







 本文介绍如何将PyTorch模型转换为Caffe模型,并详细讲解了Caffe的基本组件及其工作原理,包括Blob、Layer、Net等内容。此外还介绍了如何修改prototxt文件及caffemodel,实现BN层和batchnorm+scale层之间的转换。
本文介绍如何将PyTorch模型转换为Caffe模型,并详细讲解了Caffe的基本组件及其工作原理,包括Blob、Layer、Net等内容。此外还介绍了如何修改prototxt文件及caffemodel,实现BN层和batchnorm+scale层之间的转换。
背景
pytorch转onnx后,onnx转tensorRT 各种问题。主要是TX2安装的tensorRT版本较低,也没有去刷机升级的想法。
尝试了 onnx-tensorRT 以及torch2trt 项目,完全没心思搞了。
还是按照标准流程 转caffe 然后部署到tensorRT ,TX2也有官方支持的caffe的脚本。
文章目录
参考
1、Pytorch模型转Caffe模型小记
https://zhuanlan.zhihu.com/p/352750171
得到了pytorch2caffe工具: github.com/woodsgao/pytorch2caffe
2、 Caffe(一)解析caffemodel与prototxt
https://www.cnblogs.com/wangxiaobei2019/p/14145040.html
了解caffe的框架
Caffe简介

2.Caffe进行目标检测任务
利用ssd进行目标检测任务,主要步骤如下(重点是模型的移植)
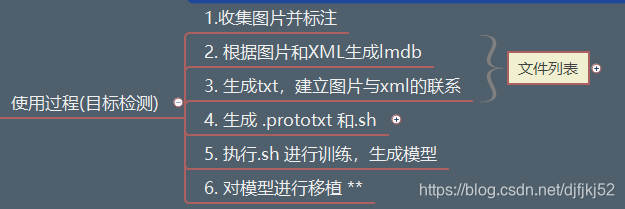
3.Caffe五大组件

其中,
1、Blob:存储和传递(communication)blob是数据存储和传输的包装,并且还在底层提供CPU和GPU之间的同步能力。Blob提供了保存数据的统一存储器接口; 例如图像批次,模型参数和用于优化的导数。
- 在数学上,blob是以C连续方式(C-contiguous fashion)存储的N维数组。
- 关于C连续方式,stackoverflow有一个解释。该方式主要与Fortran和Matlab相反,是一种以行为主顺序(Row-major order)的存储方式,简单的说就是把一行存完,再存下一行,把第一个通道(channel)的所有行写完后写完再写下一个通道。
- 例如对一批(batches)图像,用4维blob存储,表示为number N(数据批量大小) x channel K(通道、维度特征) x height H (高)x width W(宽),对于索引 (n, k, h, w) 的物理地址就是:((n * K + k) * H + h) * W + w,注意区分大小写,大写是总的,小写是索引值。
- 对于图像是4D的,当然也可以不用4D。具体参数需要根据层类型和数据大小配置。
- blob使用了两块存储区域,为data(数据)和diff(网络梯度),实际值可以存储在CPU或GPU上,访问也可以不变(const)访问或者可变(mutable)访问。
const Dtype* cpu_data() const;
Dtype* mutable_cpu_data();
同理可得GPU上diff类型数据操作。
2、Layer计算和连接
Layer包括很多计算方法,如
Vision Layers:Convolution、Pooling、LRN
Loss Layers:Softmax、Sum-of-Squares
既然作为计算,就有输入输出,输入从底部(bottom)获取,并通过顶部(top)连接输出。每层须有三个关键计算:setup, forward, and backward。
setup:初始化层和连接。
forward:底部向顶部计算。
backward:给定梯度,从top计算传回bottom。
forward和backward也分为CPU和GPU两个版本。
3、Net定义和操作
Net由Layer组成。
- 模型初始化由Net :: Init()处理:主要是创建blob和layer,并调用layer里的setup,同时会输出INFO。
4、模型格式
模型定义在.prototxt文件中,训练好的模型在model目录下.binaryproto格式的文件中,模型的格式由caffe.proto定义。
4.caffemodel
包含了prototxt 和 weights bias
5. caffe:生成、修改prototxt及caffemodel
https://blog.csdn.net/qq_34440148/article/details/104795572
通过创建caffe_pb2.NetParameter()对象,获取caffemodel内容
1.读取prototxt
from caffe.proto import caffe_pb2
from google.protobuf import text_format
net = caffe_pb2.NetParameter()
solver = caffe_pb2.SolverParameter()
f1=open('deploy.prototxt')
f2=open('solver.prototxt')
text_format.Merge(f1.read(), net) #把文本内容读进
text_format.Merge(f2.read(), solver)
layers = net.layer #众多层的内容,理解为list
l = layers[0] #取其中一层
#以下为各变量读取方法
l.name
l.type
l.bottom
l.top
l.convolution_param.num_output
#后面类比一样方法。solver的操作方法一样
2.修改prototxt
比如我要修改某层的名字,并另存为新的prototxt,操作如下,代码接上面:
net.layer[0].name = 'hello'
f = open('new.prototxt', 'w')
f.write(str(net))
f.close()
这样根据索引修改层有点麻烦。比如我想要把一个名为conv1的卷积层的kernel_size修改为5,怎么办?代码接上面:
dic_name = {} #根据名字对各层建立字典
layers = net.layer
for l in layers:
dic_name[str(l.name)]=l
dic_name['conv1'].convolution_param.kernel_size = 5
#这个kernel_size,包括所有的数值型参数,如pad等等,直接显示是 7L,
#通过type查看类型是long长整型。看的有点奇怪,但是可以像上面正常赋值,赋值之后变为5L。
同样,可以根据各自的需求,根据type、bottom、top建立字典。
3.读取caffemodel各层权重及中间blobs数值、形状
import caffe
model = caffe.Net('deploy.prototxt','m.caffemodel',caffe.TEST)
#注:这里是根据deploy的层来读取的。如果deploy没有的层而caffemodel有的层,是不会读进来的
#根据这个原理,分类模型的预训练模型,就要把最后的全连接层去掉,因为用于finetune的数据集类别数不一样。
#deploy去掉全连接层读取后,再model.save('caffemodel')即可得到预训练模型
#此处存放的是所有“有参数的层”的名字,无参数层如relu等不会进来
layer_names = model.params.keys()
#以卷积层为例
weight = model.params['conv1'][0].data #是numpy数组,形状用shape查看
bias = model.params['conv1'][1].data
#此处存放的是所有blob的名字
blob_names = model.blobs.keys()
blob = model.blobs['blob1'].data #是numpy数组,形状用shape查看
4.从caffemodel读取prototxt的内容
from caffe.proto import caffe_pb2
net = caffe_pb2.NetParameter()
f=open('m.caffemodel','rb') #这里注意,要用rb模式,就是二进制读入
net.ParseFromString(f.read())
#下面操作与第一部分一样,建立字典
layers = net.layer
dic_name = {}
for l in layers:
dic_name[str(l.name)] = l
直接显示dic_name[‘conv1_7x7_s2’],输出如下
①BN层改为batchnorm+scale
改prototxt:
https://blog.csdn.net/qq_34440148/article/details/104795572
caffemodel参数移动
#coding=UTF-8
import sys
sys.path.insert(0,'/home/cdli/ECO2/caffe_3d/python')
import caffe
import numpy as np
import cv2
import scipy.io as sio
caffe.set_device(0)
caffe.set_mode_gpu()
deploy1='../deploy-lite-8-permute-batchnorm.prototxt'
deploy2='/home/cdli/ECO/model/lite/8fpermute/deploy-lite-8-permute.prototxt'
#model1='base.caffemodel'
model2='/home/cdli/ECO/model/lite/8fpermute/parse/after.caffemodel'
net1=caffe.Net(deploy1,caffe.TEST)
net2=caffe.Net(deploy2,model2,caffe.TEST)
net_layer1=net1.params.keys()
net_layer2=net2.params.keys()
net_blob1=net1.blobs.keys()
net_blob2=net2.blobs.keys()
for l in net_layer2:
print l
if 'bn' in l:
batchnorm_name=l.replace('_bn','/BatchNorm')
scale_name=l.replace('_bn','/scale')
bn=net2.params[l]
scale_=bn[0].data.reshape((-1,)) #BN参数
bias_=bn[1].data.reshape((-1,))
mean_=bn[2].data.reshape((-1,))
var_=bn[3].data.reshape((-1,))
batchnorm=net1.params[batchnorm_name]
scale=net1.params[scale_name]
batchnorm[0].data[:]=mean_[:] #移参数
batchnorm[1].data[:]=var_[:]
batchnorm[2].data[:]=1.0
scale[0].data[:]=scale_[:]
scale[1].data[:]=bias_[:]
else:
layer1=net1.params[l]
layer2=net2.params[l]
layer1[0].data[:]=np.copy(layer2[0].data)
layer1[1].data[:]=np.copy(layer2[1].data)
input1=np.zeros(shape=(224,224,3,8),dtype=np.float64)
input2=np.zeros(shape=(240,320,3),dtype=np.float64)
d = sio.loadmat("../rgb_mean.mat")
image_mean = d['image_mean'] # 224 224 3
lis=[]
for i in range(0,8):
img=cv2.imread('img/img_000'+str(i+1)+'.jpg')
img_reshape=img[16:240,60:284,:]-image_mean
input1[:,:,:,i]=img_reshape
lis.append(img_reshape)
if i==0:
input2=img_reshape
else:
input2=np.append(input2,img_reshape,axis=2)
# 输入数据确定
p=8
input2=input2[...,None]
input1=np.transpose(input1[:,:,:,:],(3,2,1,0)) #8 3 224 224
input2=np.transpose(input2[:,:,:,:],(3,2,1,0)) #1 24 224 224
input_minus=(input1[p-1,:,:,:]-input2[0,3*(p-1):3*p,:,:]).sum()
net1.blobs['data'].data[...]=input2
net2.blobs['data'].data[...]=input2
output1=net1.forward()
output2=net2.forward()
print 'out1=',output1
print 'out2=',output2
net1.save('after.caffemodel')
②batchnorm+scale转换为BN
修改prototxt:
https://blog.csdn.net/qq_34440148/article/details/104795572

















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









