







文章目录
什么是MLU (类似于GPU)

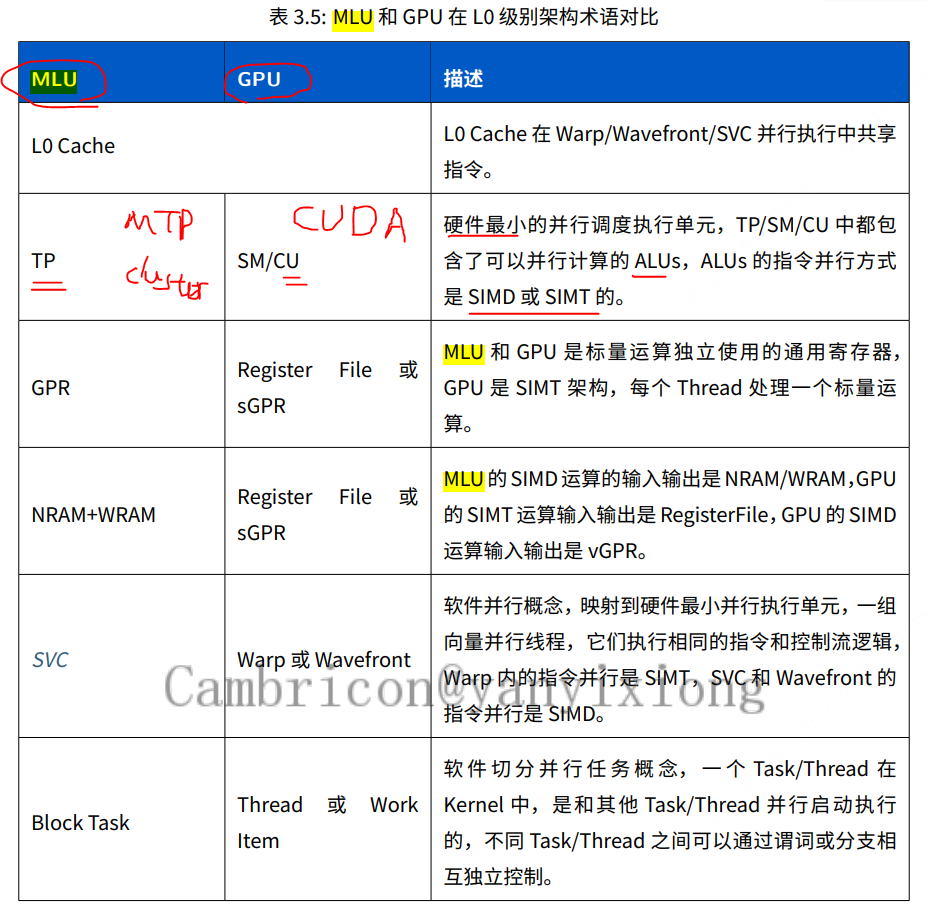
基本知识回顾
回顾在【寒武纪(7)】MLU的cntoolkit:Cambricon-BANG架构和使用分析,MLU并行计算的硬件抽象、编程模型以及调优思路
两点需要知道:
1:计算规模
2:任务类型
硬件
寒武纪行歌 SD5223C,第三代MLU
echo " --sd5223 Build for target product SD5223: __BANG_ARCH__ = 520"
echo " __MLU_NRAM_SIZE__ = 1280KB"
echo " __MLU_WRAM_SIZE__ = 688KB"
echo " __MLU_SRAM_SIZE__ = 0KB"
echo " cncc --bang-mlu-arch=tp_520, cnas --mlu-arch tp_520"

SD5223 不支持cnrtFunctionType_t k_type =CNRT_FUNC_TYPE_UNION1,仅仅支持: cnrtFunctionType_t k_type =CNRT_FUNC_TYPE_BLOCK; ;
设计一个任务
对一个 四维张量进行 abs激活处理。
分为五个维度结果
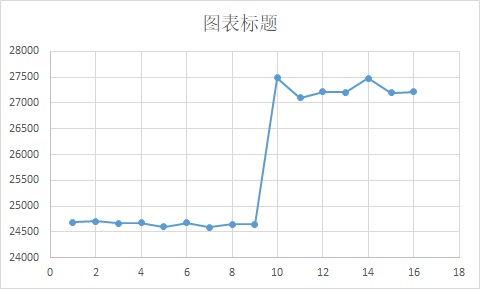
| 计算维度–> abs激活 | Nram Size | 任务规模 | 任务类型 | 时间ms | 编译优化 |
|---|---|---|---|---|---|
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 64,1,1 | CNRT_FUNC_TYPE_BLOCK | 24687 | O3 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 8,1,1 | CNRT_FUNC_TYPE_BLOCK | 24706 | O3 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 4,1,1 | CNRT_FUNC_TYPE_BLOCK | 24663 | O3 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 2,1,1 | CNRT_FUNC_TYPE_BLOCK | 24679 | O3 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 24598 | O3 |
| 1024 * 13 * 17 * 19; | (128 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 24671 | O3 |
| 19 * 13 * 17 * 1024; | (128 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 24589 | O3 |
| 1024 * 13 * 17 * 19; | (1 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 24651 | O3 |
| 1024 * 13 * 17 * 19; | (1 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 24651 | O1 |
| 1024 * 13 * 17 * 19; | (1 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 27493 | O0 |
| 1024 * 13 * 17 * 19; | (128 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 27106 | O0 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 2,2,2 | CNRT_FUNC_TYPE_BLOCK | 27215 | O0 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 2,1,1 | CNRT_FUNC_TYPE_BLOCK | 27208 | O0 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 4,1,1 | CNRT_FUNC_TYPE_BLOCK | 27481 | O0 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 8,1,1 | CNRT_FUNC_TYPE_BLOCK | 27200 | O0 |
| 1024 * 13 * 17 * 19; | (1024 * 1024) | 64,1,1 | CNRT_FUNC_TYPE_BLOCK | 27218 | O0 |
编译器会自动优化代码,达到较优水平
细节
1、代码
使用BANGC 需要基础的库包含:
1、cncv cnrt cndrv cnnl 因此,需要包含头文件和 so文件
export NEUWARE_HOME=/mnt/data/ef2301-sdk-0.10.0/board/develop_workspace/inference/mm/neuware
################################################################################
# Neuware Evironment
################################################################################
include_directories("$ENV{NEUWARE_HOME}/include")
include_directories("${CMAKE_CURRENT_SOURCE_DIR}/../../include")
set(CNLIBS cncv cnrt cndrv cnnl )
2、交叉编译的库
set(EXECUTABLE_OUTPUT_PATH "${CMAKE_CURRENT_SOURCE_DIR}/bin")
set(TOOLCHAIN_ROOT ${TOOLCHAIN_ROOT})
set(TARGET_CPU_ARCH ${TARGET_CPU_ARCH})
if(${TARGET_CPU_ARCH} MATCHES "aarch64-linux-gnu")
message("${TARGET_CPU_ARCH}")
include_directories(${TOOLCHAIN_ROOT}/aarch64-buildroot-linux-gnu/include/c++/9.3.0/)
include_directories(${TOOLCHAIN_ROOT}/aarch64-buildroot-linux-gnu/include/c++/9.3.0/aarch64-buildroot-linux-gnu/)
include_directories(${TOOLCHAIN_ROOT}/aarch64-buildroot-linux-gnu/)
endif()
3、BANG 的库,这里直接cmake到BANG,并设置架构为 tp_520,设置其他的 BANG_CNCC_FLAGS 和 CMAKE_CXX_COMPILER
################################################################################
# Sample Kernels
# include FindBANG.cmake and check cncc
#include(/usr/local/neuware/cmake/modules/FindBANG.cmake)
################################################################################
message("$ENV{NEUWARE_HOME}/cmake/modules")
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "$ENV{NEUWARE_HOME}/cmake" "$ENV{NEUWARE_HOME}/cmake/modules")
find_package(BANG)
set(BANG_CNCC_FLAGS "-Wall -Werror -fPIC -std=c++11 --target=${TARGET_CPU_ARCH} -O0")
set(BANG_CNCC_FLAGS "${BANG_CNCC_FLAGS}"
"--bang-mlu-arch=tp_520"
"--bang-wram-align64"
)
if(${TARGET_CPU_ARCH} MATCHES "aarch64")
# 这两行设置编译标志BANG_CNCC_FLAGS,并添加定义-D_GLIBCXX_USE_CXX11_ABI=1。这允许在编译时启用特定的C++ ABI(Application Binary Interface)。
set(BANG_CNCC_FLAGS "${BANG_CNCC_FLAGS} -D_GLIBCXX_USE_CXX11_ABI=1")
add_definitions(-D_GLIBCXX_USE_CXX11_ABI=1)
# 这行代码执行uname -m命令,并将输出存储在_uname_m变量中。-m选项用于获取机器的硬件名称。
execute_process(
COMMAND uname -m
OUTPUT_VARIABLE _uname_m
OUTPUT_STRIP_TRAILING_WHITESPACE
)
# 如果TARGET_CPU_ARCH不包含_uname_m(即硬件名称),并且_uname_m不匹配"aarch64",则执行括号内的代码。
if (NOT ("${TARGET_CPU_ARCH}" MATCHES ".*${_uname_m}.*" AND "${_uname_m}" MATCHES "aarch64"))
# 这行代码执行CMake定义的CMAKE_CXX_COMPILER变量指向的C++编译器,并传递一些参数来获取编译器版本和一些预定义的宏。
execute_process(
COMMAND "${CMAKE_CXX_COMPILER}" "-v" "-c" "-x" "c++" "/dev/null" "-M"
ERROR_VARIABLE _cxx_verbose
)
# 这行代码处理之前获取的编译器版本信息。它使用sed命令来提取编译器搜索的包含路径,并使用tr命令将新行替换为分号,然后将结果存储在_cxx_includes变量中。
execute_process(
COMMAND "echo" "${_cxx_verbose}"
COMMAND "sed" "-n" "/include.*search starts here/,/End of search list/{s/^ //p}"
COMMAND "tr" "'\n'" ";"
OUTPUT_VARIABLE _cxx_includes
)
# 从_cxx_includes列表中移除"/usr/include"路径。
list(REMOVE_ITEM _cxx_includes "/usr/include")
# 遍历_cxx_includes列表,并将每个路径添加到编译标志BANG_CNCC_FLAGS中,以便在编译时将包含路径添加到其中。这里使用了-idirafter标志,这意味着在搜索包含文件时,编译器将首先搜索当前目录,然后搜索指定的路径。
foreach(_include ${_cxx_includes})
message(STATUS "add include path: ${_include}")
set(BANG_CNCC_FLAGS "${BANG_CNCC_FLAGS} -idirafter ${_include}")
endforeach()
endif()
endif()
4、OpenCV 库
可用不用,但是实验是在 CV 实验的基础上做的,因此也有CV库
2、文件结构
|-- samples
|-- build.sh 自动化编译脚本,其内部对cmake命令进行了封装 ./build.sh --mlu-arch=SD5223C --cpu-arch=aarch64。
|-- CMakeLists.txt
|-- mlus
|-- |--CMakeLists.txt
| |-- fault_demo.mlu
| |-- fault_kernel.mlu
| |-- fault_kernel.h
|-- common
| |-- public.cc
| |-- public.h
3、实现 Kernel 功能abs激活:fault_kernel.mlu
#define MAX_NRAM_SIZE (1024 * 1024) // use 1024kB memory in nram
#define STREAM_ALIGN_NUM 64
__mlu_global__ void MLUUnfinishedExampleKernel2(void *input,
void *output,
size_t element_num) {
// taskDim 是等于 任务规模 dim.x * dim.y * dim.z =4,
// element_num 是 11 * 13 * 17 * 19 * 4
// 每个 Task 任务规模对应一个物理的Core,目前是4个Core。
//如果任务类型是Union1,Task 的dim.x 必须是4的倍数。一个cluster 对应4个core。
// SD5223C 不支持Union,只有Block。
//这行代码计算每个核心需要处理多少元素。element_num是总的元素数量,taskDim是任务的数量。
size_t per_core_num = element_num / taskDim;
//这行代码计算除以任务数量后剩余的元素数量。
size_t left_num = element_num % taskDim;
//这行代码计算当前任务(由taskId表示)的输入数据的起始位置。
char *input_start = (char *)input + taskId * per_core_num * sizeof(float);
char *output_start = (char *)output + taskId * per_core_num * sizeof(float);
//这行代码是一个条件判断,如果当前任务是最后一个任务(即taskId等于taskDim - 1),则将每个核心需要处理的元素数量增加剩余的元素数量。
if (taskId == taskDim - 1) {
per_core_num += left_num;
}
//这行代码计算每个核心可以处理的元素数量,该数量取决于MAX_NRAM_SIZE(最大的NRAM大小)的一半除以一个浮点数的大小。
size_t span_num_deal = MAX_NRAM_SIZE / 2 / sizeof(float);
//这行代码重新计算span_num_deal,使其能被STREAM_ALIGN_NUM整除。
span_num_deal = (span_num_deal / STREAM_ALIGN_NUM) * STREAM_ALIGN_NUM;
//这行代码计算每个核心加载到NRAM中的数据大小。
size_t span_load_size = span_num_deal * sizeof(float);
//这行代码定义一个指针,指向NRAM的输入缓冲区。
char *nram_input = nram_buffer;
//这行代码定义一个指针,指向NRAM的输出缓冲区。
char *nram_output = nram_buffer + span_load_size;
//这行代码计算每个核心需要重复处理多少次。
int repeat = per_core_num / span_num_deal;
//这行代码计算每个核心需要处理剩余的元素数量。
size_t remain_size = per_core_num % span_num_deal;
for (int i = 0; i < repeat; ++i) {
__memcpy(nram_input, input_start + i * span_load_size, span_load_size, GDRAM2NRAM);
__bang_active_abs((float *)nram_output, (float *)nram_input, span_num_deal);
__memcpy(output_start + i * span_load_size, nram_output, span_load_size, NRAM2GDRAM);
}
if (remain_size > 0) {
__memcpy(nram_input, input_start + repeat * span_load_size,
remain_size * sizeof(float), GDRAM2NRAM);
__bang_active_abs((float *)nram_output, (float *)nram_input, remain_size);
__memcpy(output_start + repeat * span_load_size, nram_output,
remain_size * sizeof(float), NRAM2GDRAM);
}
}
4、实现任务生成,规模设置,类型设置:fault_demo.mlu
// host function: prepare resources and call device kernel
int main(int argc, char *argv[]) {
LOGG("init device resources")
int dev;
CNRT_CHECK(cnrtGetDevice(&dev));
CNRT_CHECK(cnrtSetDevice(dev));
cnrtQueue_t queue = nullptr;
cnnlHandle_t handle = nullptr;
CNNL_CHECK(cnnlCreate(&handle));
CNRT_CHECK(cnrtQueueCreate(&queue));
CNNL_CHECK(cnnlSetQueue(handle, queue));
//定义了一个名为shape的整数数组,用于存储张量的形状。这个张量的形状是11x13x17x19
int shape[DIM_SIZE] = {1024, 13, 17, 19}; // a shape of tensor
size_t element_num = 1024 * 13 * 17 * 19;
//计算出张量的元素数量element_num和数据大小data_size。元素数量是通过四个维度相乘得到的,数据大小则是元素数量乘以单个浮点数的字节大小。
size_t data_size = element_num * sizeof(float);
//声明了三个数组:tensors,host_ptrs和device_ptrs。这些数组都是用来存储张量相关属性和内存指针的。
//其中,tensors[0]用于存储输入张量的描述符,tensors[1]用于存储输出张量的描述符。
LOGG("prepare cnnlTensorDescriptor_t and malloc memory");
// tensor[0]:input tensor, tensor[1]:output_tensor
cnnlTensorDescriptor_t tensors[TENSOR_NUM];
void* host_ptrs[TENSOR_NUM];
void* device_ptrs[TENSOR_NUM];
//在循环中,为每个张量创建一个描述符,并设置其布局、数据类型、维度和形状。然后,为每个张量在主机和设备上分别分配内存。
for (size_t i = 0; i < TENSOR_NUM; ++i) {
// create input tensor descriptor
cnnlTensorDescriptor_t desc = nullptr;
CNNL_CHECK(cnnlCreateTensorDescriptor(&desc));
CNNL_CHECK(cnnlSetTensorDescriptor(desc, CNNL_LAYOUT_ARRAY, CNNL_DTYPE_FLOAT, 4, shape));
tensors[i] = desc;
// malloc host memory
host_ptrs[i] = (void *)malloc(data_size);
// malloc device memory
void *input_ptr = nullptr;
CNRT_CHECK(cnrtMalloc(&input_ptr, data_size));
device_ptrs[i] = input_ptr;
}
// generator random input data
random((float *)host_ptrs[0], element_num);
LOGG("memcpy input data from host to device");
CNRT_CHECK(cnrtMemcpy(device_ptrs[0], host_ptrs[0], data_size, CNRT_MEM_TRANS_DIR_HOST2DEV));
LOGG("call device kernel");
// set function type and task dim
cnrtDim3_t k_dim = {64, 1, 1};
cnrtFunctionType_t k_type =CNRT_FUNC_TYPE_BLOCK;// CNRT_FUNC_TYPE_UNION1;
// call device kernel function.
KERNEL_CHECK(MLUUnfinishedExampleKernel<<<k_dim, k_type, queue>>>(device_ptrs[0],
device_ptrs[1], element_num));
// sync: wait device finish compute
CNRT_CHECK(cnrtQueueSync(queue)); // here should mlu unfinished.
LOGG("copy result from device to host");
CNRT_CHECK(cnrtMemcpy(host_ptrs[1], device_ptrs[1], data_size, CNRT_MEM_TRANS_DIR_DEV2HOST));
LOGG("free resources")
for (size_t i = 0; i < TENSOR_NUM; ++i) {
CNNL_CHECK(cnnlDestroyTensorDescriptor(tensors[i]));
free(host_ptrs[i]);
CNRT_CHECK(cnrtFree(device_ptrs[i]));
}
// free device resources
CNRT_CHECK(cnrtQueueDestroy(queue));
CNNL_CHECK(cnnlDestroy(handle));
LOGG("example run success");
return 0;
}
5、仓库地址
https://gitee.com/hiyanyx/demo-source-code-myself-cambrian-sg-sd5223c-cmake-bang-mlu-v1-c
演示
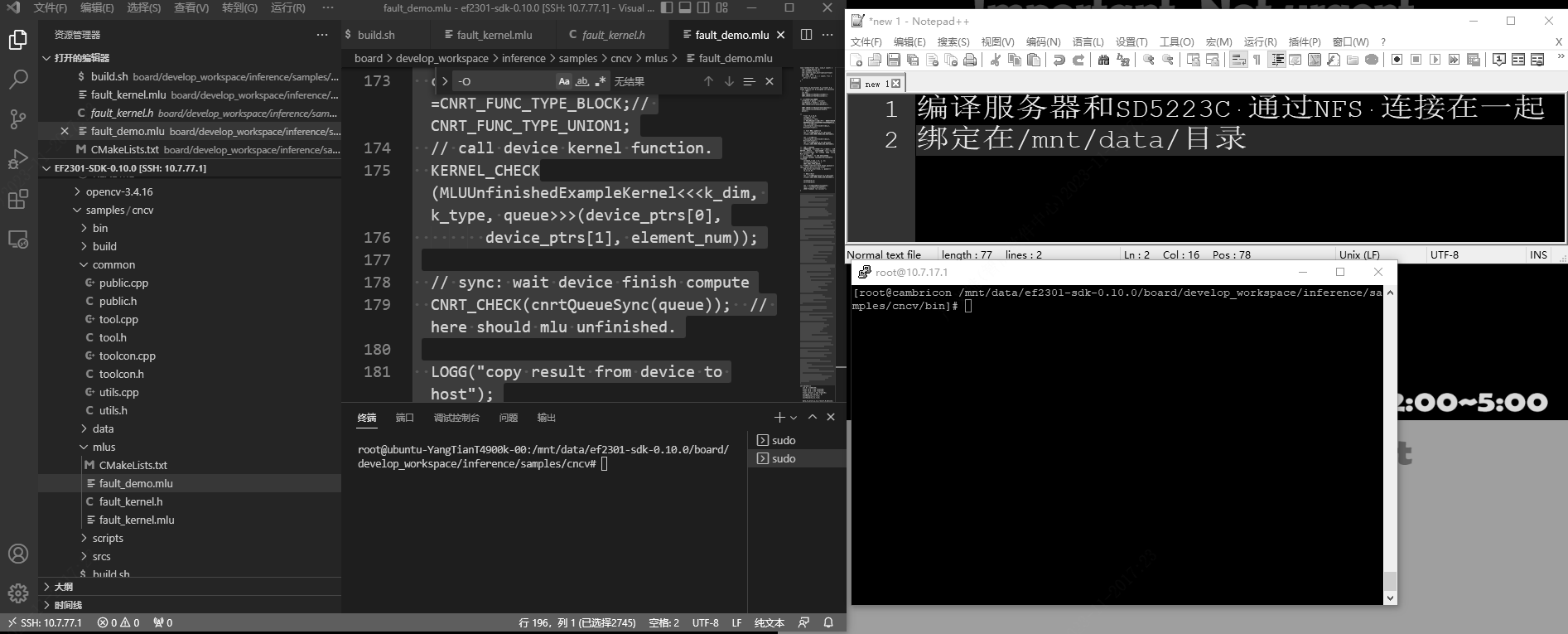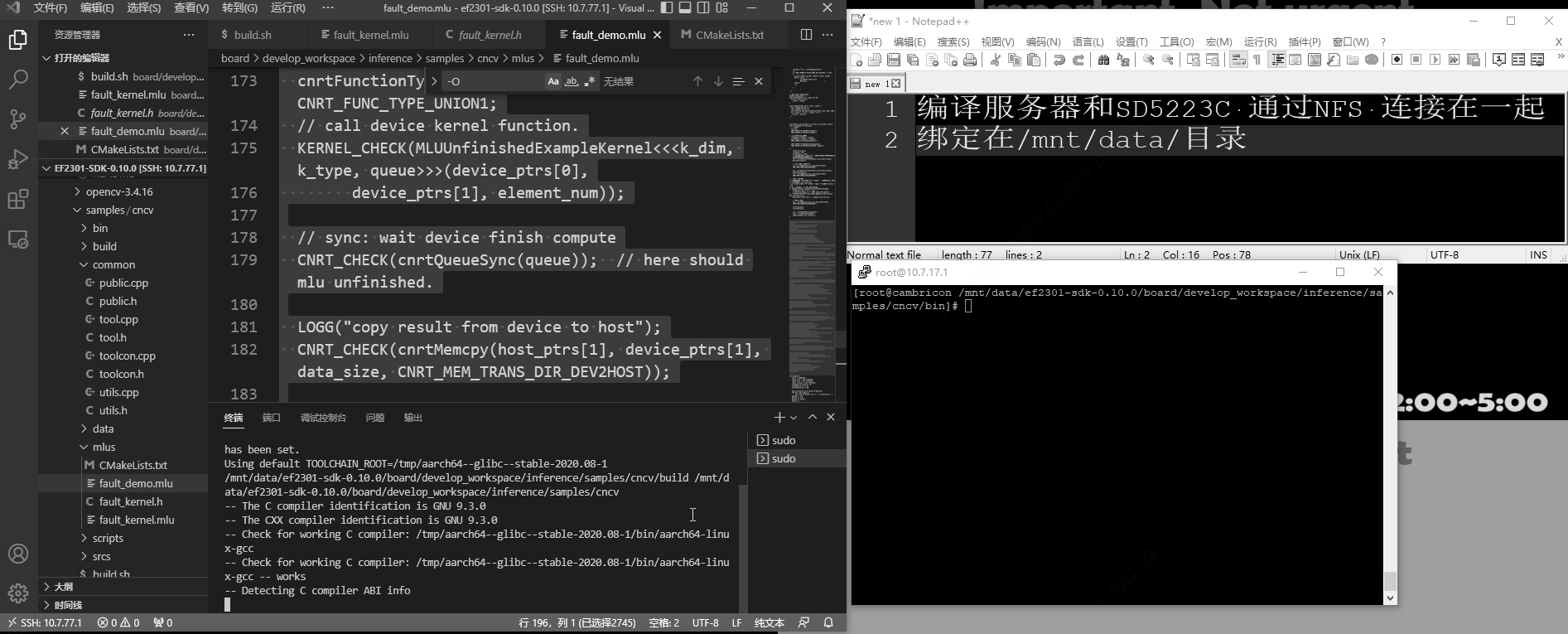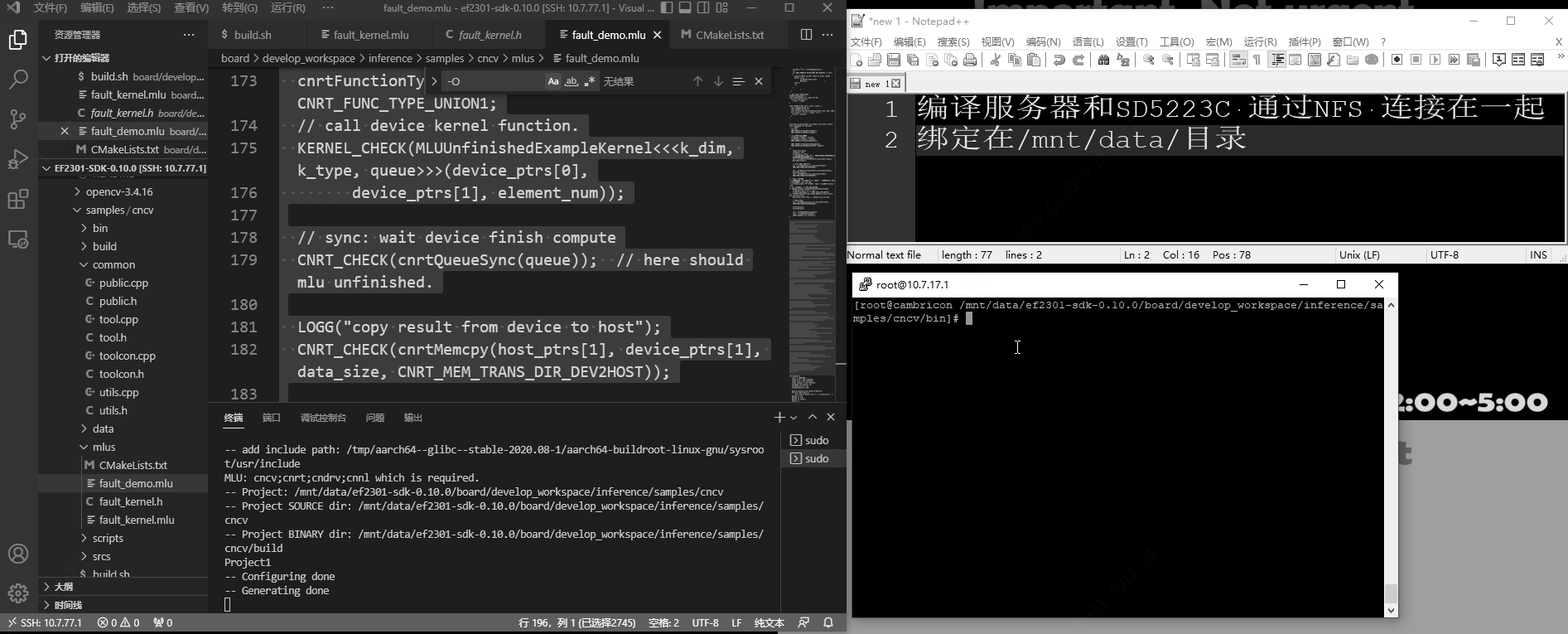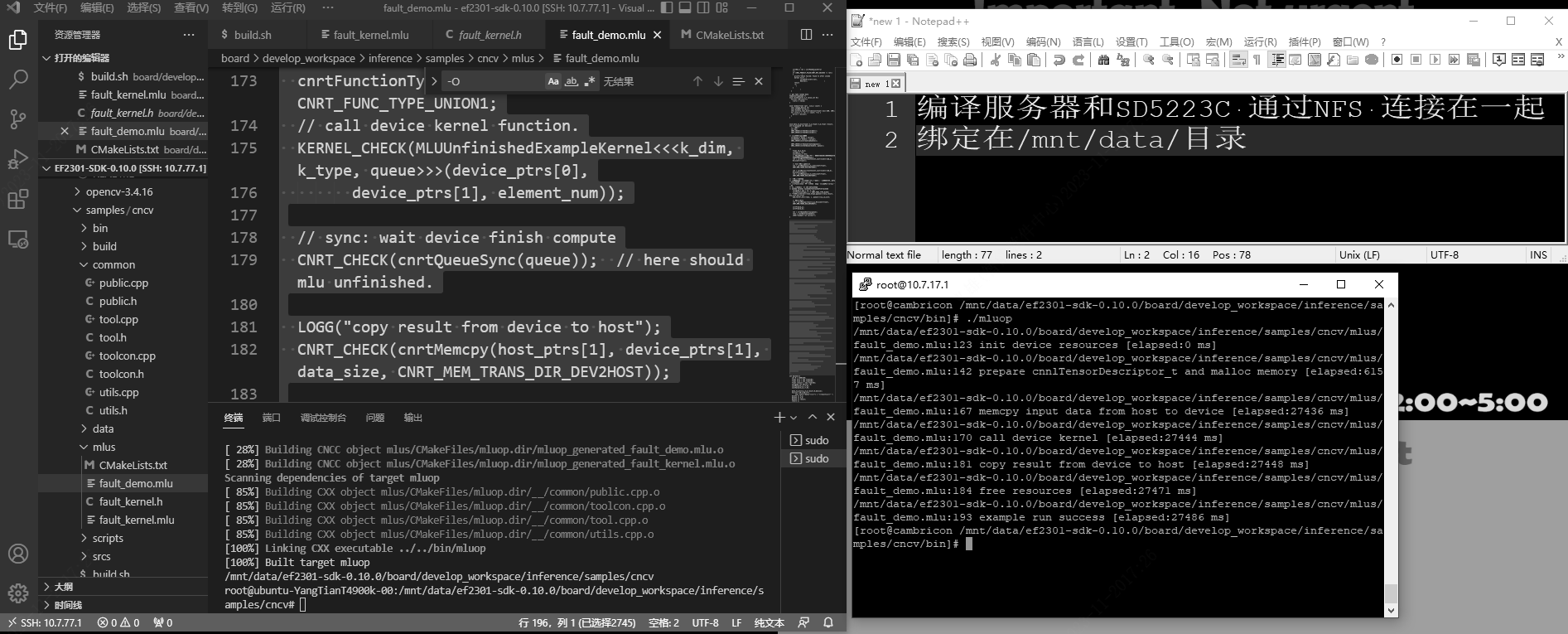
参考
https://forum.cambricon.com/index.php?m=content&c=index&a=show&catid=33&id=1134



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











