







https://baijiahao.baidu.com/s?id=1678519457206249337&wfr=spider&for=pc
GCN是一种卷积神经网络,它可以直接在图上工作,并利用图的结构信息。
GCN的基本思路:对于每个节点,我们从它的所有邻居节点处获取其特征信息,当然也包括它自身的特征。假设我们使用average()函数。我们将对所有的节点进行同样的操作。最后,我们将这些计算得到的平均值输入到神经网络中。
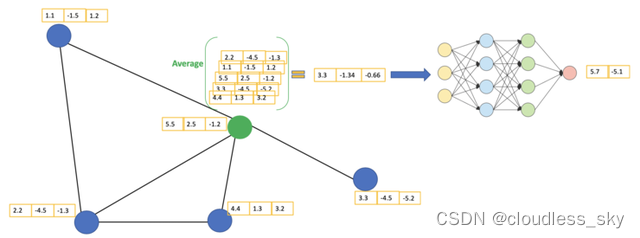
GCN的主要思想。我们以绿色节点为例。首先,我们取其所有邻居节点的平均值,包括自身节点。然后,将平均值通过神经网络。请注意,在GCN中,我们仅仅使用一个全连接层。在这个例子中,我们得到2维向量作为输出(全连接层的2个节点)。
在实际操作中,我们可以使用比average函数更复杂的聚合函数。我们还可以将更多的层叠加在一起,以获得更深的GCN。其中每一层的输出会被视为下一层的输入。这一层从邻居获得的信息也会传播到下一层,可想而知,当层数过多的时候,最后一层聚合了基本上全部点的信息,这是不好的。
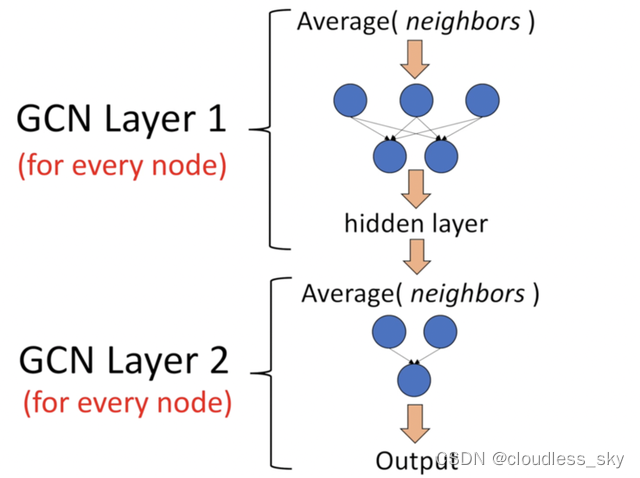
2层GCN的例子:第一层的输出是第二层的输入。同样,注意GCN中的神经网络仅仅是一个全连接层(图片来自[2])。
数学原理

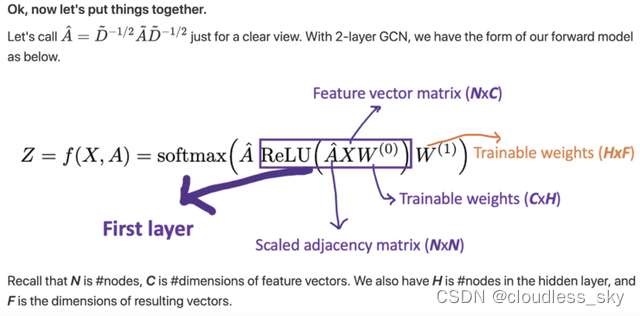
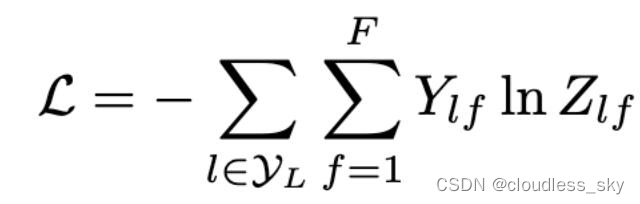
关于交叉熵的解释详见:https://wenku.baidu.com/view/81d0aef2900ef12d2af90242a8956bec0975a50e.html
简单来说就是,对于交叉熵损失函数,得到的预测值Z和标签Y越像,L就越小。

下面是更加详细直观的解释:
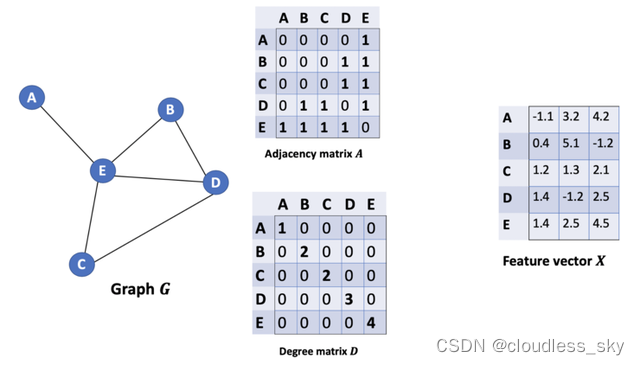
从图G中,我们有一个邻接矩阵A和一个度矩阵D。同时我们也有节点的特征矩阵X。
这里的邻接矩阵通常是通过节点之间的地理距离或者特征相似性计算出来的,或者通过随机初始化node embedding,然后经过正则化或者图传播后的损失函数反向传播自学习得到的。详见以下两篇博客的介绍:
https://nakaizura.blog.csdn.net/article/details/120995371
https://blog.csdn.net/qq_39388410/article/details/120997414
那么我们怎样才能从邻居节点处得到每一个节点的特征值呢?解决方法就在于A和X的相乘。
看看邻接矩阵的第一行,我们看到节点A与节点E之间有连接,得到的矩阵第一行就是与A相连接的E节点的特征向量(如下图)。同理,得到的矩阵的第二行是D和E的特征向量之和,通过这个方法,我们可以得到所有邻居节点的向量之和。
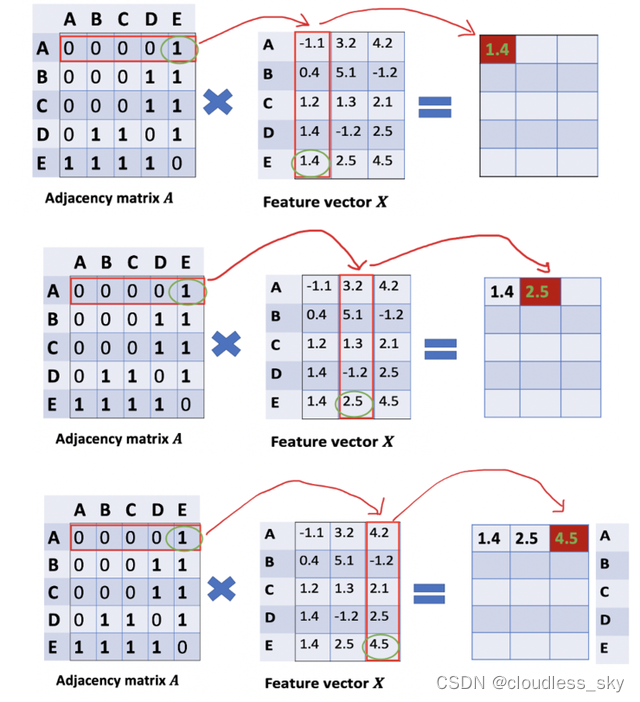
计算 "和向量矩阵 "AX的第一行。
这里还有一些需要改进的地方。
我们忽略了节点本身的特征。例如,计算得到的矩阵的第一行也应该包含节点A的特征。
我们不需要使用sum()函数,而是需要取平均值,甚至更好的邻居节点特征向量的加权平均值。那我们为什么不使用sum()函数呢?原因是在使用sum()函数时,度大的节点很可能会生成的大的v向量,而度低的节点往往会得到小的聚集向量,这可能会在以后造成梯度爆炸或梯度消失(例如,使用sigmoid时)。此外,神经网络似乎对输入数据的规模很敏感。因此,我们需要对这些向量进行归一化,以摆脱可能出现的问题。
在问题(1)中,我们可以通过在A中增加一个单位矩阵I来解决,得到一个新的邻接矩阵。
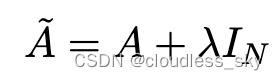
取lambda=1(使得节点本身的特征和邻居一样重要),我们就有=A+I,注意,我们可以把lambda当做一个可训练的参数,但现在只要把lambda赋值为1就可以了,即使在论文中,lambda也只是简单的赋值为1。
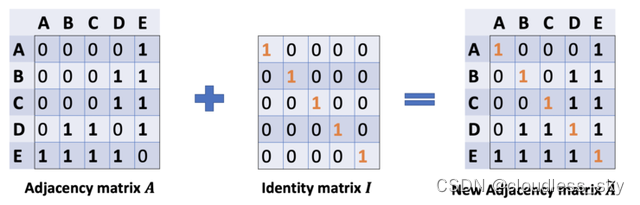
通过给每个节点增加一个自循环,我们得到新的邻接矩阵
对于问题(2): 对于矩阵缩放,我们通常将矩阵乘以对角线矩阵。在当前的情况下,我们要取聚合特征的平均值,或者从数学角度上说,要根据节点度数对聚合向量矩阵X进行缩放。直觉告诉我们这里用来缩放的对角矩阵是和度矩阵D有关的东西(为什么是D,而不是D?因为我们考虑的是新邻接矩阵 的度矩阵D,而不再是A了)。
现在的问题变成了我们要如何对和向量进行缩放/归一化?换句话说:
我们如何将邻居的信息传递给特定节点?我们从我们的老朋友average开始。在这种情况下,D的逆矩阵(即,D^{-1})就会用起作用。基本上,D的逆矩阵中的每个元素都是对角矩阵D中相应项的倒数。
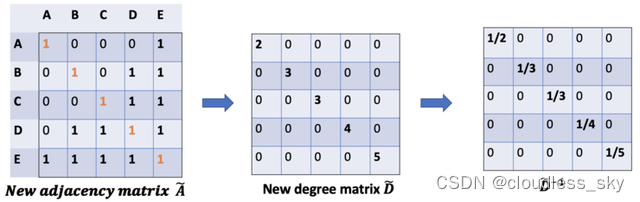
例如,节点A的度数为2,所以我们将节点A的聚合向量乘以1/2,而节点E的度数为5,我们应该将E的聚合向量乘以1/5,以此类推。
因此,通过D取反和X的乘法,我们可以取所有邻居节点的特征向量(包括自身节点)的平均值。
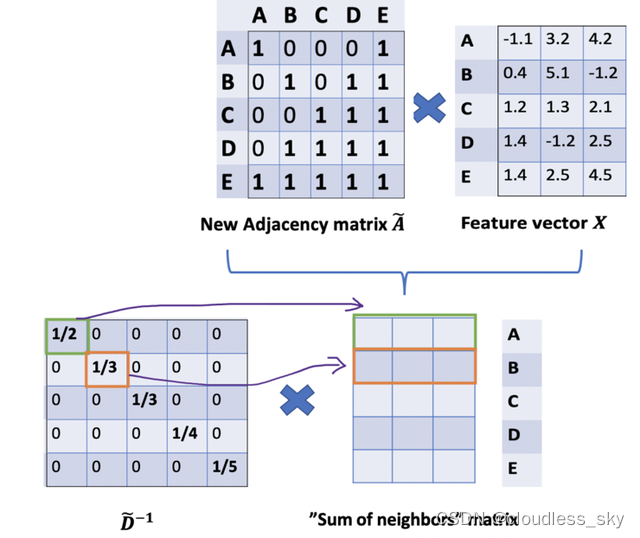
到目前为止一切都很好。但是你可能会问加权平均()怎么样?直觉上,如果我们对高低度的节点区别对待,应该会更好。
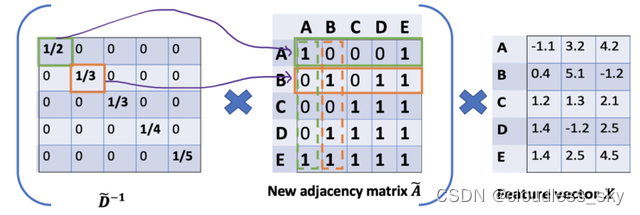
但我们只是按行缩放,但忽略了对应的列(虚线框)。
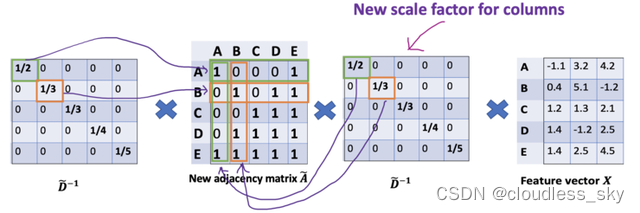
为列增加一个新的缩放器。
新的缩放方法给我们提供了 “加权 “的平均值。我们在这里做的是给低度的节点加更多的权重,以减少高度节点的影响。这个加权平均的想法是,我们假设低度节点会对邻居节点产生更大的影响,而高度节点则会产生较低的影响,因为它们的影响力分散在太多的邻居节点上。
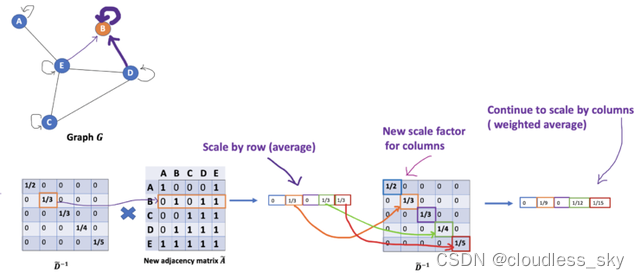
在节点B处聚合邻接节点特征时,我们为节点B本身分配最大的权重(度数为3),为节点E分配最小的权重(度数为5)。

因为我们归一化了两次,所以将”-1 “改为”-1/2”
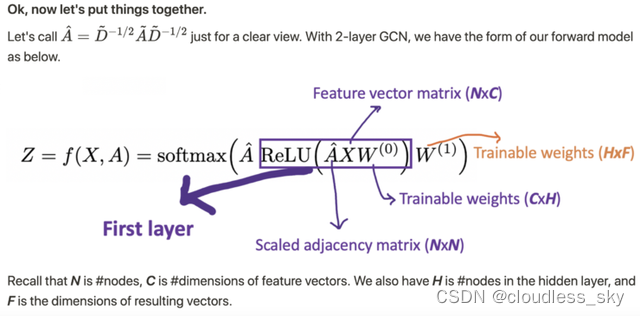
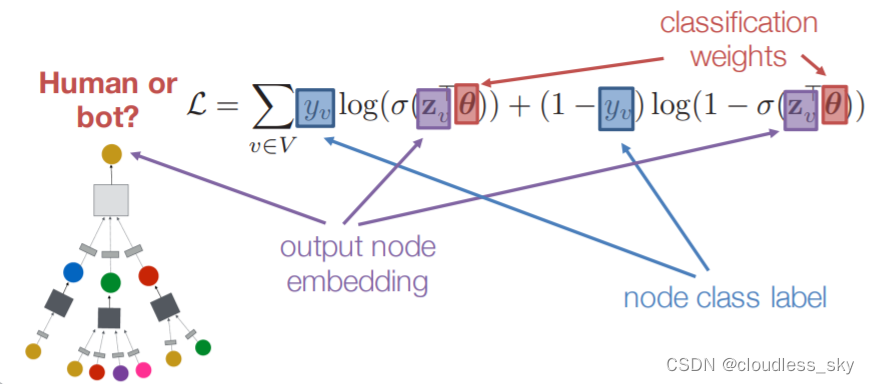
例如,我们有一个多分类问题,有10个类,F 被设置为10。在第2层有了10个维度的向量后,我们将这些向量通过一个softmax函数进行预测。
Loss函数的计算方法很简单,就是通过对所有有标签的例子的交叉熵误差来计算,其中Y_{l}是有标签的节点的集合。
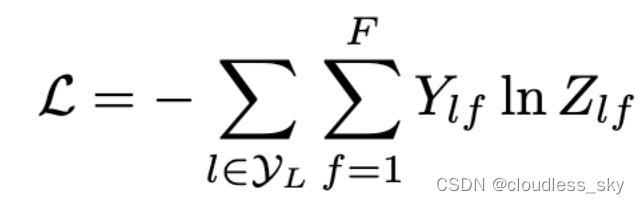
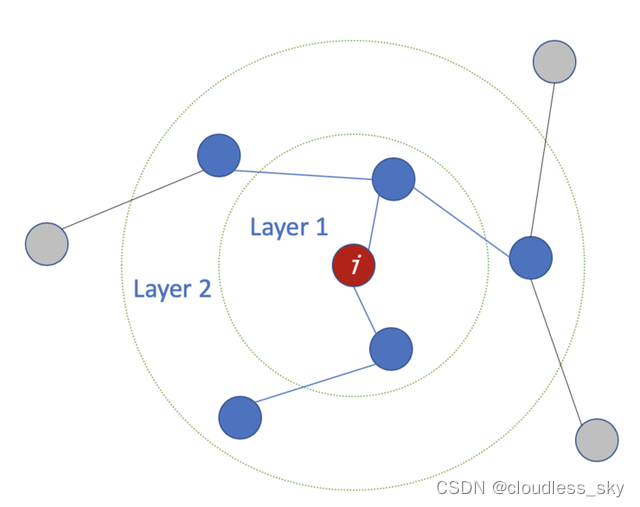
**层数是指节点特征能够传输的最远距离。**例如,在1层的GCN中,每个节点只能从其邻居那里获得信息。每个节点收集信息的过程是独立进行的,对所有节点来说都是在同一时间进行的。
当在第一层的基础上再叠加一层时,我们重复收集信息的过程,但这一次,邻居节点已经有了自己的邻居的信息(来自上一步)。这使得层数成为每个节点可以走的最大跳步。所以,这取决于我们认为一个节点应该从网络中获取多远的信息,我们可以为#layers设置一个合适的数字。但同样,在图中,通常我们不希望走得太远。设置为6-7跳,我们就几乎可以得到整个图,但是这就使得聚合的意义不大。
在论文中,作者还分别对浅层和深层的GCN进行了一些实验。在下图中,我们可以看到,使用2层或3层的模型可以得到最好的结果。此外,对于深层的GCN(超过7层),反而往往得到不好的性能(虚线蓝色)。一种解决方案是借助隐藏层之间的残余连接(紫色线)。
GNN 模型可以分为频谱域 (spectral domain) 和空间域 (spatial domain) 两大类:spectral 的方法通常利用了拉普拉斯矩阵,借助图谱的方式进行卷积操作;spatial 的方法通常使用更直接的方式聚合邻居节点的信息。以上是基于频谱域的。以下是空间域的,其实就是通过直接累加节点的邻域信息来实现图的卷积。
http://www.51blog.com/?p=11720

各种图 https://baijiahao.baidu.com/s?id=1686742016283743917&wfr=spider&for=pc
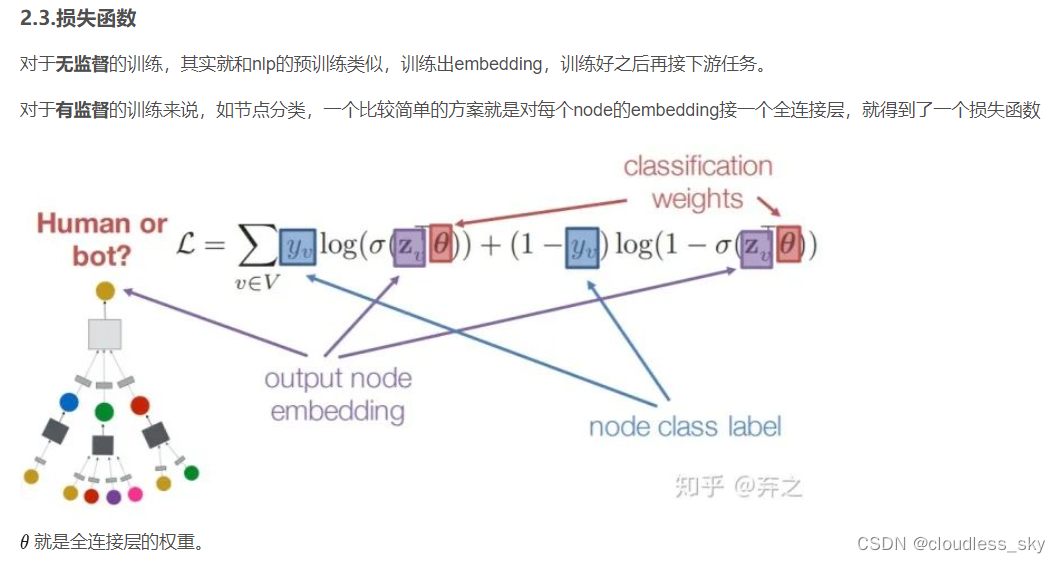
损失函数
有监督下的:直接用交叉熵之类的损失函数
无监督下的:基于Random walk, graph factorization之类的
https://zhuanlan.zhihu.com/p/150596886
https://blog.csdn.net/zandaoguang/article/details/111940065
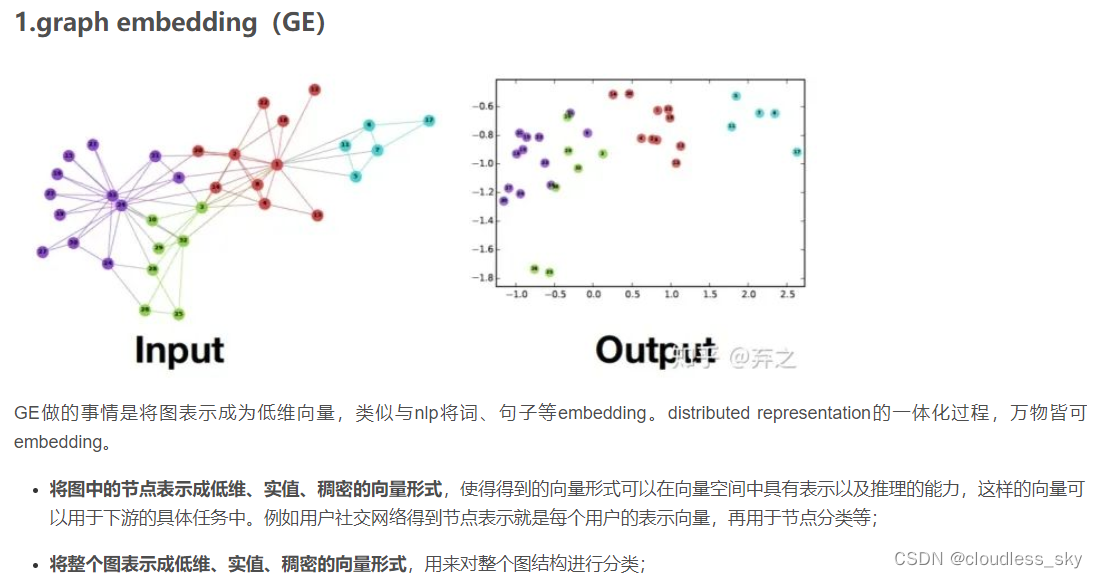


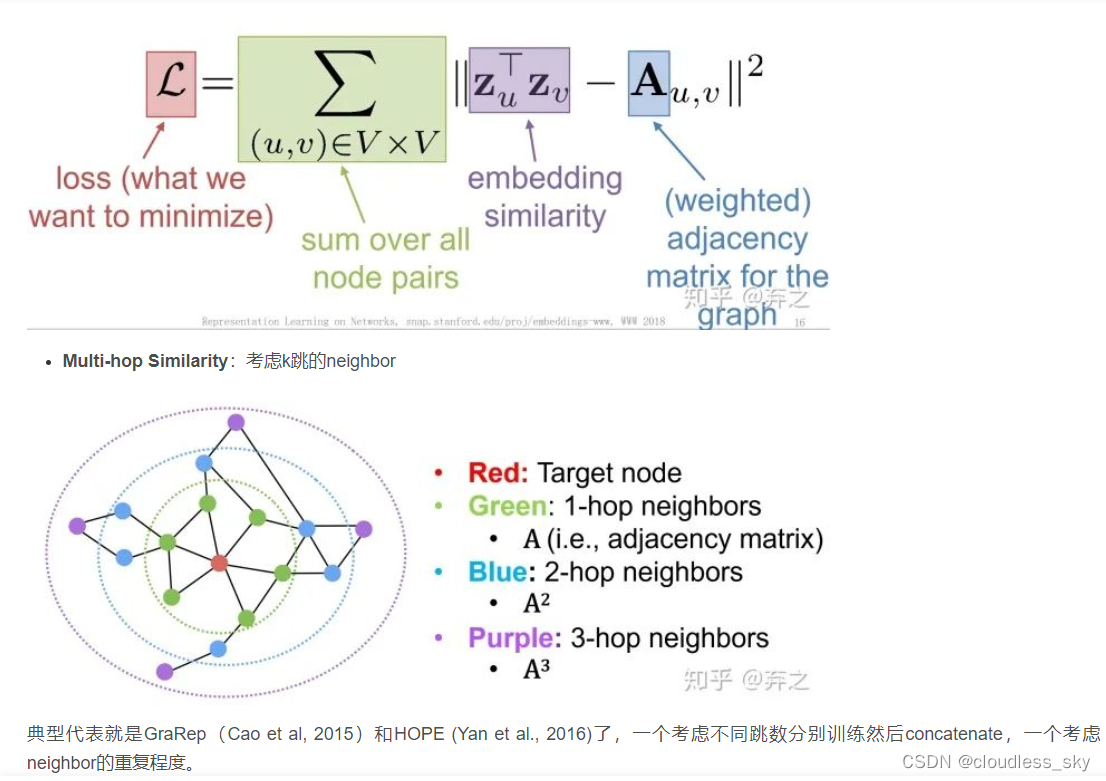

http://snap.stanford.edu/proj/embeddings-www/files/nrltutorial-part1-embeddings.pdf

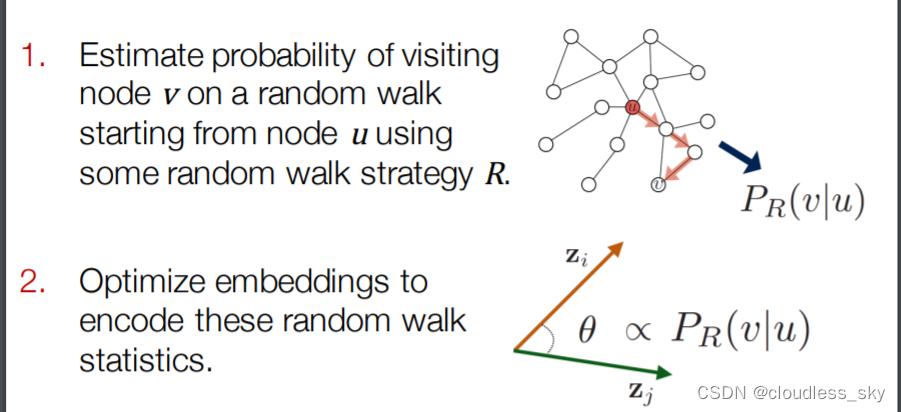





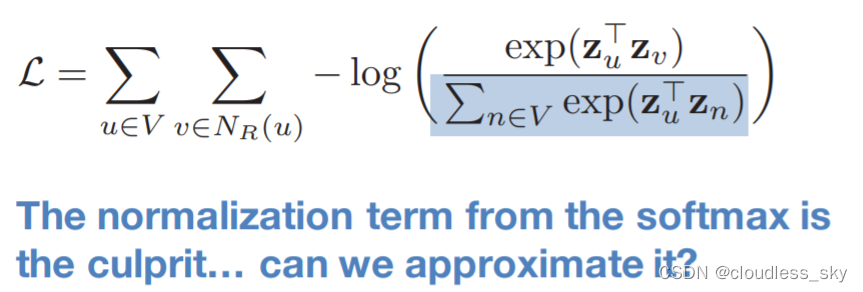




GNN如何训练模型得到好的node embedding?

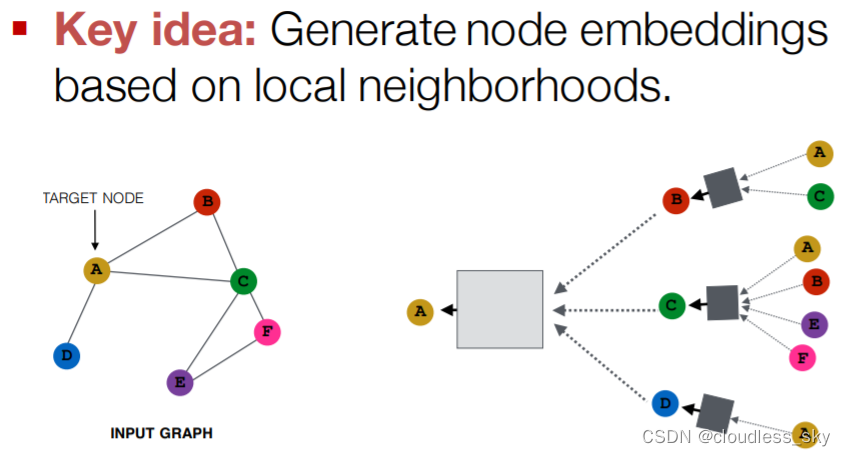
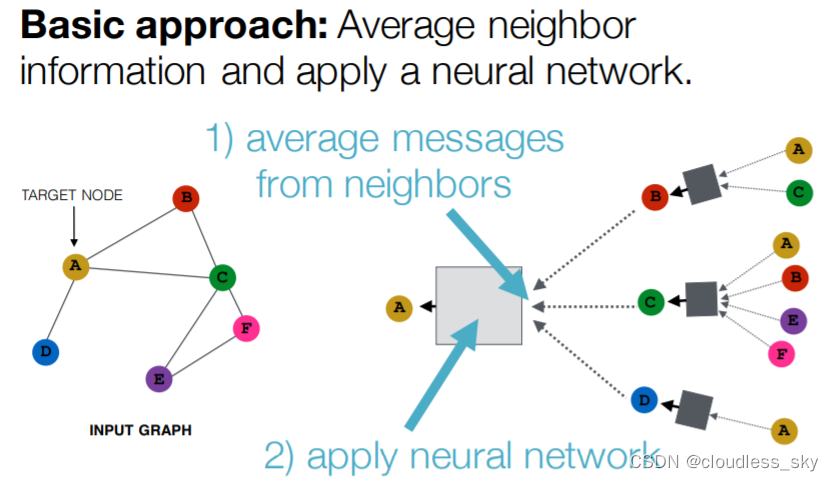
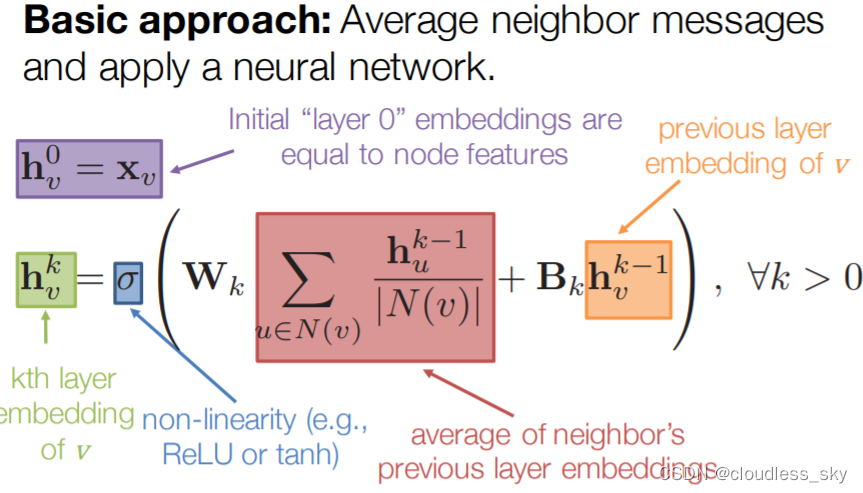
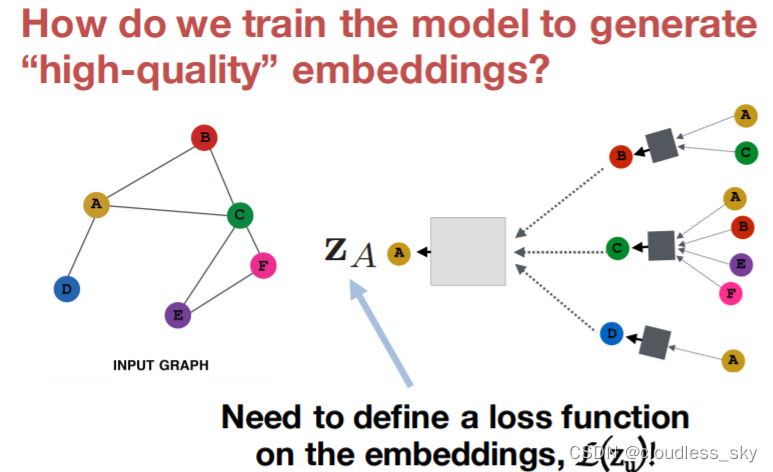
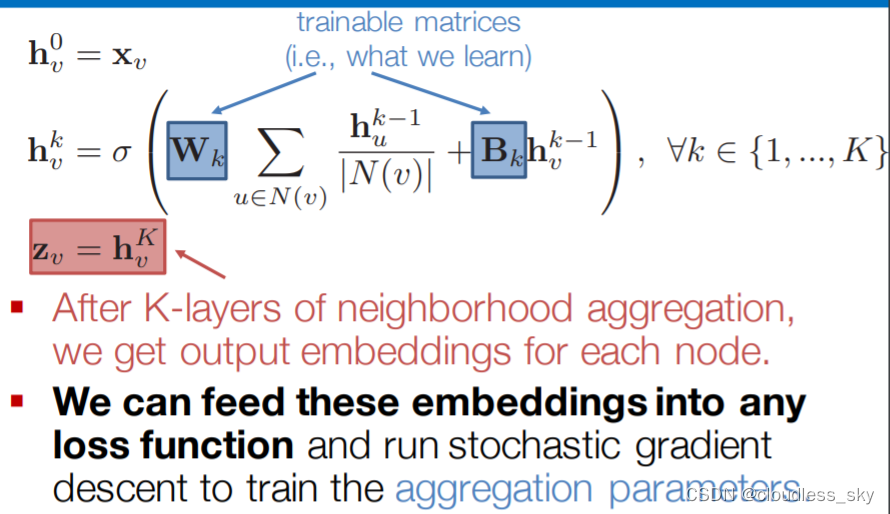
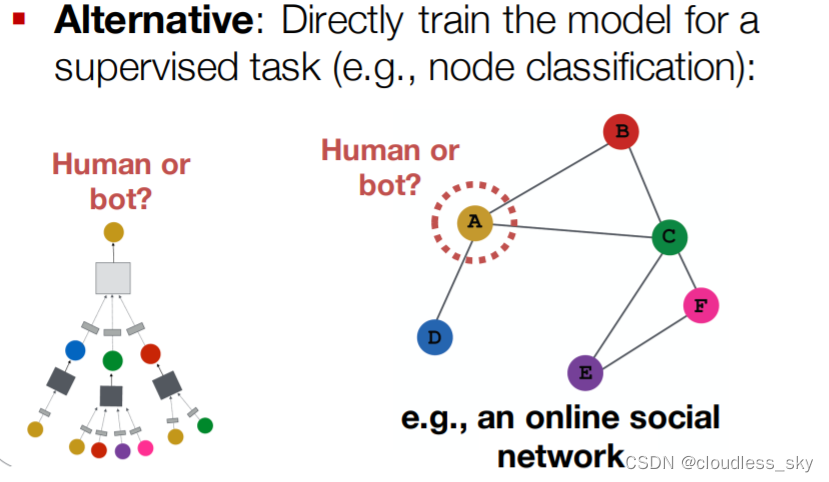
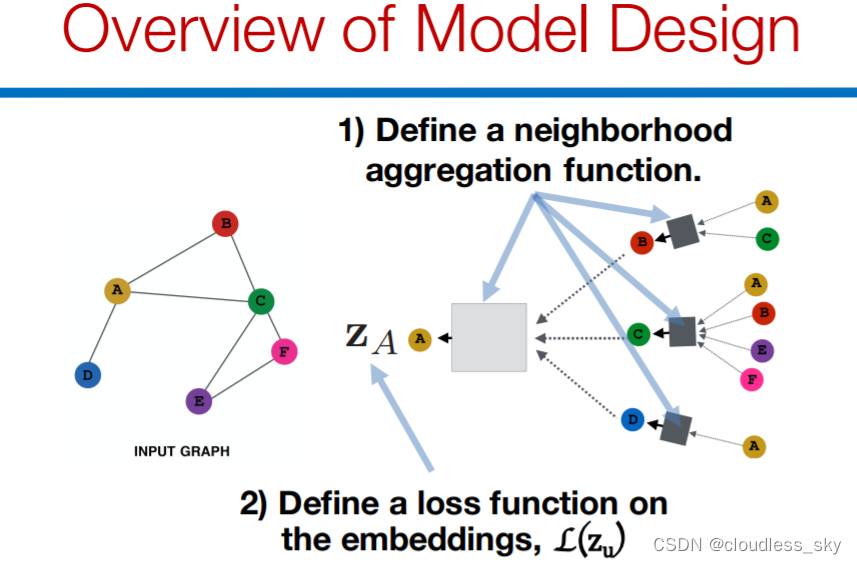
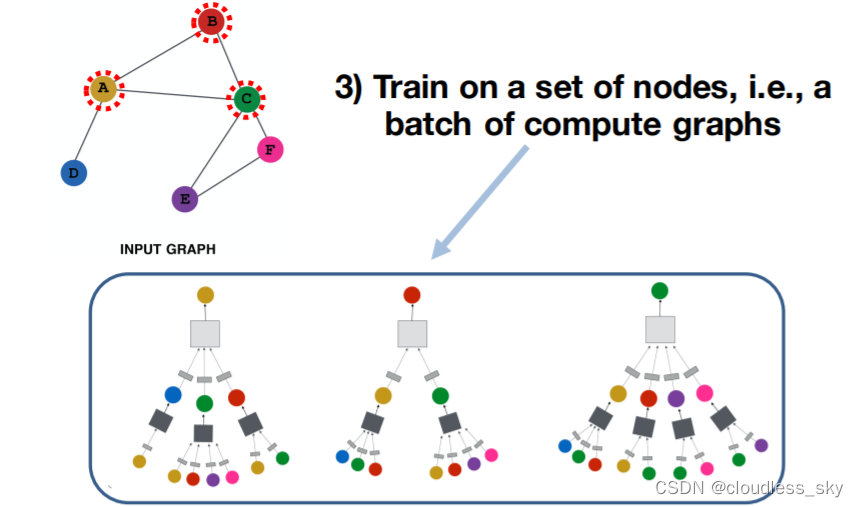
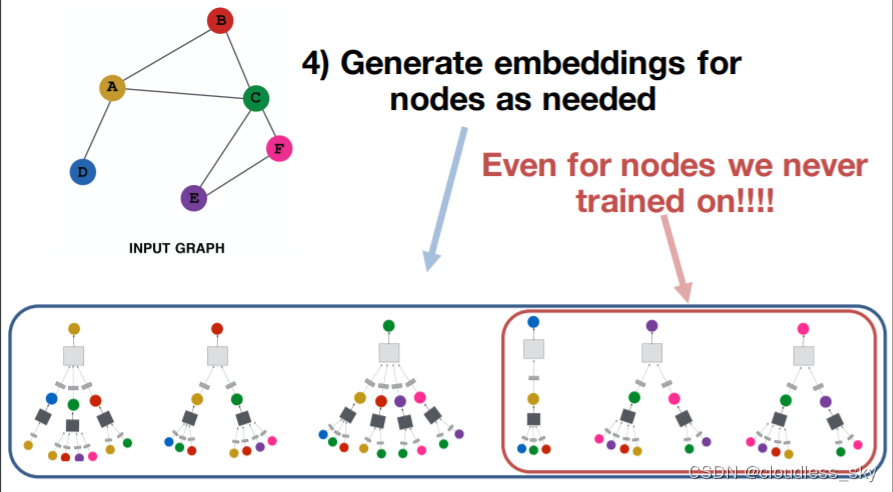
GAT
https://baijiahao.baidu.com/s?id=1671028964544884749&wfr=spider&for=pc
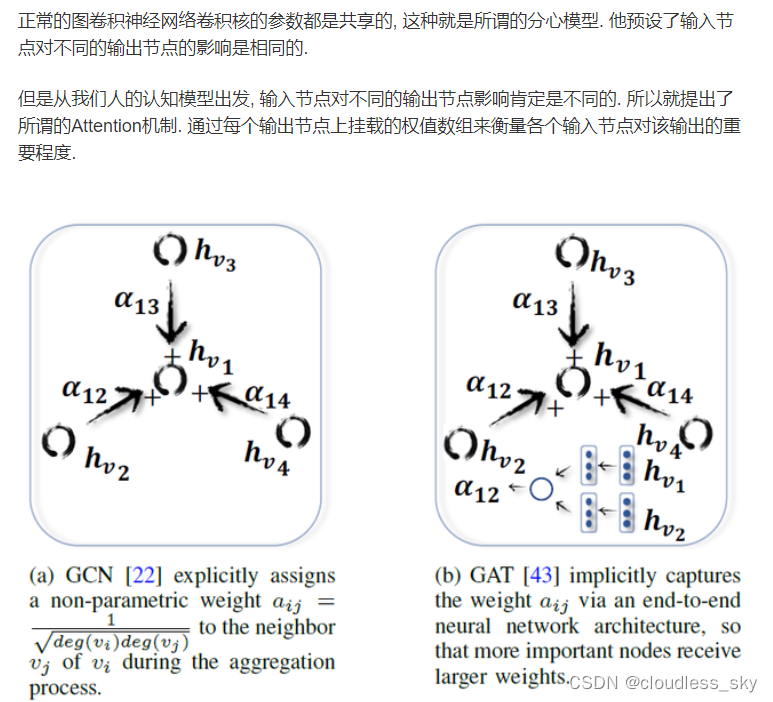
图神经网络 GNN 把深度学习应用到图结构 (Graph) 中,其中的图卷积网络 GCN 可以在 Graph 上进行卷积操作。但是 GCN 存在一些缺陷:**依赖拉普拉斯矩阵,不能直接用于有向图;模型训练依赖于整个图结构,不能用于动态图;卷积的时候没办法为邻居节点分配不同的权重。**因此 2018 年图注意力网络 GAT (Graph Attention Network) 被提出,解决 GCN 存在的问题。
GCN 假设图是无向的,因为利用了对称的拉普拉斯矩阵 (只有邻接矩阵 A 是对称的,拉普拉斯矩阵才可以正交分解),不能直接用于有向图。GCN 的作者为了处理有向图,需要对 Graph 结构进行调整,要把有向边划分成两个节点放入 Graph 中。例如 e1、e2 为两个节点,r 为 e1,e2 的有向关系,则需要把 r 划分为两个关系节点 r1 和 r2 放入图中。连接 (e1, r1)、(e2, r2)。
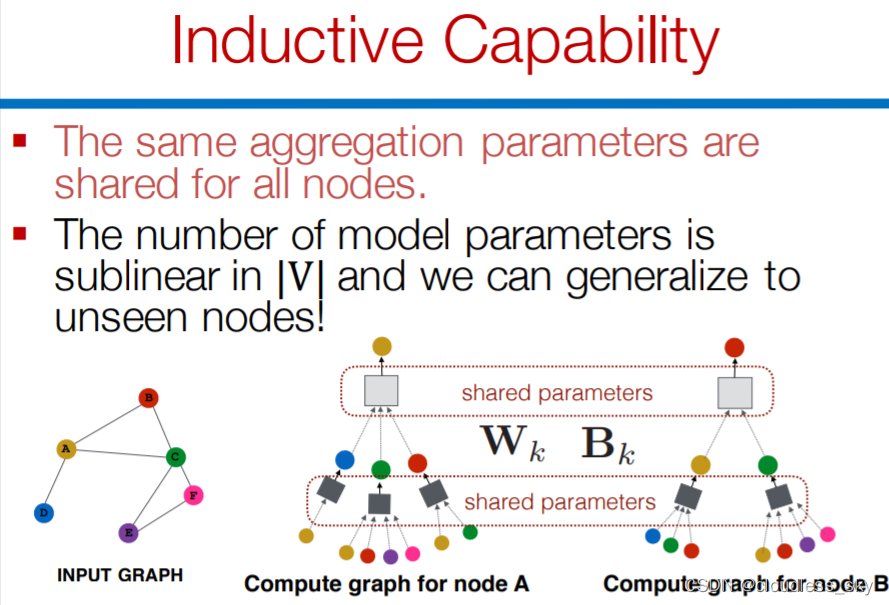
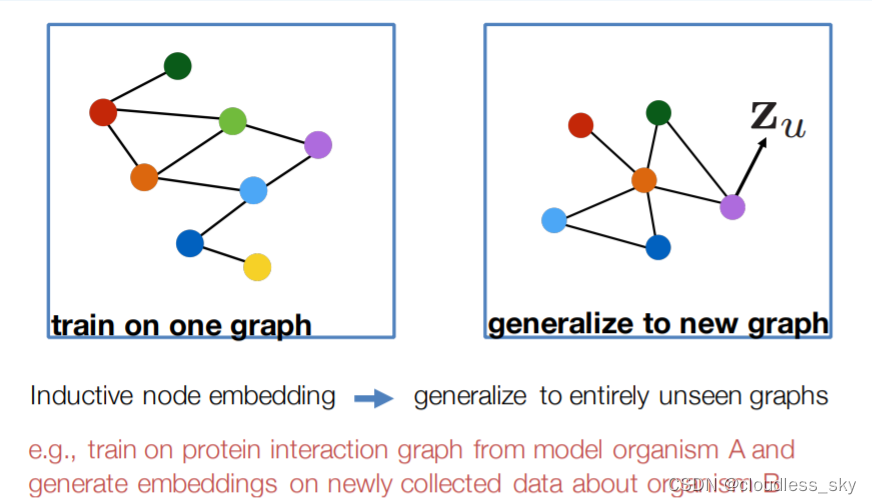
GCN 不能处理动态图,GCN 在训练时依赖于具体的图结构,测试的时候也要在相同的图上进行。因此只能处理 transductive 任务,不能处理 inductive 任务。transductive 指训练和测试的时候基于相同的图结构,例如在一个社交网络上,知道一部分人的类别,预测另一部分人的类别。inductive 指训练和测试使用不同的图结构,例如在一个社交网络上训练,在另一个社交网络上预测。
GCN 不能为每个邻居分配不同的权重,GCN 在卷积时对所有邻居节点均一视同仁,不能根据节点重要性分配不同的权重。
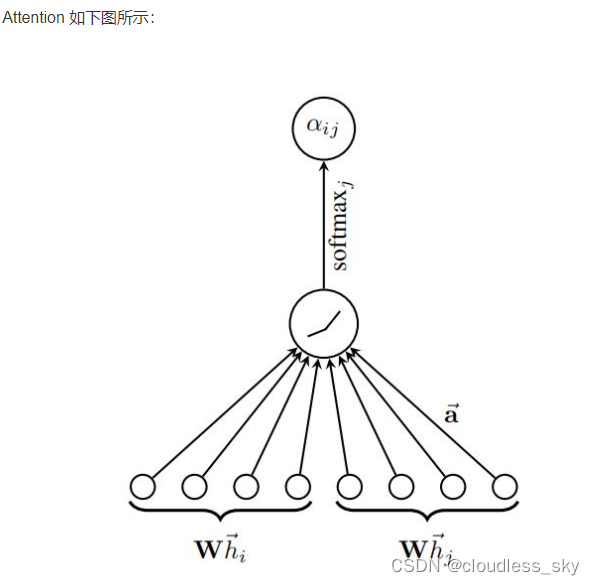
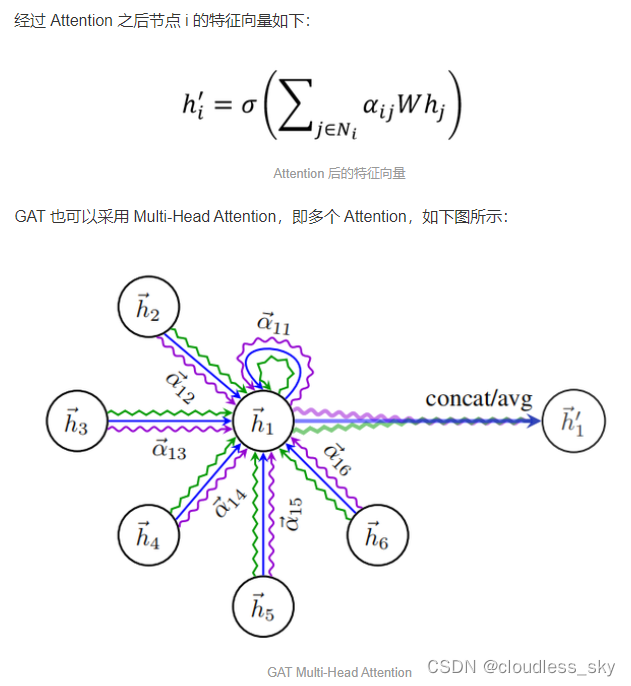
2018 年图注意力网络 GAT 被提出,用于解决 GCN 的上述问题,论文是《GRAPH ATTENTION NETWORKS》。**GAT 采用了 Attention 机制,**可以为不同节点分配不同权重,训练时依赖于成对的相邻节点,而不依赖具体的网络结构,可以用于 inductive 任务。



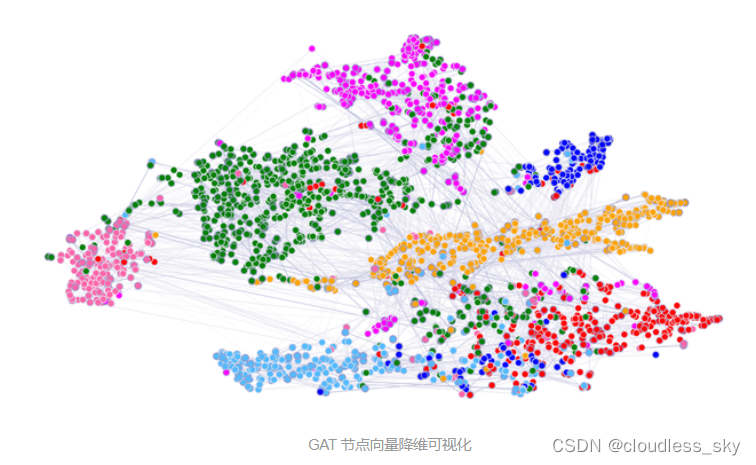

VGAE
https://blog.csdn.net/zz1049694353/article/details/118968296
自编码器图自编码器, 一种自监督的学习框架. 通过编码器学习网络节点的低维表示, 然后通过解码器重构图数据.
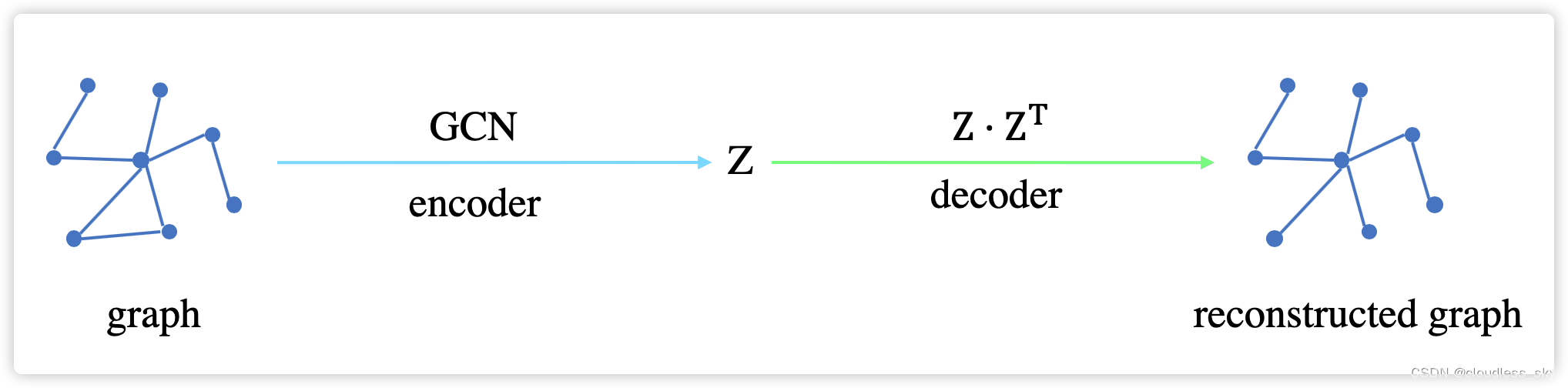
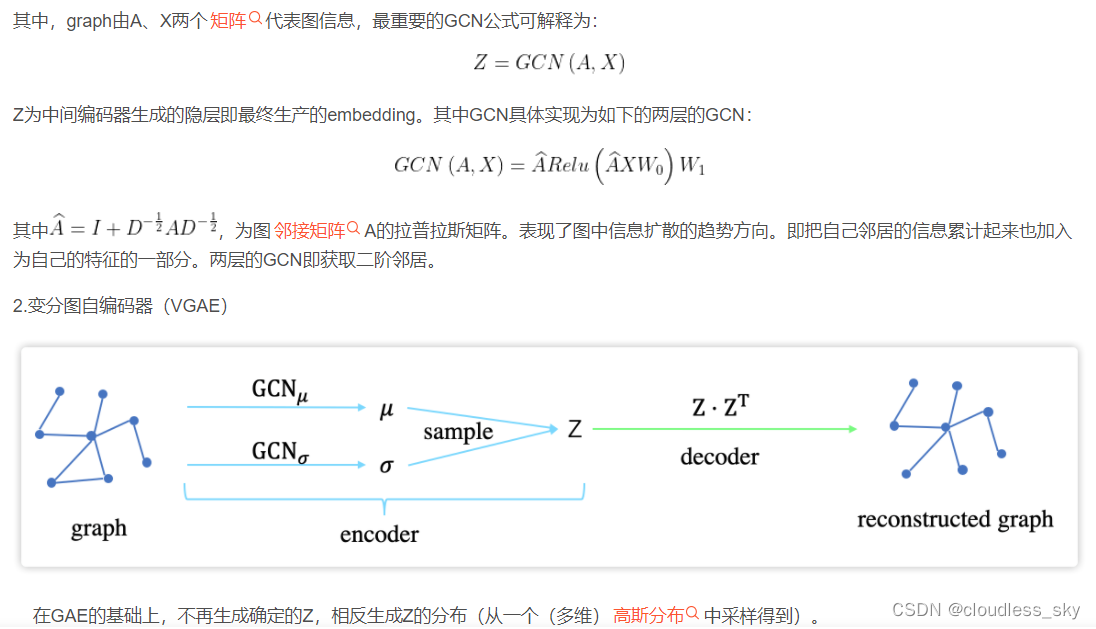
http://www.51blog.com/?p=9363
理解了变分自编码器后,再来理解变分图自编码器就很容易了。如图5所示,输入图的邻接矩阵 A 和节点的特征矩阵 X ,通过编码器(图卷积网络)学习节点低维向量表示的均值 μ 和方差 σ ,然后用解码器(链路预测)生成图。
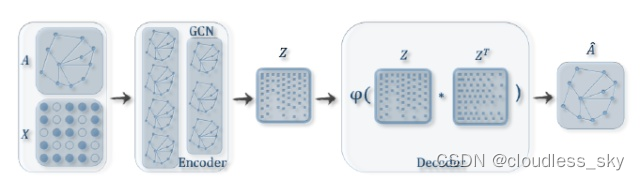



图生成网络GGN
图生成网络, 从数据中获取图的经验分布, 然后根据经验分布来生成全新图结构的网络.
特定领域有很多图网络模型, 比如用于分子图生成的SMILES.
近来提出了一些统一的生成方法, 其中有一部分将图生成看做节点和边的交替生成的过程, 另一部分采用GAN的方案进行训练.

















 3830
3830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









