







Bahdanau et al. 在2014年发表了论文Neural Machine Translation by Jointly Learning to Align and Translate 首次提出了Attention注意力机制,爆火RNN网络。后来出现了一些变种,如Luong et al. 在2015年发表的 Effective Approaches to Attention-based Neural Machine Translation
Bahdanau Attention是一个Seq2Seq模型,它加强了传统Seq2Seq模型中Decoder对于Encoder信息的提取。对于传统的Seq2Seq模型的架构可以见链接
文章目录
The Bahdanau Attention Mechanism - Machine Learning Mastery
paper:https://machinelearningmastery.com/the-bahdanau-attention-mechanism/
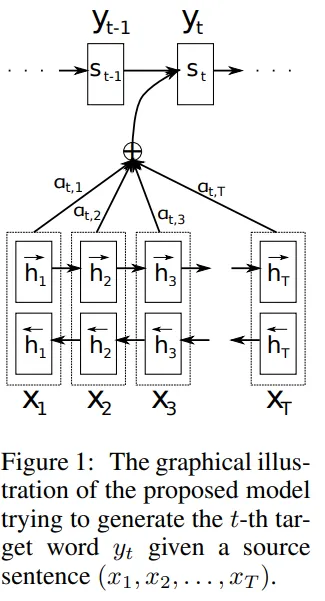
Bahdanau在Encoder中用了双向RNN,不过这不是关键,关键是Decoder的每一个时刻,都考虑全部的Encoded sequence,在此基础上计算一个context vector
记 si 为Decoder在时刻 i 的hidden state.
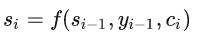
可见,si 的计算,用到了上一个时刻的hidden state si-1、上一个时刻的输出 yi-1 ,以及 i 时刻专属的contexte vector ci.
这个 ci 如何计算呢?–> 它是Encoded sequence h1 h2 … ht的线性组合。
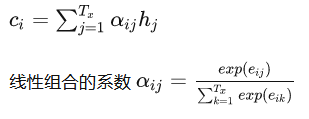
其中eij,我们可以把它称为Attention score,因为它衡量了 j 位置的输入与 i 位置的输出之间的匹配程度。
 Bahdanau用一个简单的前馈神经网络模拟函数a ,即
Bahdanau用一个简单的前馈神经网络模拟函数a ,即
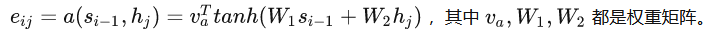
由于它把 si-1 和 hj “加”起来了,所以这个Attention mechanism也被称为additive attention.
The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixedlength vector. – Neural Machine Translation by Jointly Learning to Align and Translate
上面这段话总结了Attention机制的精髓:由Decoder决定Encoded sequence的哪部分是重要的,给予更高的权重 aij ;这样解放了Encoder,使得它不再需要把整个输入序列编码为一个固定长度的context vector.
还有一个细节要注意,原文中Encoder用了双向RNN,在每一个位置,有正向和反向的 hij . 将二者合并一下,得到Encoded sequence:
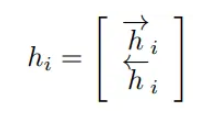
Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
Attention计算流程
总结一下:
1、Encoder计算出Encoded sequence h1,h2,…ht
2、利用一个前馈神经网络模拟函数 a ,计算Attention score—— eij=a(si-1,hj)
3、在 j 所在的维度上对 eij 作用一个softmax函数,得到 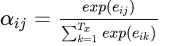
4、对于Decoder的位置 i ,计算context vector ci,它是Encoded sequence h1,h2,ht的线性组合,对应系数为aij : 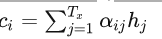
5、通过 si-1,yi-1,ci,计算 si 以及yi ,计算细节见下图:

The Luong Attention Mechanism - Machine Learning Mastery
paper:https://machinelearningmastery.com/the-luong-attention-mechanism/
In this work, we design, with simplicity and effectiveness in mind, two novel types of attention-based models: a global approach which always attends to all source words and a local one that only looks at a subset of source words at a time. – Effective Approaches to Attention-based Neural Machine Translation
Luong在他的论文中提出了两个注意力机制,一个Global,一个Local。前者考虑全部Encoded sequence,对经典注意力机制作了一些修改;后者则只考虑部分Encoded sequence,用来计算Attention score eij
Global attention model
流程:

与Bahdanau方法的差异之处:
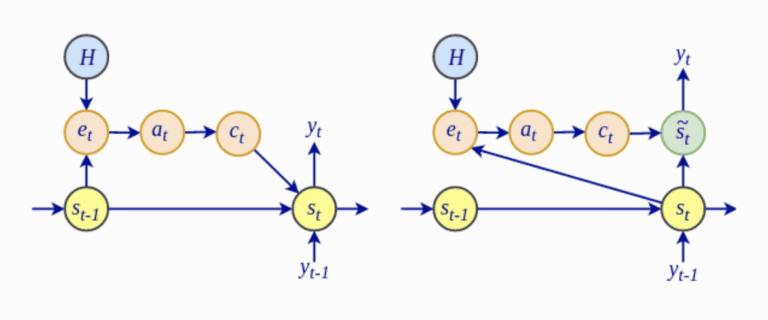 The Bahdanau architecture (left) vs. the Luong architecture (right)
The Bahdanau architecture (left) vs. the Luong architecture (right)

我认为,Luong的主要思想是:用当前时刻Decoder的隐藏状态,去计算当前时刻的一系列Attention score,其余的都是为这个思想铺路。作为对比,Bahdanau直接用了前一个时刻Decoder的隐藏状态,去计算当前时刻的一系列Attention score.
另外,在Encoder和Decoder隐藏状态的计算上,Luong使用了LSTM深度网络,取最后(最上面)一层的输出作为隐藏状态;而Bahdanau用的是双向RNN单元。
最后,Luong拓展了计算Attention score的方法,不仅有additive attention,还有multiplicative attention,后者在self-attention里也有体现。
Local attention model
The global attention has a drawback that it has to attend to all words on the source side for each target word, which is expensive and can potentially render it impractical to translate longer sequences, e.g., paragraphs or documents. To address this deficiency, we propose a local attentional mechanism that chooses to focus only on a small subset of the source positions per target word. – Effective Approaches to Attention-based Neural Machine Translation
它的思路是,对于Decoder的某一个位置 i,如果去计算它相对于Encoded sequence每一个位置的Attention score,计算量是很大的。那么我能不能只计算它相对于Encoded sequence某一个窗口内各个位置的Attention score呢?
当然可以。问题是,如何选择Encoded sequence的窗口?

写在最后
通过最初的Bahdanau Attention模型,初步了解了注意力机制的基本架构;通过Luong的改进,我们进一步掌握了注意力机制,认识了它的变种,这对于将来我们自己改进注意力机制是有好处的。
参考
https://zhuanlan.zhihu.com/p/577664617

















 4987
4987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









