欢打球")
c2=jieba.cut("男性,身高一米七,短头发,喜欢唱歌")
c3=jieba.cut("女性,身高一米六,长头发,喜欢逛淘宝")
l1=list(c1)
l2=list(c2)
l3=list(c3)
str1="".join(l1)
str2="".join(l2)
str3="".join(l3)
res=vector.fit_transform([str1,str2,str3])
print(vector.get_feature_names())
print(res.toarray())
参考文档:
特征提取的目的:https://cloud.tencent.com/developer/news/369843
one-hot编码:https://juejin.im/post/5d15840e5188255c23553204
稀疏矩阵库scipy.sparse:https://blog.csdn.net/pipisorry/article/details/41762945
numpy ndarray:https://danzhuibing.github.io/py_numpy_ndarray.html

















 2902
2902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









