







作者: 19届 lz
论文:《Robust Physical-World Attacks on Deep Learning Visual Classification》
问题
最近的研究表明,最先进的深度神经网络 (DNN) 容易受到对抗性示例的攻击,这是由于输入中添加了小幅度的扰动。鉴于新兴物理系统在安全关键情况下使用 DNN,对抗性示例可能会误导这些系统并导致危险情况。因此,了解物理世界中的对抗性示例是开发弹性学习算法的重要一步。
贡献:
我们提出了一种通用攻击算法,鲁棒物理扰动(RP2),以在不同的物理条件下生成鲁棒的视觉对抗扰动。使用道路标志分类的真实案例,我们展示了使用 RP2 生成的对抗性示例在包括视点在内的各种环境条件下,与物理世界中的标准架构道路标志分类器相比,实现了高目标错误分类率。
相关工作

左图显示了停车标志上的真实涂鸦,大多数人不会认为这是可疑的。右图显示了我们应用于停车标志的物理扰动。我们设计我们的扰动来模仿涂鸦,从而“隐藏在人类的心灵中”。
RP2 管道概述。输入是目标停车标志。 RP2 从模拟物理动力学(在本例中为变化的距离和角度)的分布中采样,并使用掩码将计算的扰动投影到类似于涂鸦的形状。对手打印出产生的扰动并将它们粘贴到目标停车标志上。
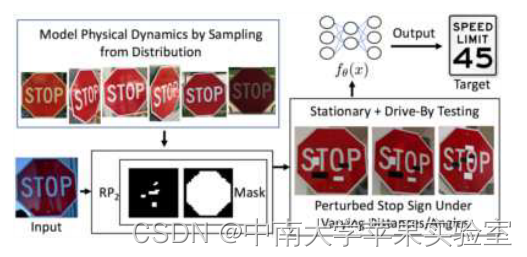
RP2 管道概述。输入是目标停车标志。 RP2 从模拟物理动力学(在本例中为变化的距离和角度)的分布中采样,并使用掩码将计算的扰动投影到类似于涂鸦的形状。对手打印出产生的扰动并将它们粘贴到目标停车标志上。
图 2 显示了我们生成和评估强大的物理对抗性扰动的管道的概述。
-
我们引入鲁棒物理扰动 (RP2) 来为物理世界对象生成物理扰动,这些扰动可能会在一系列动态物理条件下(包括不同的视点角度和距离)始终导致基于 DNN 的分类器中的错误分类(第 3 节)。
-
鉴于在评估物理对抗性扰动时缺乏标准化的方法,我们提出了一种评估方法来研究物理扰动在现实世界场景中的有效性(第 4.2 节)。
-
我们针对我们构建的两个标准架构分类器评估我们的攻击:LISA-CNN 在 LISA 测试集上的准确率为 91%,GTSRB-CNN 在 GTSRB 测试集上的准确率为 95.7%。使用我们介绍的两种类型的攻击(对象约束海报和贴纸攻击),我们表明 RP2 对真实路标产生了强大的扰动。例如,海报攻击在针对 LISA-CNN 的静态和路过测试中 100% 成功,贴纸攻击在针对 GTSRB-CNN 的 80% 静态测试条件和 87.5% 的提取视频帧中成功。
-
为了展示我们方法的普遍性,我们通过操纵一般物理对象(例如微波炉)来生成鲁棒的物理对抗样本。我们展示了预训练的 Inception-v3 分类器通过添加单个贴纸将微波错误分类为“电话”。
物理世界的挑战
对物体的物理攻击必须能够在不断变化的条件下幸存下来,并能有效地欺骗分类器。我们围绕选定的道路标志分类示例构建对这些条件的讨论,该示例可能应用于自动驾驶汽车和其他安全敏感领域。这些条件的一部分也可以应用于其他类型的物理学习系统,例如无人机和机器人。
环境条件
自动驾驶汽车中的摄像头相对于路标的距离和角度不断变化。输入分类器的结果图像以不同的距离和角度拍摄。因此,攻击者在物理上添加到路标上的任何扰动都必须能够在图像的这些转换中幸存下来。其他环境因素包括照明天气条件的变化,以及摄像头或路标上是否存在碎片。
空间约束
当前专注于数字图像的算法向图像的所有部分(包括背景图像)添加了对抗性扰动。但是,对于物理路标,攻击者无法操纵背景图像。此外,攻击者不能指望有固定的背景图像,因为它会根据观察摄像机的距离和角度而变化。
不易察觉的物理限制
当前对抗性深度学习算法的一个吸引人的特点是它们对数字图像的扰动通常非常小,以至于它们几乎不会被不经意的观察者察觉。然而,当将这种微小的扰动转移到现实世界时,我们必须确保相机能够感知到这些扰动。因此,对于难以察觉的扰动存在物理限制,并且取决于传感硬件。
制造错误
为了制造计算出的扰动,所有扰动值必须是可以在现实世界中再现的有效颜色。此外,即使制造设备(例如打印机)可以产生某些颜色,也会存在一些复制错误。
为了成功地对深度学习分类器进行物理攻击,攻击者应考虑上述物理世界变化类别,这些变化会降低扰动的有效性。
具体方案
我们从为单个图像 x 生成扰动的优化方法开始推导出我们的算法,而不考虑其他物理条件
目标
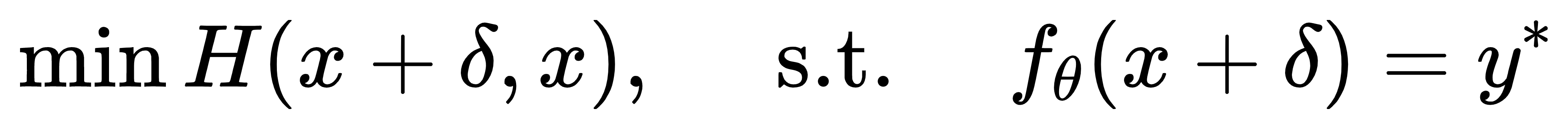
H: 是选择的距离函数
x:目标样本或原始样本;
f:自动驾驶领域的路标分类器,也叫做目标函数;
y∗ :是目标类
为了更有效地解决约束优化问题,使用Lagrangian-relaxed form对上述目标函数进行优化
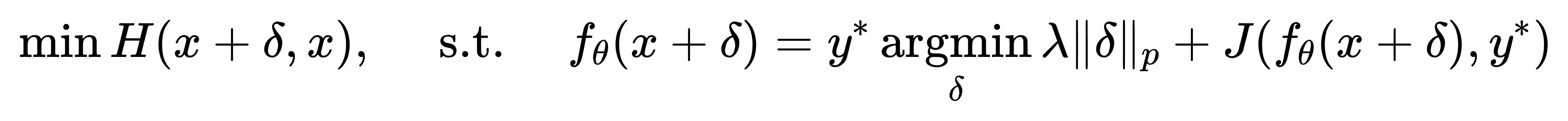
J:损失函数, 衡量模型的预测与目标标签 y* 之间的差异;
λ :控制失真正规化的超参数;
∥δ∥p: 距离函数,表示 δ 的 ℓp 范数
如何根据物理条件更新目标函数
mask的作用:此mask用于将计算的扰动投影到对象(即道路标志)表面的物理区域。除了提供空间局部性之外,mask还有助于产生对人类观察者可见但不明显的扰动。要做到这一点,攻击者可以将面具塑造成涂鸦的样子——这是大多数人所期待和忽视的街头常见的破坏行为,因此隐藏了“人类心理中”的扰动。
mask是一个矩阵Mx,其维数与道路标识分类器输入的大小相同。Mx在没有添加扰动的区域为0,在优化期间添加扰动的区域为1。
具体来说,我们使用以下方法来发现mask位置:
1)使用 L1 正则化和使用占据标志整个表面区域的mask计算扰动。 L1 使优化器有利于稀疏扰动向量,因此将扰动集中在最脆弱的区域上。可视化产生的扰动为mask放置提供指导。
2) 使用 L2 重新计算扰动,mask位于前面步骤中识别的易受攻击区域上。
为了解释制造误差,我们在目标函数中添加了一个附加项(NPS) ,用于模拟打印机色彩再现误差。
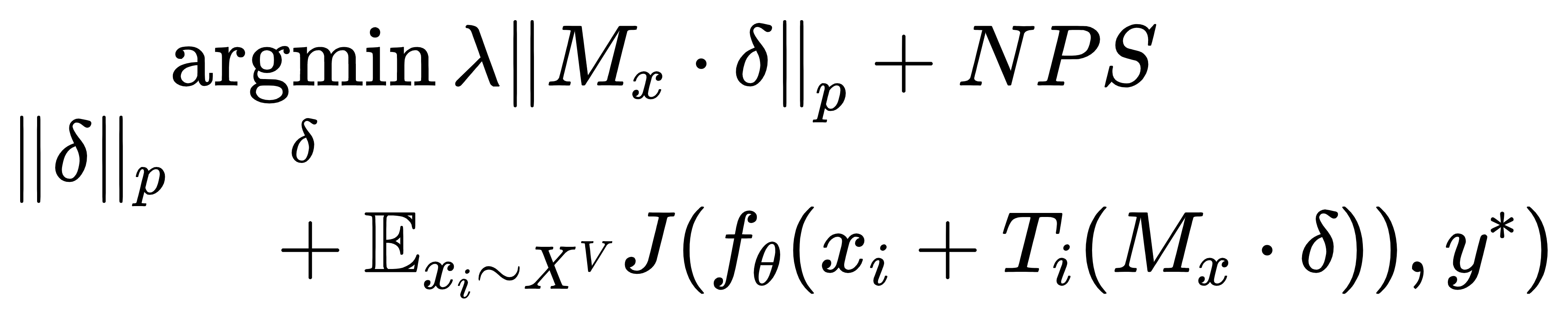
其中,Mx表示mask矩阵,Ti表示将对象上的变换映射到扰动上的变换的对齐函数。
最后,攻击者将优化结果打印在纸上,剪下扰动(Mx),放到目标对象o上。
实验部分
数据集:LISA和GTSRB
路标分类器:LISA-CNN[1]和GTSRB-CNN[2]
[1] N. Papernot, I. Goodfellow, R. Sheatsley, R. Feinman, and
P. McDaniel. cleverhans v1.0.0: an adversarial machine learning library. arXiv preprint arXiv:1610.00768, 2016.
[2] J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel. Man vs.computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Networks, 2012.


















 4542
4542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











