






前言
最近很多朋友都提到,对多模态融合的概念、方法和实际应用总是摸不透,尤其是在不同融合策略的选择和代码实现上有不少疑问。所以今天咱们就把多模态融合的核心知识、主流方法和典型案例梳理清楚,帮大家彻底搞懂这个热门方向!
大家都知道,多模态数据(如图像、文本、语音)在现实场景中无处不在,但单一模态数据往往存在信息局限 —— 比如图片缺语义、文本缺视觉细节、语音缺场景上下文。而多模态融合能整合不同模态的冗余信息(增强可靠性)和互补信息(填补信息缺口),让模型更全面地理解数据,这也是当前 AI 从 “单模态感知” 走向 “多模态认知” 的关键一步。
今天和大家分享的多模态融合核心内容包括:
- 多模态学习的核心任务
- 多模态融合的基础分类
- 主流多模态融合方法(含原理、公式、优缺点)
- 典型应用案例与代码示例
1.多模态学习的核心任务
在讲融合之前,得先明确多模态学习要解决的核心问题。本质上,多模态学习是让模型处理 “跨模态信息交互”,主要包含 5 大任务,这些任务也是融合方法的应用场景基础:
- 表征(Representation):将多模态数据映射到统一 / 关联的特征空间,便于后续处理。典型的场景有:文本 - 图像语义对齐、跨模态检索。
- 翻译(Translation):将一种模态的信息转换为另一种模态(如文本转图像、语音转文字)。典型的场景有:图像描述生成、语音识别。
- 对齐(Alignment):找到不同模态 “子成分” 的对应关系(如文本中的 “猫” 对应图像中的猫区域)。典型的场景有:视频字幕对齐、跨模态注意力。
- 融合(Fusion):整合多模态特征,生成更全面的联合表示,用于下游任务(分类、预测等)。典型的场景有:情感分析、点击率预估。
- 联合学习(Co-learning):用数据丰富的模态(如图像)辅助数据稀缺的模态(如文本),提升整体性能。典型的场景有:零样本分类、跨模态迁移学习
其中,融合(Fusion) 是多模态学习的核心环节 —— 所有跨模态任务最终都需要通过 “融合” 整合信息,所以接下来重点拆解融合方法。
2.多模态融合的基础分类
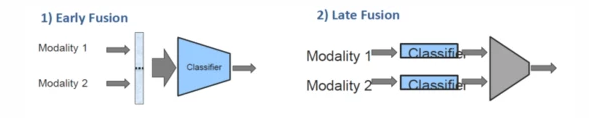
按 “融合发生的阶段”,多模态融合可分为三大类,不同阶段对应不同的适用场景和优缺点,这是选择融合策略的第一步:
早期融合(Early Fusion)
- 原理:在 “特征提取阶段” 就将多模态特征整合(如拼接、加权求和),再输入模型进行后续任务(如分类)。相当于 “先融合,再建模”。
- 核心操作:比如将图像的 CNN 特征(如 ResNet 输出)和文本的 Embedding(如 BERT 输出)直接
concat,再输入全连接层。 - 优缺点:
- 优点:能尽早利用模态间的底层关联,信息损失少。
- 缺点:易受模态异质性影响(如图像特征维度高、文本特征维度低),且存在信息冗余,可能导致模型过拟合。
- 适用场景:模态特征维度相近、底层关联强的任务(如音频 - 视频语音识别)。
晚期融合(Late Fusion)
- 原理:先对每个模态单独建模(如图像用 CNN、文本用 RNN),得到各模态的 “任务结果”(如分类概率),再对结果进行融合(如投票、加权平均)。相当于 “先建模,再融合”。
- 核心操作:比如图像分类器输出概率
P_img、文本分类器输出概率P_txt,最终结果取(P_img + P_txt)/2。 - 优缺点:
- 优点:各模态模型独立训练,鲁棒性强,能避免模态异质性带来的干扰。
- 缺点:无法利用模态间的底层关联,信息整合不充分,可能错过关键交叉特征。
- 适用场景:模态差异大、单独建模效果好的任务(如跨模态检索、多模态情感分析)。
混合融合(Hybrid Fusion)
- 原理:结合早期融合和晚期融合的优势,在模型的多个阶段进行融合(如底层特征早期融合、中层特征注意力融合、顶层结果晚期融合)。
- 核心操作:比如在 Transformer 模型中,底层对图像 - 文本特征做
shuffle融合,中层用跨模态注意力对齐,顶层对各模态预测结果做加权融合。 - 优缺点:
- 优点:灵活性高,能充分利用不同阶段的模态信息,效果通常最优。
- 缺点:模型结构复杂,需要更多调参和计算资源。
- 适用场景:复杂多模态任务(如视频描述生成、多模态点击率预估)

3.主流多模态融合方法详解
接下来逐个拆解工业界和学术界常用的融合方法,每个方法都包含 “原理、核心公式、优缺点、适用场景”,并附代码示例或关键实现思路。
①张量融合网络(TFN:Tensor Fusion Network)
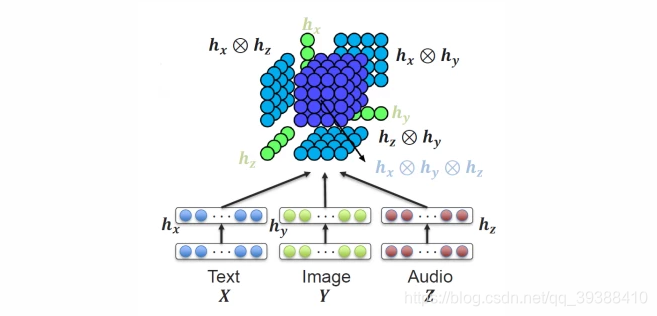
原理
TFN 是早期融合的经典方法,通过 “张量外积(Outer Product)” 计算多模态特征间的交叉关联,捕捉模态间的细粒度交互。比如对文本(X)、图像(Y)、语音(Z)三种模态,先给每个特征加一个 “偏置项 1”,再做张量外积得到融合特征。
核心公式
假设三种模态的特征分别为
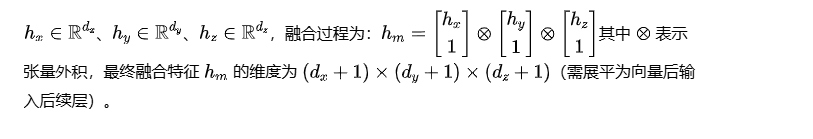
优缺点
- 优点:能捕捉模态间的高阶交互,对细粒度关联建模能力强。
- 缺点:特征维度爆炸(如 d_x=d_y=d_z=100 时,融合后维度超 100 万),模型训练困难,易过拟合。
适用场景
模态数量少(2-3 种)、特征维度低的任务(如简单文本 - 图像情感分析)。
核心代码示例(PyTorch)
import torchimport torch.nn as nnclass TFN(nn.Module): def __init__(self, d_x, d_y, d_z, out_dim): super(TFN, self).__init__() self.d_x, self.d_y, self.d_z = d_x, d_y, d_z # 计算融合后特征维度(加1为偏置项) fusion_dim = (d_x + 1) * (d_y + 1) * (d_z + 1) self.fc = nn.Linear(fusion_dim, out_dim) # 展平后映射到输出维度 def forward(self, x, y, z): # 给每个特征加偏置项1(batch_size维度保持不变) x_with_bias = torch.cat([x, torch.ones_like(x[:, :1])], dim=1) # (bs, d_x+1) y_with_bias = torch.cat([y, torch.ones_like(y[:, :1])], dim=1) # (bs, d_y+1) z_with_bias = torch.cat([z, torch.ones_like(z[:, :1])], dim=1) # (bs, d_z+1) # 张量外积:先计算x与y的外积,再与z做外积 xy = torch.einsum('bi,bj->bij', x_with_bias, y_with_bias) # (bs, d_x+1, d_y+1) xyz = torch.einsum('bij,bk->bijk', xy, z_with_bias) # (bs, d_x+1, d_y+1, d_z+1) # 展平为向量 xyz_flat = xyz.view(xyz.shape[0], -1) # (bs, (d_x+1)(d_y+1)(d_z+1)) return self.fc(xyz_flat) # 输出融合结果# 测试if __name__ == "__main__": bs = 32 # batch_size d_x, d_y, d_z = 50, 64, 32 # 文本、图像、语音特征维度 x = torch.randn(bs, d_x) y = torch.randn(bs, d_y) z = torch.randn(bs, d_z) model = TFN(d_x, d_y, d_z, out_dim=10) # 输出维度10(如10分类) out = model(x, y, z) print("TFN输出形状:", out.shape) # 应输出 (32, 10)
②低秩多模态融合(LMF:Low-rank Multimodal Fusion)
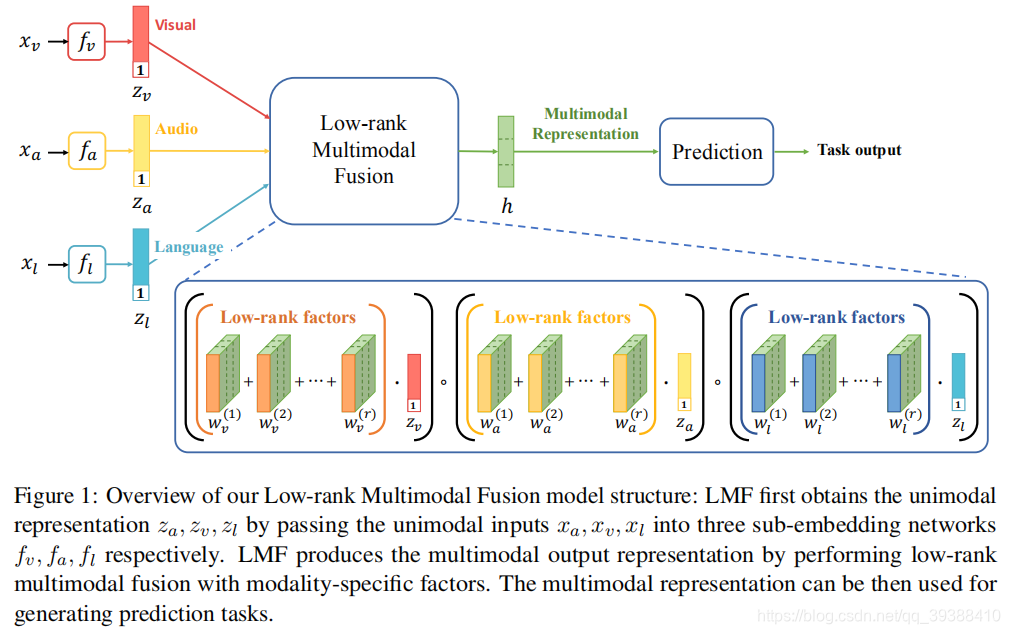
原理
LMF 是 TFN 的优化版,解决 TFN 维度爆炸问题。核心思路是 “低秩矩阵分解”:将原本高维的张量外积操作,拆解为 “各模态单独线性变换 + 低秩交叉”,用低秩向量的和替代高维张量,减少参数数量。
核心公式

优缺点
- 优点:解决了 TFN 的维度爆炸问题,参数更少,训练更稳定,同时保留模态间的交叉关联。
- 缺点:当模态特征维度过大时(如视觉特征维度 1024),仍可能出现参数冗余;低秩维度 K 的选择依赖经验。
适用场景
中高维度多模态特征融合(如基于 ResNet 视觉特征 + BERT 文本特征的分类任务)。
核心代码示例(PyTorch)
# 核心思路:拆解为“模态线性变换 + 低秩交叉”class LMF(nn.Module): def __init__(self, d_a, d_v, d_l, K, out_dim): super(LMF, self).__init__() self.K = K # 低秩维度 # 各模态线性变换(映射到K个低秩分量) self.fc_a = nn.Linear(d_a, K) self.fc_v = nn.Linear(d_v, K) self.fc_l = nn.Linear(d_l, K) # 最终输出层 self.fc_out = nn.Linear(K, out_dim) def forward(self, x_a, x_v, x_l): # 各模态映射到低秩空间 z_a = self.fc_a(x_a).unsqueeze(-1) # (bs, K, 1) z_v = self.fc_v(x_v).unsqueeze(-1) # (bs, K, 1) z_l = self.fc_l(x_l).unsqueeze(-1) # (bs, K, 1) # 低秩交叉:元素积求和(K个分量分别交叉后相加) fusion = (z_a * z_v * z_l).sum(dim=-1) # (bs, K) return self.fc_out(fusion) # (bs, out_dim)
③ 记忆融合网络(MFN:Memory Fusion Network)
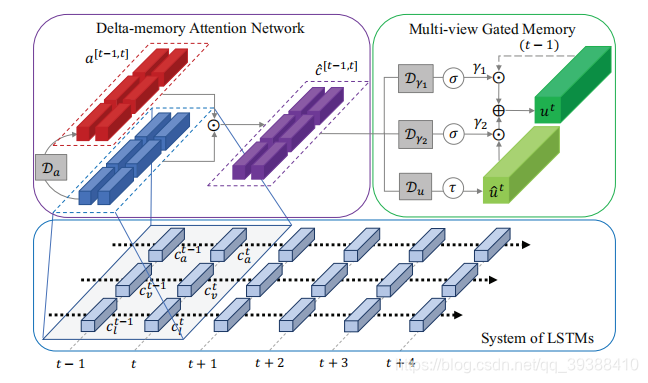
原理
MFN 是基于注意力和记忆机制的融合方法,专门处理 “时序多模态数据”(如视频 + 语音 + 文本的时序序列)。核心是用 “门控记忆单元” 保存历史模态交互信息,用 “Delta 注意力” 捕捉当前模态与历史的差异,实现动态融合。
核心结构
- 多视图门控记忆(Multi-View Gated Memory):保存上一时刻的多模态融合状态,通过门控(Gating)控制历史信息的保留比例;
- Delta 注意力(Delta-memory Attention):计算当前模态特征与历史记忆的差异,给重要差异赋予高权重;
- LSTM 时序编码:对时序化的融合特征进行编码,捕捉时间维度上的模态交互。
优缺点
- 优点:能处理时序多模态数据,动态捕捉模态间的时序关联;注意力机制提升关键信息的权重。
- 缺点:模型结构复杂,训练成本高;对短时序数据可能存在过拟合。
适用场景
时序多模态任务(如视频情感分析、多模态对话系统)
④模态注意力融合(Modal Attention)
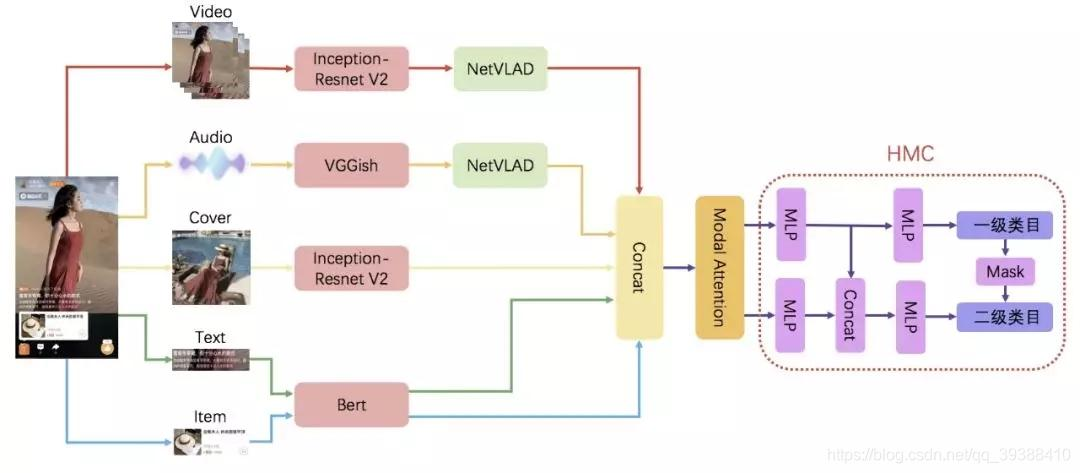
原理
模态注意力是最常用的自适应融合方法:通过注意力机制学习 “不同模态的重要性权重”,再按权重对多模态特征进行加权融合。比如在淘宝视频推荐中,模型会自动判断 “图像、文本、音频” 哪个对 “商品分类” 更重要,给重要模态更高权重。
核心公式

优缺点
- 优点:自适应调整模态权重,对不同任务的适配性强;实现简单,易嵌入现有模型。
- 缺点:当模态特征差异过大时,注意力权重可能偏向某一模态(如文本模态占主导),忽略其他模态的互补信息。
适用场景
多模态分类、推荐系统、点击率预估(如淘宝商品分类、广告 CTR 预测)。
核心代码示例(PyTorch)
# 淘宝视频多模态分类:图像(ResNet) + 文本(BERT) + 音频(VGGish) + 模态注意力class ModalAttentionFusion(nn.Module): def __init__(self, d_img, d_txt, d_audio, num_classes): super(ModalAttentionFusion, self).__init__() # 各模态特征降维(统一到同一维度) self.fc_img = nn.Linear(d_img, 256) self.fc_txt = nn.Linear(d_txt, 256) self.fc_audio = nn.Linear(d_audio, 256) # 模态注意力层 self.attention = nn.Sequential( nn.Linear(256, 128), nn.ReLU(), nn.Linear(128, 1) ) # 最终分类层(淘宝用HMC分层分类,这里简化为单分类) self.fc_out = nn.Linear(256, num_classes) def forward(self, img_feat, txt_feat, audio_feat): # 各模态特征降维 img = self.fc_img(img_feat) # (bs, 256) txt = self.fc_txt(txt_feat) # (bs, 256) audio = self.fc_audio(audio_feat) # (bs, 256) # 计算各模态注意力权重 alpha_img = self.attention(img) # (bs, 1) alpha_txt = self.attention(txt) # (bs, 1) alpha_audio = self.attention(audio) # (bs, 1) # softmax归一化权重 alphas = torch.softmax(torch.cat([alpha_img, alpha_txt, alpha_audio], dim=1), dim=1) # (bs, 3) # 加权融合 fusion_feat = img * alphas[:, 0:1] + txt * alphas[:, 1:2] + audio * alphas[:, 2:3] # (bs, 256) # 分类输出 return self.fc_out(fusion_feat) # (bs, num_classes)
⑤对抗多模态融合(Adversarial Multimodal Fusion)
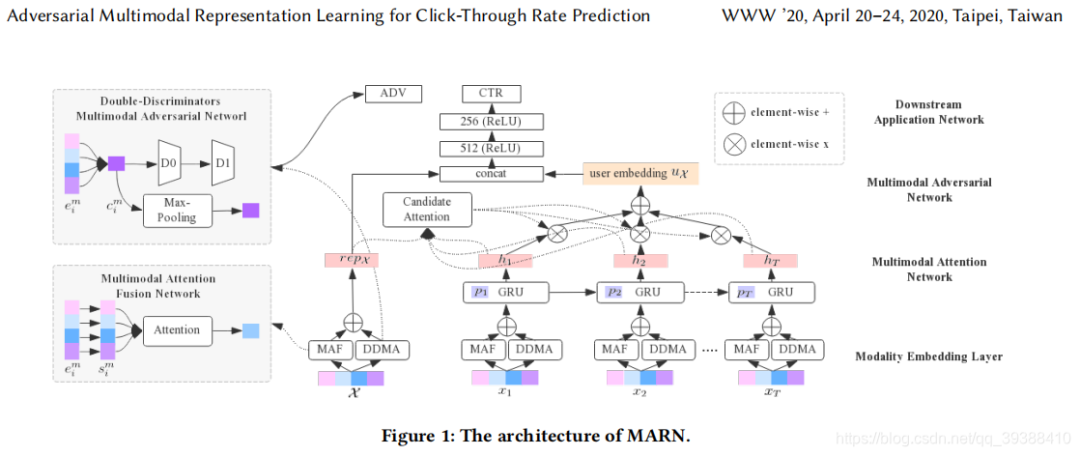
原理
对抗融合是阿里在 WWW 2020 提出的方法,核心是用 “双判别器” 分离多模态的 “共性特征”(各模态共有的信息,如商品的 “类别属性”)和 “个性特征”(某模态独有的信息,如图像的 “颜色细节”),再融合两类特征用于下游任务(如点击率预估)。
核心结构
- 多模态注意力融合(MAF):基础融合模块,得到初步融合特征;
- 双判别器(DDMA):
- 模态判别器(D1):区分特征来自哪个模态,迫使模型学习 “模态不变的共性特征”;
- 重要性判别器(D2):判断特征的重要性,优化模态权重分配;
- 对抗训练:通过生成器(融合模块)与判别器的对抗,提升融合特征的鲁棒性。
优缺点
- 优点:能有效分离共性与个性特征,避免模态冗余;对抗训练提升模型泛化能力。
- 缺点:对抗训练不稳定,需精细调参;模型复杂度高,适合大数据场景。
适用场景
多模态点击率预估、推荐系统(如阿里电商广告 CTR 预测)。
⑥多项式张量池化(PTP:Polynomial Tensor Pooling)
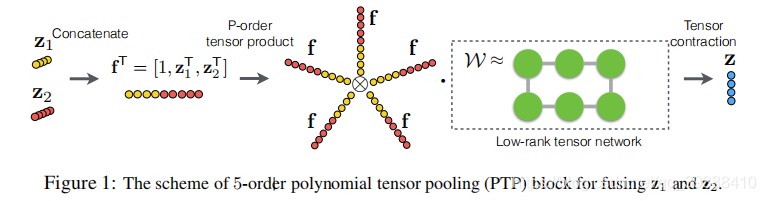
原理
PTP 是针对传统双线性 / 三线性池化 “融合能力有限、无法捕捉复杂局部交互” 问题提出的高阶融合方法,核心是通过 “多项式张量运算” 集成多模态特征的高阶矩(如二阶、三阶统计信息),同时引入低秩分解减少参数规模。相比 TFN 仅关注模态间的直接交叉,PTP 能捕捉更复杂的局部相互关系,比如文本中的 “情感词” 与图像中的 “表情区域”+“色彩饱和度” 的三阶交互。
核心公式

优缺点
- 优点:能捕捉多模态特征的高阶交互,融合表现力更强;低秩分解有效控制参数规模,避免维度爆炸;
- 缺点:高阶张量运算的理论理解和工程实现难度较高;对数据量要求大,小样本场景下易过拟合。
适用场景
需要精细捕捉多模态复杂交互的任务,如细粒度图像 - 文本匹配(如 “红色带花纹的连衣裙” 与对应商品图匹配)、多模态细分类别识别(如区分 “愤怒的猫” 和 “开心的猫”)。
核心代码示例(PyTorch)
import torchimport torch.nn as nnimport torch.nn.functional as Fclass PTPBlock(nn.Module): def __init__(self, in_dim, poly_order=3, low_rank_dim=128): super(PTPBlock, self).__init__() self.poly_order = poly_order # 多项式阶数(如3阶) self.in_dim = in_dim # 多项式特征生成:通过线性层模拟高阶矩展开 self.poly_proj = nn.Linear(in_dim, in_dim * poly_order) # 低秩分解层:将高阶特征映射到低维空间 self.low_rank_proj = nn.Linear(in_dim * poly_order, low_rank_dim) self.norm = nn.BatchNorm1d(low_rank_dim) # BatchNorm稳定训练 def forward(self, z1, z2): # 1. 拼接多模态特征 concat_feat = torch.cat([z1, z2], dim=1) # (bs, in_dim1 + in_dim2) # 2. 生成多项式特征(模拟高阶矩) poly_feat = self.poly_proj(concat_feat) # (bs, (d1+d2)*poly_order) poly_feat = F.relu(poly_feat) # 非线性激活增强表达 # 3. 低秩分解得到融合特征 fusion_feat = self.low_rank_proj(poly_feat) # (bs, low_rank_dim) fusion_feat = self.norm(fusion_feat) # 归一化 return fusion_feat# 测试if __name__ == "__main__": bs = 32 # batch_size d1, d2 = 64, 128 # 两种模态特征维度(如图像、文本) z1 = torch.randn(bs, d1) z2 = torch.randn(bs, d2) ptp = PTPBlock(in_dim=d1+d2, poly_order=3, low_rank_dim=128) fusion_feat = ptp(z1, z2) print("PTP融合特征形状:", fusion_feat.shape) # 输出 (32, 128)
⑦多模态循环融合(MCF:Multi-modal Circulant Fusion)
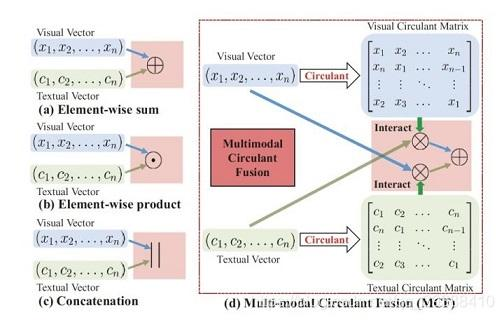
原理
MCF 突破传统 “仅基于向量融合” 的思路,同时利用 “向量” 和 “循环矩阵(Circulant Matrix)” 进行融合,核心是通过 “循环矩阵变换” 探索多模态向量的所有可能交互。具体来说,将每种模态的向量转换为循环矩阵(每行是原向量的循环移位),再通过矩阵与向量的交互运算,捕捉模态间的全局关联,尤其适合视频 - 文本这类需全局时序匹配的任务。
核心公式

优缺点
- 优点:通过循环矩阵捕捉模态间的全局交互,避免局部信息遗漏;无需复杂注意力机制,计算效率较高;
- 缺点:循环矩阵变换依赖向量维度一致性(需先对齐模态特征维度);对短向量特征的交互捕捉效果有限。
适用场景
视频 - 文本融合任务(如视频描述生成、视频文本检索)、长序列多模态匹配(如多段文本与多帧图像的关联)。
⑧共享 - 私有特征融合(Shared-Private Fusion)
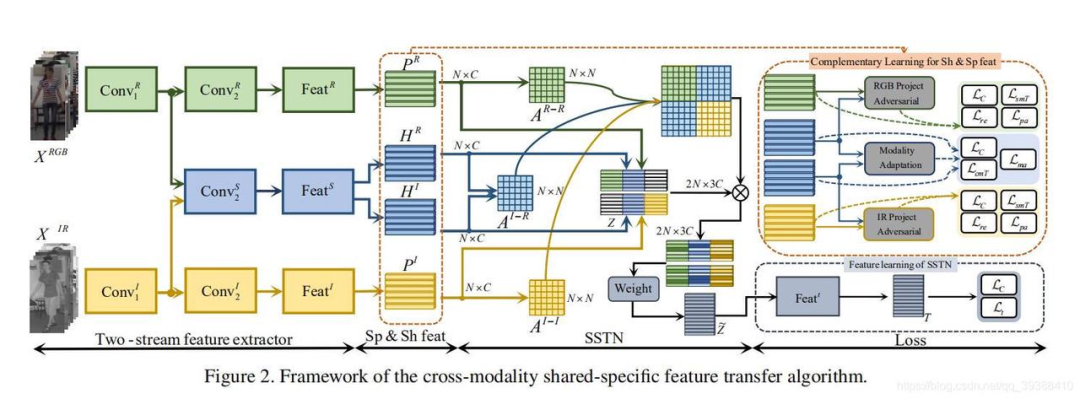
原理
该方法针对 “多模态特征中既有共性信息(各模态共通,如‘猫’的语义),又有私有信息(某模态独有,如图像中‘猫的毛色’、文本中‘猫的品种’)” 的特点,通过分离并融合 “共享特征” 和 “私有特征”,避免共性信息冗余、私有信息丢失。典型代表包括 ACL 2020 的 FP-Net 和 ACL 2021 的 Text-Centered 框架,核心是通过 “正交投影” 或 “掩码矩阵” 实现两类特征的分离。
核心公式(以 FP-Net 为例)

优缺点
- 优点:精准分离共性与私有信息,充分利用模态互补性;对模态异质性的容忍度高,适合多模态协同任务;
- 缺点:特征分离依赖高质量的共享特征初始化(如预训练模型提取的通用特征);正交投影计算需保证数值稳定性。
适用场景
多模态情感分析(文本表达情感倾向,图像 / 语音补充情感强度)、跨模态迁移学习(用图像的共享语义辅助文本分类)、行人重识别(RGB 与红外图像的共性轮廓 + 私有纹理融合)。
核心代码示例(PyTorch)
class FPNetSharedPrivate(nn.Module): def __init__(self, text_dim, img_dim, shared_dim=256): super(FPNetSharedPrivate, self).__init__() # 共享特征提取器(文本和图像共享) self.shared_proj = nn.Linear(max(text_dim, img_dim), shared_dim) # 文本私有特征投影层 self.text_private_proj = nn.Linear(text_dim, text_dim) # 图像私有特征投影层 self.img_private_proj = nn.Linear(img_dim, img_dim) # 最终融合输出层 self.fusion_out = nn.Linear(shared_dim + text_dim + img_dim, 10) # 10分类示例 def orthogonal_proj(self, x, target): # 正交投影:将x投影到target所在空间 target_norm = torch.norm(target, dim=1, keepdim=True) + 1e-8 # 避免除零 proj_coeff = (x @ target.T) / (target_norm ** 2) # (bs, bs) proj = proj_coeff @ target # (bs, shared_dim) return proj def forward(self, text_feat, img_feat): # 1. 提取共享特征(统一模态维度后投影) max_dim = max(text_feat.shape[1], img_feat.shape[1]) text_pad = F.pad(text_feat, (0, max_dim - text_feat.shape[1])) # 对齐维度 img_pad = F.pad(img_feat, (0, max_dim - img_feat.shape[1])) shared_feat = self.shared_proj(torch.cat([text_pad, img_pad], dim=0)).mean(dim=0, keepdim=True) shared_feat = shared_feat.expand(text_feat.shape[0], -1) # (bs, shared_dim) # 2. 提取文本私有特征 text_shared_proj = self.orthogonal_proj(text_feat, shared_feat) # 文本的共享部分 text_private = self.text_private_proj(text_feat - text_shared_proj) # 私有部分 # 3. 提取图像私有特征 img_shared_proj = self.orthogonal_proj(img_feat, shared_feat) # 图像的共享部分 img_private = self.img_private_proj(img_feat - img_shared_proj) # 私有部分 # 4. 融合共享与私有特征 fusion_feat = torch.cat([shared_feat, text_private, img_private], dim=1) # (bs, shared_dim + text_dim + img_dim) return self.fusion_out(fusion_feat) # (bs, 10)# 测试if __name__ == "__main__": bs = 32 text_dim, img_dim = 128, 256 text_feat = torch.randn(bs, text_dim) img_feat = torch.randn(bs, img_dim) fp_net = FPNetSharedPrivate(text_dim, img_dim, shared_dim=256) out = fp_net(text_feat, img_feat) print("FP-Net输出形状:", out.shape) # 输出 (32, 10)
⑨注意力瓶颈融合(Attention Bottleneck Fusion)
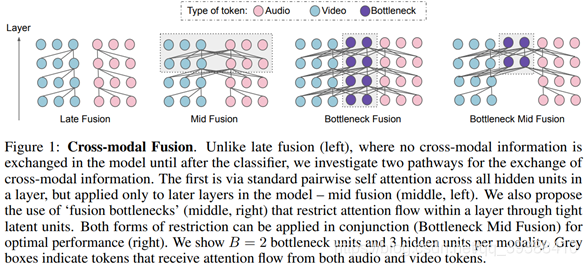
原理
针对传统 Transformer 跨模态融合 “计算量过大” 的问题,注意力瓶颈融合通过引入 “共享令牌(Shared Token)” 作为模态交互的 “瓶颈”,限制注意力流仅在共享令牌处进行跨模态交互,而非所有 token 间的全量交互。这种设计在保证融合效果的同时,大幅降低计算复杂度,尤其适合高分辨率图像、长文本这类大尺度多模态数据。
核心结构
- 模态独立编码:文本用 Transformer Encoder 编码为文本令牌(Text Token),图像用 ViT 编码为视觉令牌(Vision Token);
- 共享令牌插入:在两类令牌中插入 1-2 个共享令牌(如
[SHARED]); - 瓶颈注意力交互:仅允许共享令牌与所有文本 / 视觉令牌进行注意力计算,文本与视觉令牌之间不直接交互;
- 融合特征生成:提取共享令牌的特征,与各模态的全局池化特征拼接,得到最终融合结果。
优缺点
- 优点:计算复杂度低(O ((N+M+K)^2 ) 降至 O ( (N+M) K + K^2 ),N/M 为模态令牌数,K 为共享令牌数);共享令牌能有效聚合跨模态信息,融合效果接近全注意力;
- 缺点:共享令牌数量需手动调整(过多易冗余,过少易丢失信息);对模态令牌的初始化质量敏感。
适用场景
大尺度多模态任务(如高分辨率图像 - 长文本匹配、多模态文档理解)、资源受限场景(如移动端多模态分类)。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2677
2677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









