







论文:
https://arxiv.org/abs/2305.14018
概述
稀疏算法为多视图时间感知任务提供了极大的灵活性。
在本文中,我们提出了 Sparse4D 的增强版本,其中:
- 我们通过实现多帧特征采样的递归形式来改进时间融合模块。
- 通过有效解耦图像特征和结构化锚点特征,Sparse4D能够实现时间特征的高效变换,从而仅通过稀疏特征的逐帧传输来促进时间融合。循环时间融合方法提供了两个主要好处
- 首先,它将时间融合的计算复杂度从 O(T ) 降低到 O(1),从而显着提高推理速度和内存使用量。
- 其次,它能够融合长期信息,由于时间融合而带来更显着的性能提升。
介绍
虽然基于鸟瞰图 (BEV) 的算法 [3, 11, 22, 4, 12, 8] 已经引起了广泛关注并表现出较高的感知性能,但我们认为它们可能并不代表最佳解决方案,原因如下:
• 从图像特征到BEV向量空间的转换涉及重新组织和重新排列密集特征,而不引入额外的见解。 然而,这种转换确实增加了模型的复杂性。
• 在感知范围、准确性和计算复杂性之间取得平衡对于实现最佳结果至关重要。 不同的驾驶场景(例如高速公路、城市或乡村)需要特定的参数设置,以确保感知能力和计算效率之间的有效权衡。
• 在端到端自动驾驶的背景下,基于稀疏的算法产生的实例特征具有更重要的意义,因为它们可以更轻松地与graph-based models (例如 transformers)集成。
与基于BEV的算法不同,PETR系列[16,17,25]算法利用基于查询的架构和全局交叉注意力来实现多视图特征融合。 PETR 排除了密集视图转换模块,但与普通 DETR [2] 类似,它使用全局注意力,这导致理论计算成本很高。 因此,不能将其视为纯粹的稀疏算法。 基于上述原因,我们仍然致力于开发基于稀疏的算法,以提高感知性能,为端到端自动驾驶做好准备。 我们选择 Sparse4D 作为进一步增强的基线算法。
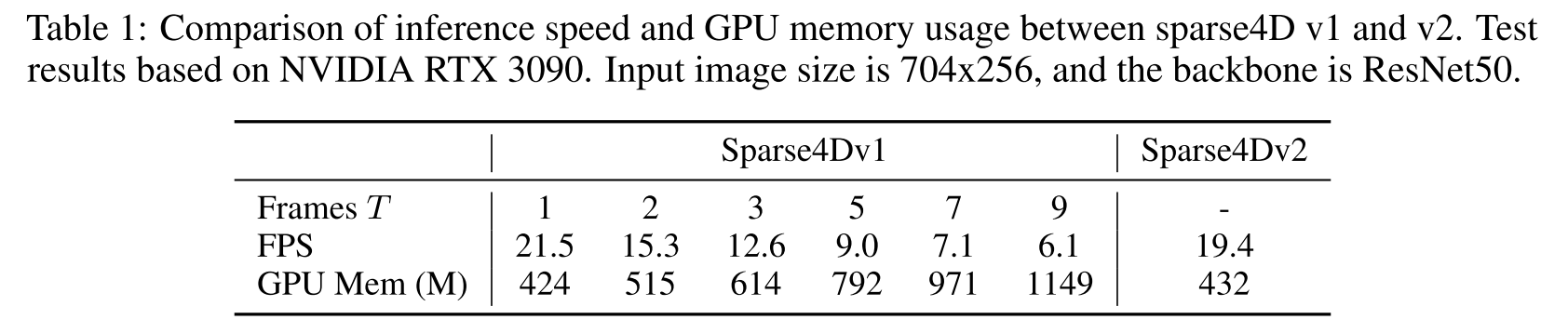
Sparse4D [15] 的时间模块表现出一个显着的局限性,它需要在执行特征融合之前对历史数据的多个帧进行采样,如图 1(a) 所示。 这导致计算复杂度随着历史帧数量的增加而线性增加,从而导致推理和训练速度降低、GPU 内存使用增加(如表 1 所示),以及有效合并长期时间特征的挑战。 为了克服这个缺点,我们提出了一种替代解决方案,通过利用实例特征的循环方式替换多帧采样方法,类似于基于查询的跟踪器和 SteamPETR [25],如图 1(b) 所示。
具体来说,对于第一帧,我们使用单帧 Sparse4D 执行检测,它输出一组 3D 边界框及其相应的实例特征。 对于后续帧,我们将前一帧的输出转换为当前帧。 实例特征保持不变,而实例状态(例如 3D 边界框)利用自我运动数据作为锚点投影到当前帧上。 锚点的位置嵌入也通过锚点编码器显式地重新编码。 为了充分利用时间实例特征,我们在解码器的每一层引入时间交叉注意模块。 通过时间投影初始化的实例主要处理轨迹,这些轨迹是先前在多个帧上检测和跟踪的对象。 对于新出现的对象,我们使用单帧单层解码器初始化它们,选择得分最高的实例子集传播到后续解码器。 这种设计使我们的时间模型能够避免增加锚点的数量,从而获得与非时间模型相当的推理速度。
除了时间模块之外,Sparse4Dv2还引入了以下改进:
- (1)通过将双线性网格采样和加权和结合到单个CUDA算子中来重构可变形聚合操作,显着减少了训练过程中的内存占用,并在一定程度上提高了训练速度 。
- (2)将相机参数编码纳入可变形聚合,以及训练期间的图像和输出坐标增强,以实现更高的感知指标和鲁棒性。
- (3)引入基于LiDAR点云的密集深度监督,以方便训练优化并提高检测精度。
我们在 nuScenes 3D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











