







我们在机器学习中常涉及多个维度,有些数据的量级不同,会导致数据范围波动很大,比如我们研究肿瘤的数据,肿瘤周长可以达到10多cm,而肿瘤的凹度只有零点几cm,两者数据间差异比较大,在进行比较的时候通常需要消除数据间的差异。常见的方法为对数据进行标准化和归一化处理。

标准化就是把数据减去同一列的平均值,然后再除以标准差,公式如下:
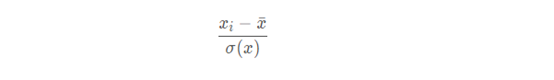
归一化就是把数据减去同列数据的最小值,然后再除以同列数据最小值和最大值的差值,公式如下:
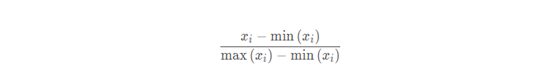
我们通过R语言来实现下面两种数据处理方法,先导入我们的一个乳腺癌的肿瘤指标数据(不是原来乳腺癌的数据, 公众号回复:KNN数据,可以获得数据),
bc<-read.csv("E:/r/test/wdbc.csv",sep=',',header=TRUE)


这是一个关于肿瘤数据,第一列是患者编号,第二列表示肿瘤是否是恶性的(M是恶性,B是良性),其他都是肿瘤的参数,有周长,直径,光滑度,凹凸点等数据,共有32个参数,有些数据很大20.5cm,有些才0.08cm。
我们先把编号和去掉
bc<-bc[-1]
在R中进行数据标准化很简单,直接使用scale命令就可以了
be<-scale(bc[2:31])

这样标准化就完成了,我们可以看到数据被进行了压缩,数据间的差距变小了,具有可比性。
下面我们继续进行归一化数据处理,归一化没有专门的程序,我们先自己设置一个程序,然后使用lapply函数实现
f1<-function(x){
return((x-min(x)) / (max(x)-min(x)))
}
然后把数据带入自己设定的函数
be<-as.data.frame(lapply(bc[2:31],f1))

这样,我们的数据归一化也完成了,目前在机器学习中这两种数据方法使用较多,一般来说正态分布数据使用标准化较多,如果是非正常态分布数据,使用归一化较多。

















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











