






文章目录
1-1.解决问题
Multimodal Sentiment Analysis (MSA)多模态情绪分析中
在未对齐的多模态数据中建模跨模态交互时效率低下
易受随机模态特征缺失的影响,这种情况通常发生在现实环境中
1-2.解决方案
Efficient Multimodal Transformer with Dual-Level Feature Restoration (EMT-DLFR)
- 其中EMT: EMT employs utterance-level representations from each modality(文中h) as the global multimodal context(文中G) to interact with local unimodal features and mutually promote each other,实现未对齐的多模式数据的有效融合,避免了 local-local cross-modal interaction methods中的二次scaling cost,且有更好效果
- 其中DLFR: 在incomplete modality setting中增加模型鲁棒性,使用DLFR
– low-level feature reconstruction:用来implicitly鼓励模型从incomplete data中学习semantic information
– high-level representations:将complete and incomplete data视为一个sample的2个view,使用siamese representation learning来explicitly提取high-level representations
2.算法
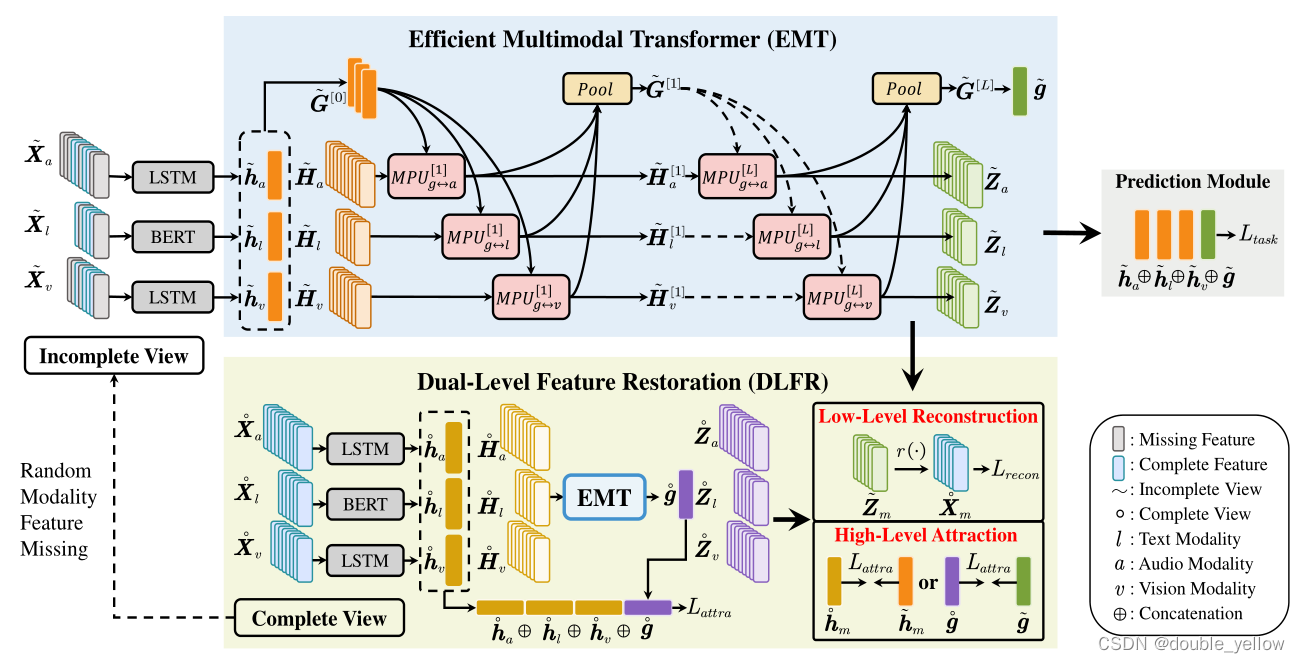
2-1.EMT
流程
-
原数据complete/incomplete feature sequence Xm(m∈{l,a,v})分别被BERT,LSTM,LSTM被encode为Hm(m∈{l,a,v})。语义级表示utterance-level representation hm,对文本l,hl为BERT中的[CLS],ha,hv为Ha,Hv中最后一个time step的feature(但是看代码不长这样,ha,hv为LSTM中的两个输出,好像没有联系,没有包含关系,hl的BERT还没仔细看,但是不是直接写的[CLS]而是BERT输出的第一维数据)。
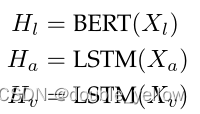
-
H和h经过LN转换维度。H由Tm*dm转为Tm*d,h由dm转为d,这一步用来统一维度
-
EMT的每一层:相互促进单元mutual promotion unit MPU。MPU作用:使用G[0]和H[0]一层一层融合得到新的G和H。MPU具体:输入多模态的H和G进行MHCA和MHSA和FFN实现生成下一层的H和G,其中G[0]和H[0]是单独设置的,其他层的G和H是通过MPU数据组合得到。G通过将每个模态的带的G通过attention-based pooling layer得到。
MPU单层介绍:
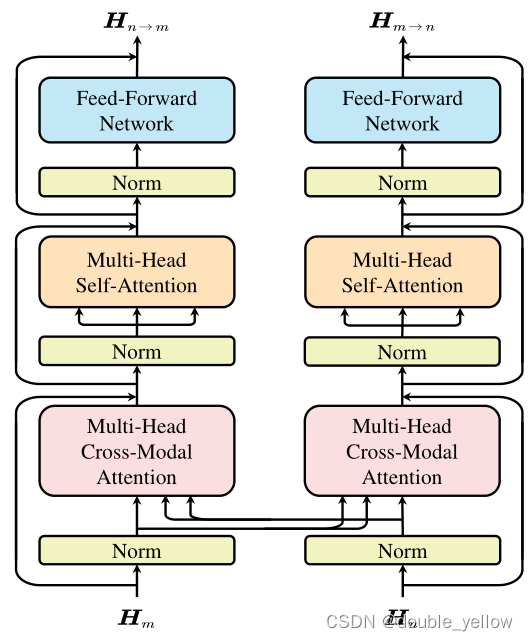



MPU实际使用得到H和G



- 得到预测的情绪强度。用最后一层MPU得到的h和g(g为flattenG[L]得出,维度为R3d),进行连接,输入MLP,得到预测的情绪强度y’。
- 计算losstask = | y - y’ |
2-2.Dual-level feature restoration
2-2-1.Low-level feature Reconstruction
- 作用:隐式地鼓励model从incomplete multimodel input中学习semantic representation(看不懂,我看公式意思是,让incomplete的Z(MPU最后一步的H)经过MLP之后得到的r(Z),与H(对l)和X(对a和v),做smoothL1 loss)
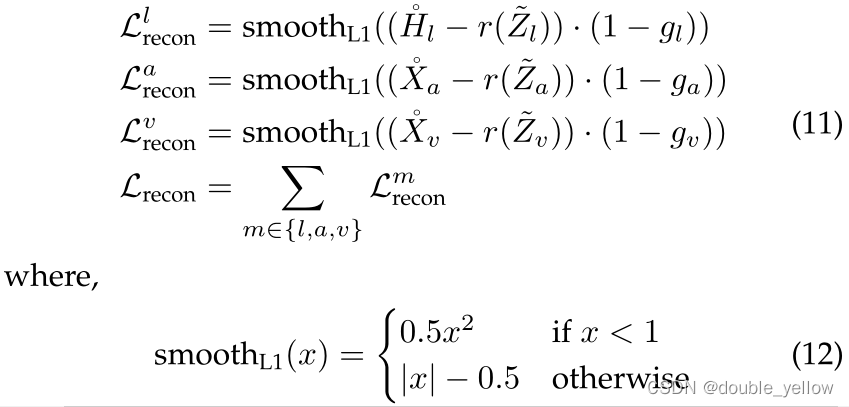
2-2-2.High-level feature attraction
这里不太懂,不懂为什么要设置p和q:作为一项手工制造pretext的task,low-level feature reconstruction不能让模型学习到语义信息,模型可能只用局部相邻信息来完成重建,而不是推测global语义。所以使用siamese representation learning来explicitly attract high-level representations of complete and incomplete views in the latent space
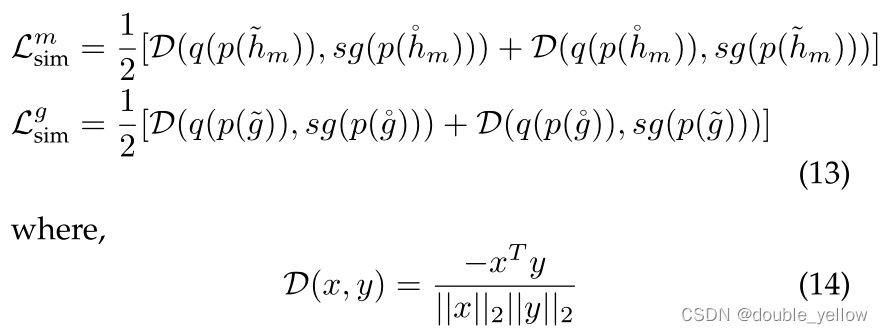
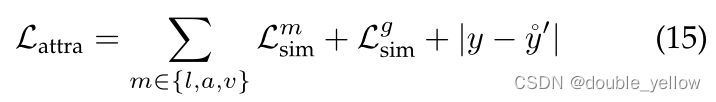
2-3.总loss
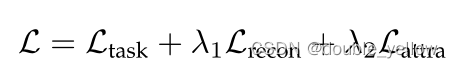
对incomplete modality setting,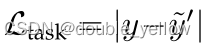
对complete modality setting,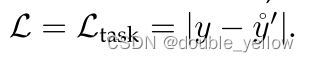















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









