






我是娜姐 @迪娜学姐 ,一个SCI医学期刊编辑,探索用AI工具提效论文写作和发表。

论文的统计分析部分,是难点,也是审稿人比较关注的地方。娜姐发现,审稿人经常会对统计学方法的选择、分组情况、统计学结果解释等提出质疑或改进建议。如果不能清晰的进行解释或有效改进,很可能在复审时被拒稿。
Elife这篇文章总结了论文中常见的10个统计学错误,错误根源在于无效的实验设计、不当的分析或有缺陷的推理,不同的错误类型常常相互依存,一个错误可能会导致其他的错误类型。

https://elifesciences.org/articles/48175
一起来看看这10大错误你有没有犯:
1 缺乏充分的对照条件/组:
问题:缺乏适当的对照组可能导致结果被误解。没有对照组,研究者可能无法确定观察到的效应是由实验操作引起的,还是由其他随时间变化的因素导致的,进而导致错误地将非因果关系解释为因果关系。
表现形式:
结论是根据单组数据得出的,没有足够的对照条件。
2 在没有直接比较的情况下解释两种效应之间的差异:
问题:研究者可能基于一组显示显著效应而另一组没有显示显著效应就得出两组之间存在差异的结论,而实际上并没有对这两组进行直接的统计比较。这种做法可能导致错误的结论,因为两组之间的差异可能并不显著。
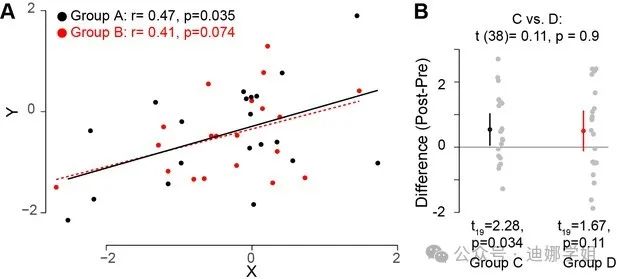
图1 A)两个变量X和Y,在A和B两组中进行测量。很明显,这两个变量之间的相关关系在这两组测量中都没有区别。然而,如果计算皮尔逊相关系数r的显著性,将两个相关系数与0相比较,却可能得到一个组(组A;黑色圆点;n=20)的相关性在统计学上显著(基于p≦0.05的阈值),而另一个组(组B;红色圆点;n=20)不显著。然而,这并不说明变量X和Y之间的相关关系在两组之间不同。可以用蒙特卡罗模拟来比较两个组的相关关系(Wilcox and Tian, 2008)。(B)在实验研究的情境中,可以看到两组之间在某一特定测量结果上的差异(例如,训练前后的差异)。组C和D的均值相同,但是D组的方差更大。如果使用独立样本t检验将每一组的结果指标分别与0比较,会发现一组的变量与0之间有显著差异(组C;左侧;n=20),但是另一组不存在显著差异(组D ;右侧;n=20)。然而,这并不能说明两个组的测量结果存在不同。这时应该使用未配对样本t检验(顶部)直接比较两个组:结果表明两组的测量结果没有差异。
表现形式:
当在没有对两种效果用统计学方法进行直接比较的情况下,就得出关于两种效果之间差异的结论时,就会出现这个问题。
解决方案:
进行组间比较时,应直接比较各组。两组的相关关系可以用蒙特卡罗模拟进行比较(Wilcox and Tian, 2008)。对于多组比较,可能适合用ANOVA。非参数统计也提供了一些方法(Leys and Schumann, 2010),需要根据具体情况使用。
3 夸大分析单位:
问题:错误地增加分析单位(如将重复测量视为独立观察)可能导致自由度(df)人为增加,从而更容易达到统计显著性。这种做法可能导致I类错误率增加,产生虚假的显著结果。
表现形式:
应考虑适当的分析单位。如果一项研究旨在了解群体效应,那么分析单位应反映受试者之间的差异,而不是受试者内部的差异。
4 虚假相关性:
问题:虚假相关可能由异常值或不恰当地将不同组的数据合并在一起而产生。这种情况下,观察到的相关可能并不反映真实的关系,而是由数据处理或分组方式导致的统计假象。
表现形式:
注意数据呈现是不带有散点图的相关性,并考虑在丢弃数据点时是否提供了足够的理由。
5 使用小样本:
问题:小样本研究可能导致效应量被高估、假阳性风险增加,以及降低检测真实效应的能力。小样本量降低了统计检验的功效,增加了II类错误的可能性,同时也可能导致研究结果不具有代表性。
表现形式:
审稿人应该严格检查论文中使用的样本量,并判断样本量是否足够。
6. 循环分析:
问题:循环分析是指回顾性地选择数据特征来描述因变量,从而导致统计检验结果失真。这种做法通常涉及重复使用相同的数据来定义测试变量并进行统计推断,因此也被称为"双重利用"。这可能会导致统计结果的人为膨胀和无效的统计推断。
表现形式:
循环分析有多种不同的形式,但原则上只要统计检验措施因选择标准而偏向于所检验的假设,就会发生循环分析。在某些情况下非常清楚,例如如果分析基于为显示感兴趣的效应或固有相关效应而选择的数据。在其他情况下,分析可能会很复杂,需要对选择和分析步骤之间的相互依赖性有更细致的了解。审稿人应该警惕不可能的高效应量,这在理论上可能不合理,和/或基于相对不可靠的测量(如果两个测量的内部一致性较差,这会限制识别有意义的相关性的潜力;Vul et al., 2009) 。在这种情况下,审稿人应该要求作者就选择标准和利益影响之间的独立性提供理由。
7. 分析方法的多样性(p-hacking):
问题:在数据分析中过度灵活(如切换结果参数、添加协变量、不确定的预处理流程、事后排除异常值或受试者等)会增加获得显著p值的概率。这种做法可能导致观察到的效应并非真实存在。
表现形式:
分析方法的多样性很难检测,因为研究人员很少披露所有必要的信息。在预注册或临床试验注册的情况下,审评者应将进行的分析与计划的分析进行比较。在没有预先注册的情况下,几乎不可能检测到某些形式的 p-hacking。然而,审稿人可以估计所有的分析选择是否合理,以前的出版物中是否使用了相同的分析计划,研究人员是否提出了一个有问题的新变量,或者他们是否收集了大量的信息但只选择性披露了一部分。
8. 未进行多重比较校正:
问题:在进行多重比较时(特别是在探索性分析中),如果不进行适当的校正,会增加发现虚假阳性结果(I类错误)的概率。这在涉及多个因素或多个独立比较(如神经影像分析)的实验设计中尤为明显。
表现形式:
通过处理测量的自变量的数量和执行的分析的数量,可以检测到未能纠正多重比较。如果这些变量中只有一个与因变量相关,则可能已包含其余变量以增加获得显着结果的机会。因此,当对大量变量(例如基因或 MRI 体素)进行探索性分析时,研究人员在没有明确理由的情况下解释未经多重比较校正的结果是完全不可接受的。即使研究人员提供了一个粗略的预测(例如,应该在特定的大脑区域或在大约的潜伏期观察到效果),如果可以通过多次独立比较来测试该预测,则需要对多重比较进行校正。
9. 过度解释非显著性结果:
问题:非显著的p值并不能区分效应客观不存在(与假设相矛盾的证据)和数据不敏感(如统计功效不足、实验设计不当等)这两种情况。仅凭p值无法充分解释非显著结果的含义,可能导致忽视重要的初步证据或错误地将非显著结果解释为支持假设的证据。
表现形式:
将不显著的P值(>0.05)描述为效果不存在,此类错误非常常见。
10. 混淆相关性和因果关系:
问题:当发现两个变量之间存在显著相关时,研究者可能会错误地假设它们之间存在因果关系。然而,相关性并不意味着因果关系。相关的现象可能反映直接或反向因果关系,也可能由未知的共同原因导致,或仅仅是巧合。
掌握以上10种统计分析的谬误类型并注意避免,对于提高研究的可靠性和有效性至关重要。

















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









