






前言
随着ChatGPT 的兴起,大语言模型再次被提及,越来越多的行业开始探索,如导购、政府、教育、医疗等行业;
大语言模型的突破,展现出了类人的通用智能“涌现”能力,能够学习多个领域的知识、处理多种任务,因此被称为通用大模型,通用大语言模型具备特点也具备不足,大模型特点主要参数模型大、泛化能力强、支持多模态,如 GPT、豆包、通义等在语言交互场景回答问题表现出色。虽然大语言模型在多个指标展现的能力可能超出人类,但大语言模型也存在诸多不足:
-
不可能的三角问题: 大模型在专业性、泛化性和经济性三方面不可兼得,产生不可能的三角问题。大模型的准确性要求越高,越需要特定领域数据进行训练,可能造成模型过拟合而降低泛化能力,以及增加数据收集和训练成本,降低经济性。
-
知识局限性: 大语言模型知识的广度严重依赖于训练模型时数据的广度,目前的市面上大部分大语言模型的训练数据都来源于互联网,对于内部企业知识、特定领域知识等无从学习。
-
模型幻觉问题: 所有 AI 模型的底层原理都是基于数学概率,模型的输出本质是一系列的数值的运算,所以大模型有时候会一本正经的胡说八道,在大模型不擅长的场景或不具备某一方面的知识表现尤为突出。区分大模型的幻觉比较困难,要求使用者具备相应领域的知识。
-
知识滞后性: 大语言模型的知识的获取都是通过训练数据集获得,模型训练后产生新的知识模型无法快速学习,想要增加新的知识需要进行训练,成本极高。
—、为什么大语言模型产生幻觉问题?
什么是大模型幻觉:在大语言模型中幻觉表示模型输出了内容,但是内容是虚假文本,容易导致一些错误发生。
让模型产生幻觉的原因可能是:
-
模型训练数据: 大语言模型是通过互联网上的各种各样的数据训练,并不关心训练过程中使用的具体文档和来源。模型训练的重点不在于具体细节,而是广泛性,这样大模型能够输出创造性的答案、参与复杂的对话。如果训练数据不准确、误导性,模型可能学习到这些信息并在生成文本时表现出来。
-
模型自身限制: 模型的运作都是基于 token 的概念,token 是从单个字符到整个字符的离散语言单位。大语言模型一次性处理特定数量的 token,使用复杂的数学计算模型来预测序列中最有可能出现的下一个 token。而对于没有学习的特定领域的知识、新的知识、以及一些专业场景,模型输出可能导致出现幻觉;
-
上下文理解的限制: 在理解上下文时可能存在限制,当上下文不足或存在歧义时,可能导致生产的文本不准确,导致出现幻觉。
因此通用大模型以发展通识为目标,更侧重泛化性,在专业性方面很难满足具体行业的特定需求,存在“有幻觉”等情况。
通用大模型在toB垂直领域,由于缺乏细分专业知识,所以更容易产生幻觉。每一个客户都有自己独特的数据、业务、流程等,因此需要训练行业大模型,紧密结合业务系统实现可落地的智能应用。客户针对行业大模型加上自己的数据进行训练和微调,才能大打造出适合企业智能服务。
二、如何解决大语言模型幻觉问题?
在解决大语言模型幻觉构建行业大模型的过程中,由于需求和目标不同,目前有四种方式提示词工程、检索增强生成、微调、预训练。
1、引导:提示工程
提示工程(prompt engineering) 指通过针对性的设计提示词(prompt)来引导大模型产生出特定应用场景所需要的输出。
大语言模型的相应质量取决于用户提供的提示和指令,我们与大模型互动给予其指令显著影响其生成答案的质量。
提示工程啥上手相对简单,不需要批量采集数据以及构建数据集,更不需要调整或训练模型本身。因此在在企业构建行业大模型的落地中,解决模型幻觉问题,可以采用这种方式来探索进行快速落地。
提示工程适用于快速探索应用的场景,如文案创作、对话系统等,优化提示词可以显著提升生成内容的质量。
2、外挂:检索增强生成
增强增强生产(RAG,retrieval - Augmented Generation) 指在不改变大模型本身的基础上,通过外挂知识库等方式,为模型提供特定领域的数据信息输入,实现对特定领域更加精准的信息检索和生产。
主要优点:
-
满足企业自由数据所有权的诉求: 模型本身只会查找和调用外挂的数据,并不会将外挂的知识库数据进行训练,变成模型自有知识。
-
提高模型的准确性: 通过外挂知识库的方式,让模型能基于特定数据生成内容,降低模型的幻觉。
-
具备高性价比: 底层的大语言模型不做调整,不需要投入人力和算力进行微调和预训练,能够快速开发和部署。
RAG的核心能力是检索和生成。基本的流程是将私有化知识进行切片并进行向量化,回答问题时,当用户提出出一个问题,RAG对问题进行向量化,利用向量检索私有数据,找到问题的相关信息,再结合提示词将问题和检索到的信息作为上下文输入到通用大模型,模型接收到这个强提示后,将自己的内部知识综合,最后生成更准确的内容。
检索增强生成适用于需要引用大量知识的场景,如问答系统、专业咨询等,生成内容准确性高,并且保证了自有数据所有权。
3、优化:微调
微调(FT,Fine - tuning)是在已经预训练的大模型基础上,基于特定数据集进一步调整大模型的部分参数,使大模型更好地适应业务场景、准确完成特定任务。微调目前是较为常用的行业大模型构建方法。
微调适用于特定行业领域对大模型有更好性能要求的场景,在实际的行业应用中,当通用大语言模型无法理解或生成专业的行业内容时,可以通过微调的方式,提升大模型理解行业特定术语和正确应用行业知识的能力,确保大语言模型的输出符合特定行业或业务诉求。
微调后的通用大模型不仅保留了原有的通用知识,还会将行业知识内化到大模型参数中,较为准确的理解和使用行业知识,更好地适应特定行业的场景,提供更加贴合实际需求的解决方案。
微调适用于系统通过大模型在行业应用场景表现的更好的场景,具备较好的行业泛化能力。
4、原生:预训练
预训练适用于现有通用大模型差异比较大的场景,以及通过提示词、检索增强生成、微调无法达到需求标准时,构建一个专门为特定行业的大模型。
预训练的方式需要收集并标注大量的行业特定数据集,涵盖文本、图像、交互记录等,以及特殊格式数据。在训练过程中,模型通常采用从底层参数开始训练,或者基于具备一定能力的通用模型进行后训练(二次增训,post-training),目的是大模型更好地理解特定领域的知识、术语,提供大模型在行业应用中的准确性,确保领域的专业性。
预训练的方式一般需要投入较大的成本,需要大量的计算资源和长期的训练过程,一般较少使用这种方式。
预训练适用于通用大模型缺乏目标任务相关的知识和能力的场景,专业性高能够准确理解并执行特定任务。
03
—
典型案例
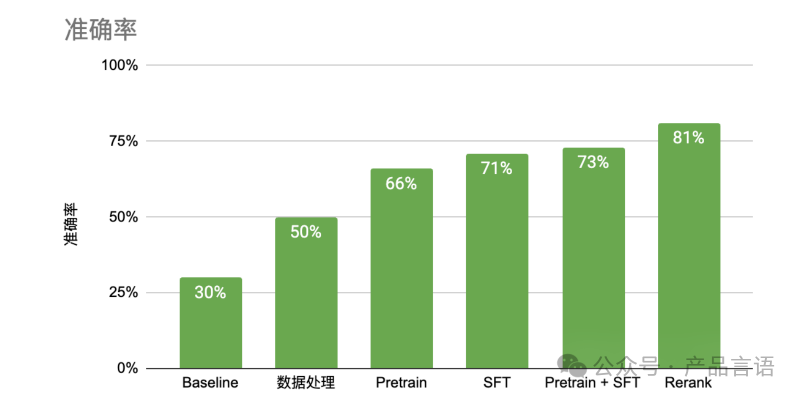
在具体的落地中,通常不会只使用一种方式,而是组合使用以实现最佳效果,如在目前构建的智能客服问答系统中会综合使用提示词工程、检索增强生成和微调等方式。
大模型结合RAG(检索增强生成)构建的客服系统结合多种方式提升RAG的问答准确率。
提示工程(Prompt Engineering):
-
清晰的区分 context & query
-
在 prompt 中针对场景描述额外的需求
-
模板:你作为XXXX的客服,解答用户在使用XX时遇到的问题,以下是几条可能与用户问题相关的常见问题与答案,你只能根据提供的材料来回答用户的问题。如果提供的材料无法回答用户问题,请你回答:"抱歉,无法回答您的问题!”以下是可能与用户问题相关的常见问题与答案:
(检索增强召回的内容)
用户问题:
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









