







https://zhuanlan.zhihu.com/p/52471966
https://zhuanlan.zhihu.com/p/52616166
https://zhuanlan.zhihu.com/p/356625894
文章目录
关于NAS
CNN和RNN是目前主流的CNN框架,这些网络均是由人为手动设计,然而这些设计是非常困难以及依靠经验的。作者在这篇文章中提出了使用强化学习(Reinforcement Learning)学习一个CNN(后面简称NAS-CNN)或者一个RNN cell(后面简称NAS-RNN),并通过最大化网络在验证集上的精度期望来优化网络,在CIFAR-10数据集上,NAS-CNN的错误率已经逼近当时最好的DenseNet[2],在TreeBank数据集上,NAS-RNN要优于LSTM。
1. 背景介绍
文章提出了Neural Architecture Search(NAS),算法的主要目的是使用强化学习寻找最优网络,包括一个图像分类网络的卷积部分(表示层)和RNN的一个类似于LSTM的cell。由于现在的神经网络一般采用堆叠block的方式搭建而成,这种堆叠的超参数可以通过一个序列来表示。而这种序列的表示方式正是RNN所擅长的工作。
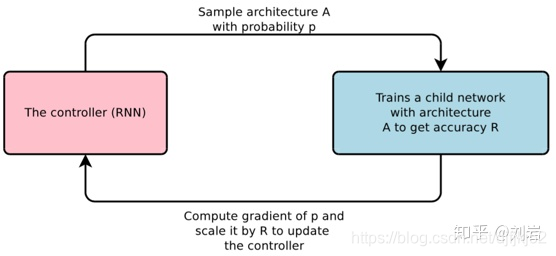
所以,NAS会使用一个RNN构成的控制器(controller)以概率 [公式] 随机采样一个网络结构 [公式] ,接着在CIFAR-10上训练这个网络并得到其在验证集上的精度 [公式] ,然后在使用 [公式] 更新控制器的参数,如此循环执行直到模型收敛,如图1所示。
2. NAS详细介绍
2.1 NAS-CNN
首先我们考虑最简单的CNN,即只有卷积层构成。那么这种类型的网络是很容易用控制器来表示的。即将控制器分成 N 段,每一段由若干个输出,每个输出表示CNN的一个超参数,例如Filter的高,Filter的宽,横向步长,纵向步长以及Filter的数量,如图2所示。
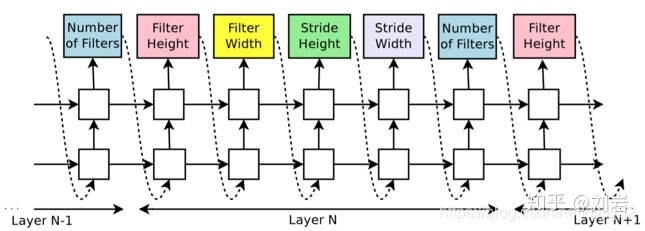
了解了控制器的结构以及控制器如何生成一个卷积网络,唯一剩下的也是最终要的便是如何更新控制器的参数
上面得到的控制器的搜索空间是不包含跳跃连接(skip connection)的,所以不能产生类似于ResNet或者Inception之类的网络。NAS-CNN是通过在上面的控制器中添加注意力机制[4]来添加跳跃连接的,如图3。
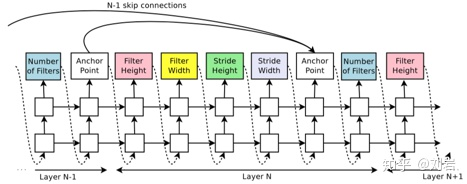
由于添加了跳跃连接,而由训练得到的参数可能会产生许多问题,例如某个层和其它所有层都没有产生连接等等,所以有几个问题我们需要注意:
如果一个层和其之前的所有层都没有跳跃连接,那么这层将作为输入层;如果一个层和其之后的所有层都没有跳跃连接,那么这层将作为输出层,并和所有输出层拼接之后作为分类器的输入;如果输入层拼接了多个尺寸的输入,则通过将小尺寸输入加值为0的padding的方式进行尺寸统一。
除了卷积和跳跃连接,例如池化,BN,Dropout等策略也可以通过相同的方式添加到控制器中,只不过这时候需要引入更多的策略相关参数了。
从图4我们可以发现NAS-CNN和DenseNet有很多相通的地方:
- 都是密集连接;
- Feature Map的个数都比较少;
- Feature Map之间都是采用拼接的方式进行连接。
2.2 NAS-RNN
在这篇文章中,作者采用强化学习的方法同样生成了RNN中类似于LSTM或者GRU的一个Cell。控制器的参数更新方法和1.2节类似,这里我们主要介绍如何使用一个RNN控制器来描述一个RNN cell。
在如何使用强化学习方面,谷歌一直是领头羊,除了他们具有很多机构难以匹敌的硬件资源之外,更重要的是他们拥有扎实的技术积累。本文开创性的使用了强化学习进行模型结构的探索,提出了NAS-CNN和NAS-RNN两个架构,两个算法的共同点都是使用一个RNN作为控制器来描述生成的网络架构,并使用生成架构在验证集上的表现并结合强化学习算法来训练控制器的参数。
本文的创新性可以打满分,不止是其算法足够新颖,更重要的是他们开辟的使用强化学习来学习网络架构可能在未来几年引网络模型自动生成的方向,尤其是在硬件资源不再那么昂贵的时候。文章的探讨还比较基础,留下了大量的待开发空间为科研工作者所探索,期待未来几年出现更高效,更精确的模型的提出。
NASNet
为了将NAS迁移到大数据集乃至ImageNet上,这篇文章提出了在小数据(CIFAR-10)上学习一个网络单元(Cell),然后通过堆叠更多的这些网络单元的形式将网络迁移到更复杂,尺寸更大的数据集上面。因此这篇文章的最大贡献便是介绍了如何使用强化学习学习这些网络单元。作者将用于ImageNet的NAS简称为NASNet,文本依旧采用NASNet的简称来称呼这个算法。实验数据也证明了NASNet的有效性,其在ImageNet的top-1精度和top-5精度均取得了当时最优的效果。
1.1 NASNet 控制器
在NASNet中,完整的网络的结构还是需要手动设计的,NASNet学习的是完整网络中被堆叠、被重复使用的网络单元。为了便于将网络迁移到不同的数据集上,我们需要学习两种类型的网络块:(1)Normal Cell:输出Feature Map和输入Feature Map的尺寸相同;(2)Reduction Cell:输出Feature Map对输入Feature Map进行了一次降采样,在Reduction Cell中,对使用Input Feature作为输入的操作(卷积或者池化)会默认步长为2。
1.2 NASNet的强化学习
NASNet的强化学习思路和NAS相同,有几个技术细节这里说明一下:
NASNet进行迁移学习时使用的优化策略是Proximal Policy Optimization(PPO)[3];作者尝试了均匀分布的搜索策略,效果略差于策略搜索。
1.3 Scheduled Drop Path
在优化类似于Inception的多分支结构时,以一定概率随机丢弃掉部分分支是避免过拟合的一种非常有效的策略,例如DropPath[4]。但是DropPath对NASNet不是非常有效。在NASNet的Scheduled Drop Path中,丢弃的概率会随着训练时间的增加线性增加。这么做的动机很好理解:训练的次数越多,模型越容易过拟合,DropPath的避免过拟合的作用才能发挥的越有效。
1.4 其它超参
在NASNet中,强化学习的搜索空间大大减小,很多超参数已经由算法写死或者人为调整。这里介绍一下NASNet需要人为设定的超参数。
- 激活函数统一使用ReLU,实验结果表明ELU nonlinearity[5]效果略优于ReLU;
- 全部使用Valid卷积,padding值由卷积核大小决定;
- Reduction Cell的Feature Map的数量需要乘以2,Normal Cell数量不变。初始数量人为设- 定,一般来说数量越多,计算越慢,效果越好;
- Normal Cell的重复次数(图3中的 [公式] )人为设定;
- 深度可分离卷积在深度卷积和单位卷积中间不使用BN或ReLU;
- 使用深度可分离卷积时,该算法执行两次;
- 所有卷积遵循ReLU->卷积->BN的计算顺序;
- 为了保持Feature Map的数量的一致性,必要的时候添加 1×1 卷积。
堆叠Cell得到的CIFAR_10和ImageNet的实验结果如图3所示。
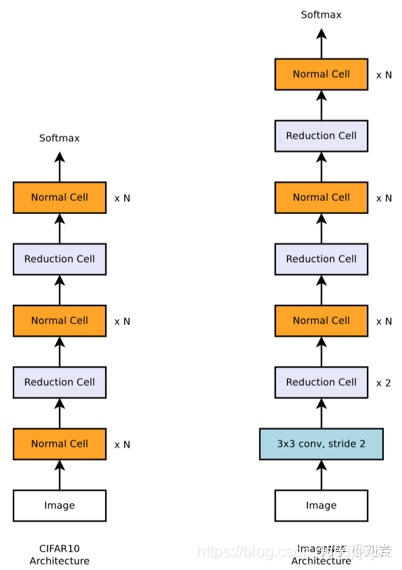
NASNet最大的贡献是解决了NAS无法应用到大数据集上的问题,它使用的策略是先在小数据集上学一个网络单元,然后在大数据集上堆叠更多的单元的形式来完成模型迁移的。
NASNet已经不再是一个dataset interest的网络了,因为其中大量的参数都是人为设定的,网络的搜索空间更倾向于密集连接的方式。这种人为设定参数的一个正面影响就是减小了强化学习的搜索空间,从而提高运算速度,在相同的硬件环境下,NASNet的速度要比NAS快7倍。
NASNet的网络单元本质上是一个更复杂的Inception,可以通过堆叠 网络单元的形式将其迁移到任意分类任务,乃至任意类型的任务中。论文中使用NASNet进行的物体检测也要优于其它网络。
本文使用CIFAR-10得到的网络单元其实并不是非常具有代表性,理想的数据集应该是ImageNet。但是现在由于硬件的计算能力受限,无法在ImageNet上完成网络单元的学习,随着硬件性能提升,基于ImageNet的NASNet一定会出现。
MNasNet
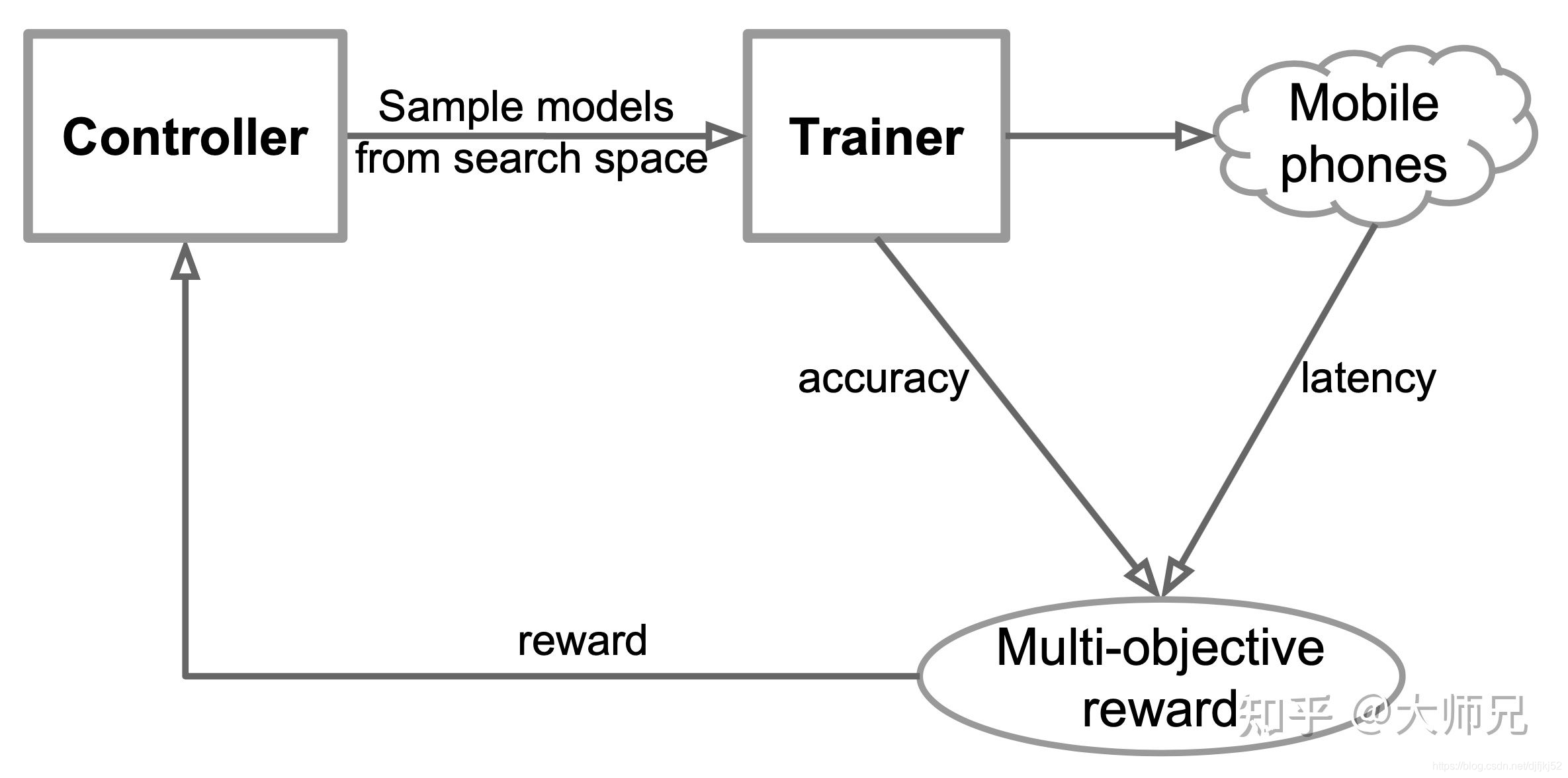
在之前介绍的神经网络搜索算法中[2,3,4],我们都是使用了准确率作为模型搜索的唯一指标,通过这种方式搜索出来的网络架构往往拥有复杂,并行性很差而且速度很慢的的网络结构。这种网络结构因为速度的限制往往很难应用到移动端环境,在一些搜索轻量级网络的算法中,它们都是使用FLOPS作为评价指标,但是MNasNet(Mobile NasNet)[1] 中指出这个指标并不能真实的反应在移动端的推理速度,因此MNasNet中提出了同时将识别准确率和在实际移动端的推理延迟共同作为优化目标,辅助于从MobileNet v2[2]中抽离的操作作为搜索空间极大缩小了搜索空间,达到了当时在ImageNet上Top-1的识别准确率以及比MobileNet v2更快的推理速度。
1. MNasNet详解
在设计一个模型搜索算法时,有三个最重要的点:
优化目标:决定了搜索出来的网络框架的性能和效率;搜索空间:决定了网络是由哪些基本模块组成的;优化策略:决定了强化学习的收敛速度。
本文将从这三个角度出发,来对MNasNet进行讲解。
1.1 优化目标
在上文中我们介绍了,MNasNet是一个同时侧重于推测速度和推测准确率的模型,因此MNasNet同时将准确率 和推测延迟 作为优化目标。在实际应用场景中优化目标可以定义为:在满足延迟小于预期推理时间的前提下,最大化搜索模型的识别准确率
1.2 搜索空间
在之前的文章中,都是通过采用搜索一个网络块,然后将网络块堆叠成一个网络的形式来搭建网络的。作者认为这种方式并不是一种合适的方式,因为在深度学习中不同的网络层有着不同的功能,如果笼统的给每一个网络块都套用相同的结构的话,很难保证这个网络块可以作用到全网络。之前之所以采用网络快的方式进行搜索,是因为搜索空间过于庞大,基于全图的搜索空间更是比基于块的指数倍,但是如果搜索空间足够小的话,那么就能够使用基于全图进行结构搜索。
在MNasNet中,作者提出了分解层次搜索空间(Factorized Hierarchical Search Space)来进行搜索空间的构造,如图4所示。分阶层次空间是由机器搜索结合人工搭建共同构建神经网络的,具体的讲,它通过将一个网络分成若干个网络块,每一个网络块又由若干个相同的层组成,然后为每一个层单独的进行结构搜索。如果块与块之间需要进行降采样的话,则第一层的步长为2,其它层的步长为1。另外在每一层中都有一个单位连接。
这么做的好处有两点:
不同层次的网络块对速度的影响不同,例如接近输入层的网络的输入Feature Map的分辨率越大,因此对运行速度的影响也越大;不同的网络层有了不同的结构后,对准确率的提升也有帮助。
1.3 搜索算法
MNASNet使用的是和NASNet相同的搜索算法,即将要搜索的网络结构表示成一个由tokens组成的list,而这个list可以通过一个序列模型来生成,假设这个序列模型的参数,那么强化学习的目标可以表示为最大化式生成模型的奖励
当我们设计一个要考虑速度的网络时,将速度相关指标加入到强化学习的奖励中是非常自然的想法,MNasNet抛弃了最常用的FLOPS而使用了最直接的在手机上的推理延迟。但是在MNasNet中只使用了一种品牌的手机,是否网络的设计过于拟合了这个型号手机的性能?是否会因为手机硬件的不同而在其它类型的手机上表现不好?
MNasNet的搜索空间很大程度上参考了MobileNet v2,通过强化学习的方式得到了超越其它模型搜索算法和其参照的MobileNet v2算法,从中可以看出人工设计和强化学习互相配合应该是一个更好的发展方向。MNasNet中提出的层次化搜索空间可以生成每个网络块都不通的网络结构,这对提升网络的表现也是有很大帮助的,但这点也得益于参考MobileNet v2设计搜索空间后大幅降低的搜索难度。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









