






MRAG是什么?为什么它比传统模型更聪明?
你问模型:“飞机行李怎么托运?”传统RAG只能给你干巴巴的文字说明,但MRAG不仅能回答文字,还能直接甩出一张流程图甚至教学视频——这就是多模态检索增强生成(MRAG)的魔力!
论文:A Survey on Multimodal Retrieval-Augmented Generation
链接:https://arxiv.org/pdf/2504.08748
MRAG就像给模型装上了“五感”,让它能同时处理文字、图片、视频等多模态数据。论文提到,传统RAG依赖纯文本,容易“脑补”错误信息(学术叫“幻觉”),而MRAG通过真实的多模态数据“查资料”,回答更准确、更接地气!
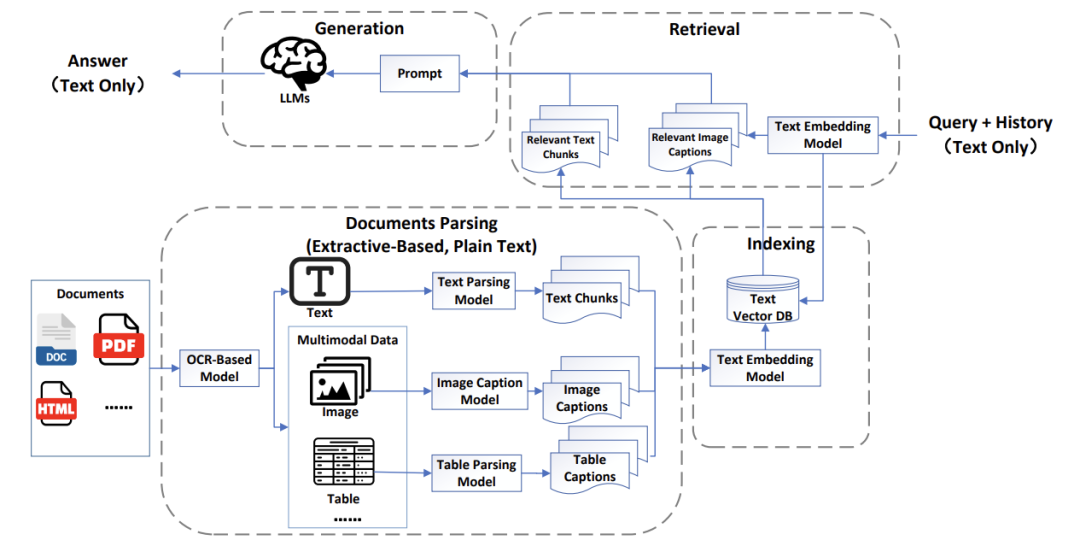
从“伪多模态”到“真全能”:MRAG的三次进化
MRAG的发展:
MRAG 1.0:勉强算“伪多模态”,所有图片视频都要先转成文字描述,信息丢失严重,像是给蒙眼模型猜图片内容。
MRAG 2.0:开始保留原始数据,支持跨模态搜索,比如用文字搜图片,但生成答案时还是不够灵活。
MRAG 3.0:终极大招!直接保留文档截图、支持多模态输出,甚至能根据场景动态切换“理解”和“生成”模式。
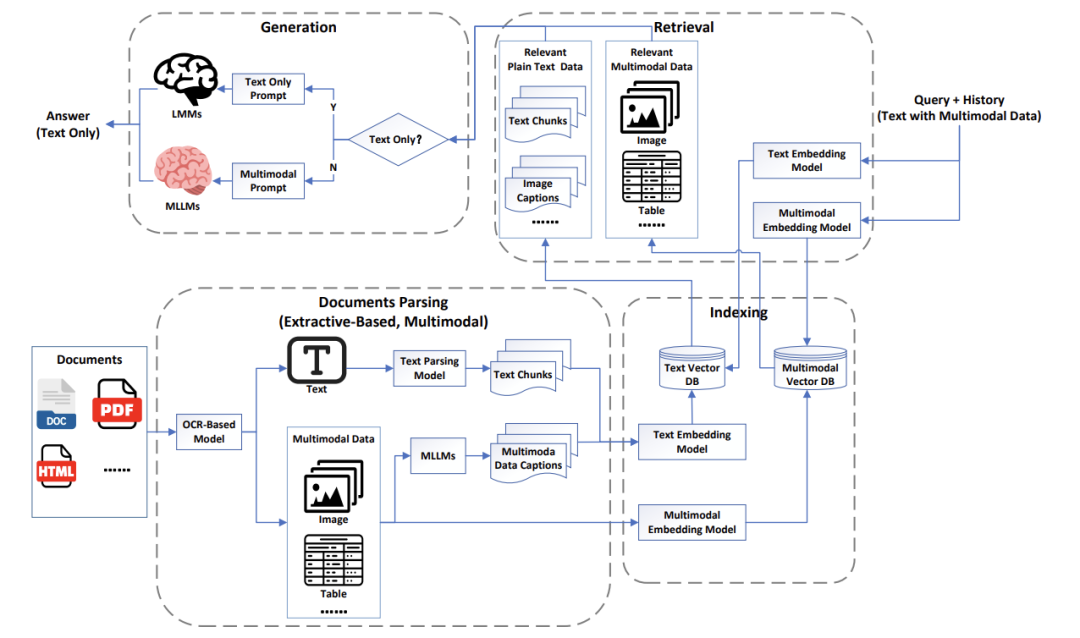
如何同时看懂文字、图片和视频?
MRAG的“大脑”由四大模块构成:
文档解析与索引:把PDF、网页等复杂文档拆解成文字、表格、图片,并打上标签,像图书馆管理员给书分类。
多模态搜索规划:决定什么时候该搜文字、什么时候找图片,避免“瞎忙活”。
跨模态检索:用文本搜图片、用视频找相关文字,核心技术是语义对齐(让不同模态的数据在同一个“语义空间”对话)。
多模态生成:把检索结果“组装”成图文并茂的答案,比如在步骤说明中插入示意图。
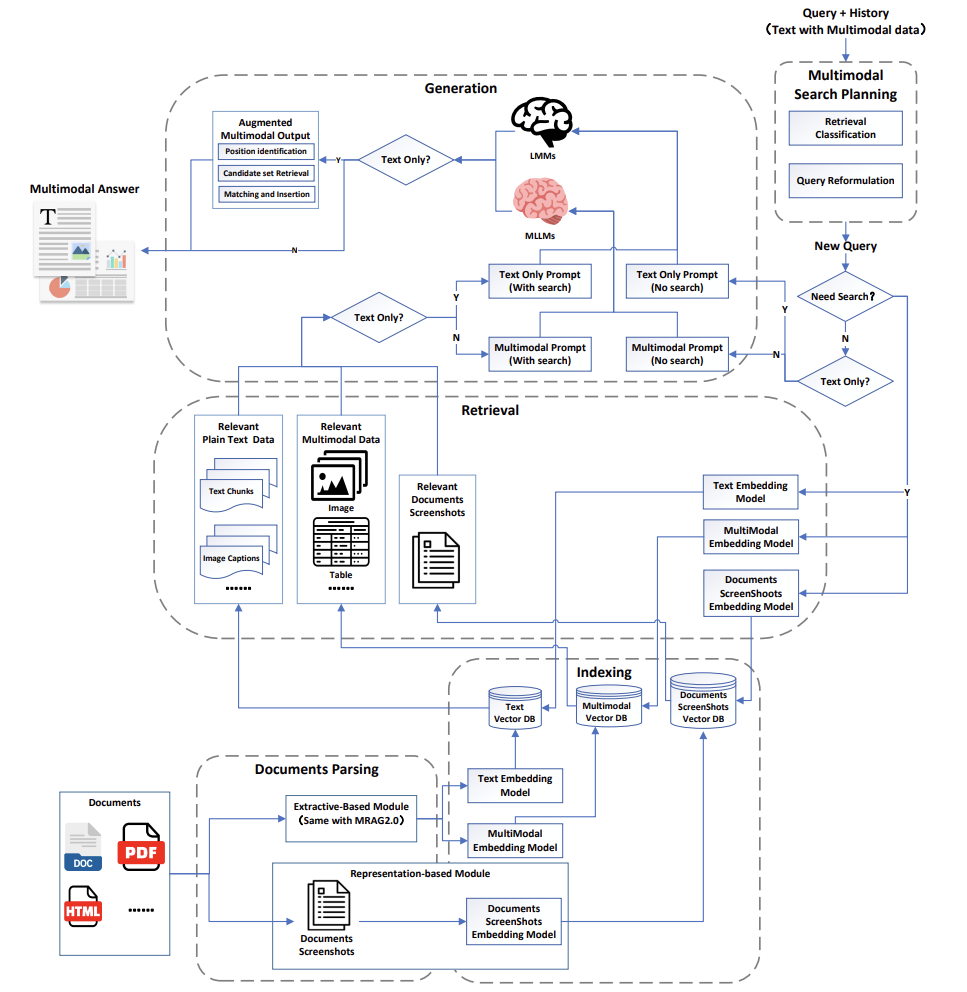
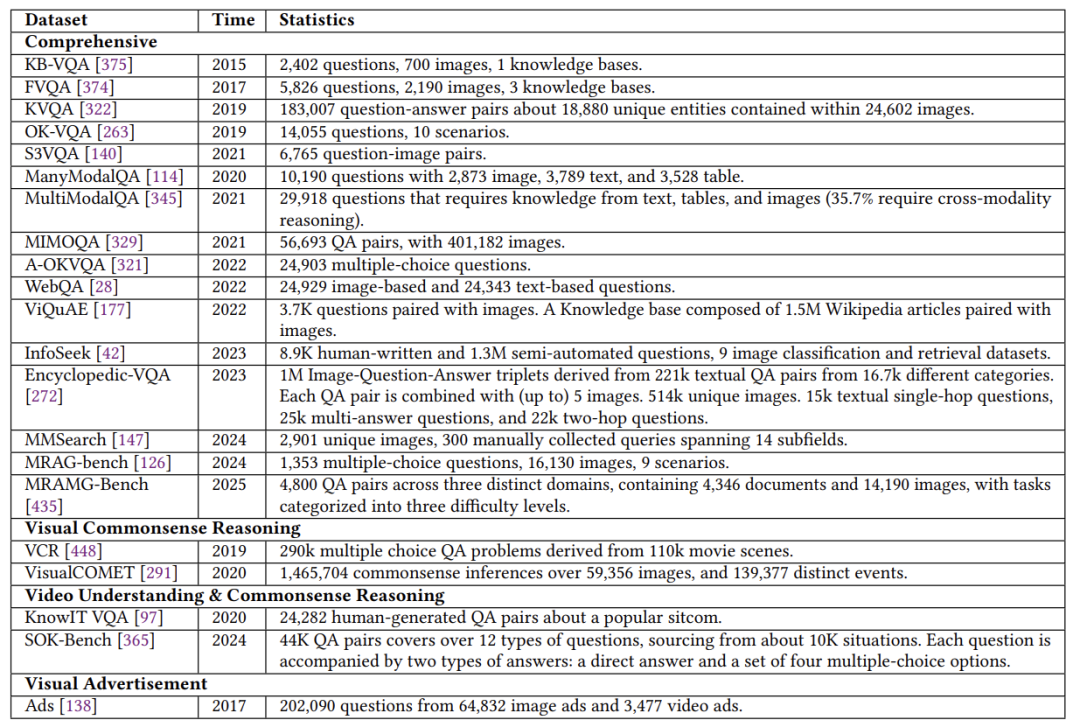
它用什么数据训练和测试?
论文列举了海量数据集,比如:
OK-VQA:需要结合常识回答的图片问答(例如“为什么这幅画里的天空是红色的?”)。
WebQA:从网页中检索图文信息的多跳推理题。
MMBench:覆盖20+能力的综合测试,从物体识别到社会推理全涵盖。
评估指标也很有趣:除了常规的“答案正确率”,还要看幻觉率(AI胡编乱造的程度)和多模态一致性(图文是否匹配)。
MRAG也有短板!
信息丢失:图片转文字时可能忽略细节,比如把“华为溪流背坡村”错认成普通河边小屋。
检索效率:同时处理文字、图片、视频时,如何快速找到最相关的内容?
生成质量:图文混排时容易“前言不搭后图”,比如把猫的图片插到狗的描述里。
论文提到一个典型案例:MRAG 1.0曾因强制图片检索,反而引入了误导信息,导致答案翻车!
未来已来:多模态RAG将如何改变我们的生活?
教育:教科书变成“动态百科”,学生问“光合作用”,AI直接展示3D动画+实验视频。
医疗:CT片+病历文字联合分析,辅助医生快速诊断。
电商:拍照搜同款时,模型不仅能找商品,还能推荐搭配方案。
论文预言,未来的MRAG将走向自适应搜索规划(像人类一样动态调整策略)和全模态统一建模(文字、图片、音频、3D无缝融合),真正成为人类的“全能助手”。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









