






简介:
这篇文章主要介绍milvus支持的各种内存索引,以及它们最适用的场景,还有用户为了获得更好的搜索性能可以配置的参数。
索引是有效组织数据的过程,它的主要角色是在大的数据集中显著的加速耗时的查询从而有效的进行相似搜索。
当前,一个向量字段只支持一种索引类型,milvus会在选择了新的索引类型之后自动删除老的索引。
ANNS向量索引
milvus支持的大部分向量索引类型都使用近似临近搜索算法(ANNS)。相比于精确检索,它非常的耗时,ANNS的核心思想不再局限于返回最准确的结果,而是搜索目标的邻居。ANNS以牺牲可接受范围内的准确率来提高检索速度。
根据实现方式的不同,ANNS向量索引可以分成四种类型:
- 基于树的索引
- 基于图的索引
- 基于哈希的索引
- 基于量化的索引
milvus支持的索引类型
根据适用的数据类型,milvus支持的索引可以分为两类:
- embedding为浮点数的索引
- 维度等于128的浮点数embedding,存储它们需要占用 128 * 浮点数大小 = 512 字节。浮点数embedding的距离度量方法有:欧几里得距离(L2)和内积
- 这些类型的索引包括:FLAT,IVF,IVF_FLAT,IVF_PQ,IVF_SQ8,和SCANN(基于CPU的ANN搜索)
- embedding为二进制的索引
- 维度等于128的二进制embedding,存储它们需要占用128/8 = 16字节。二进制embedding的距离度量方法有:Jaccard 和 Hamming
- 这些类型的索引包括:BIN_FLAT 和 BIN_IVF_FLAT
- embedding为稀疏的索引
- 稀疏embedding支持的距离度量方法只有IP(内积 Inner product)
- 这些类型的索引包括:SPARSE_INVERTED_INDEX和SPARSE_WAND
下面的表格列举了milvus支持的索引分类:
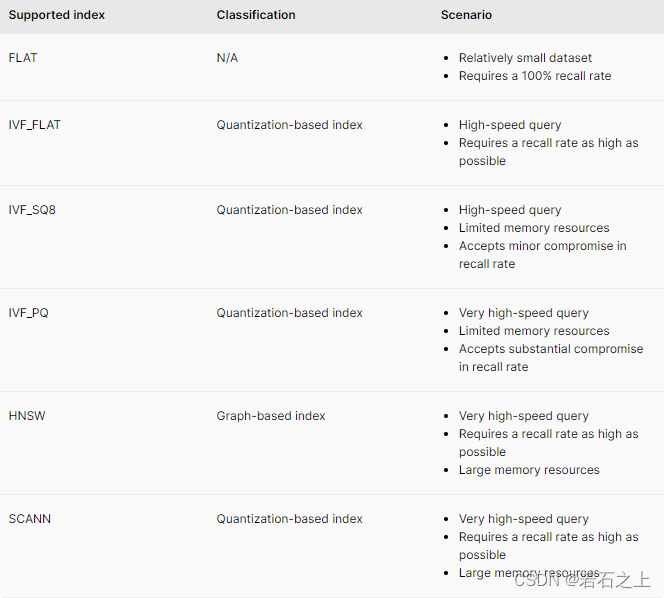
floating-point embeddings
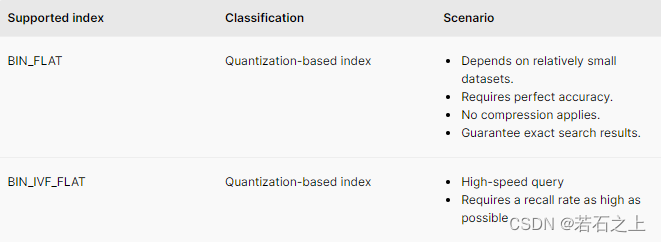
binary embeddings
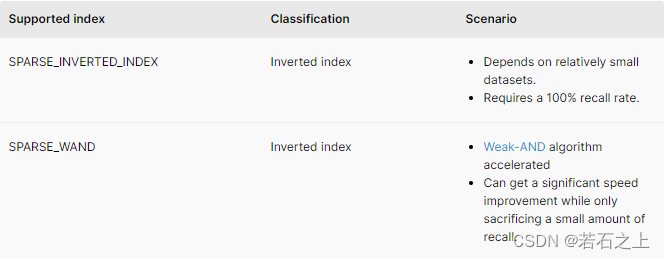
sparse embeddings
FLAT
针对要求最佳的准确率和相对比较小的数据集(百万级)的向量相似搜索应用,FLAT索引是比较好的选择。FLAT没有压缩向量,并且是唯一可以担保精确搜索结果的索引。FLAT索引返回的结果可以用来与那些召回率小于100%的索引类型进行对比。
FLAT如此精确是因为它做了全匹配,也就是它会将每个查询的输入值与数据集里面的每条数据做比较。这也就导致了FLAT是我们支持的最慢的索引,同时也不适合查询海量的向量数据。milvus里面对于FLAT没有必填的参数,并且使用它也不需要做数据训练。
查询参数
| Parameter | Description | Range |
|---|---|---|
metric_type | [Optional] The chosen distance metric. | Euclidean distance (L2) Inner product (IP) Cosine similarity (COSINE) |
IVF_FLAT
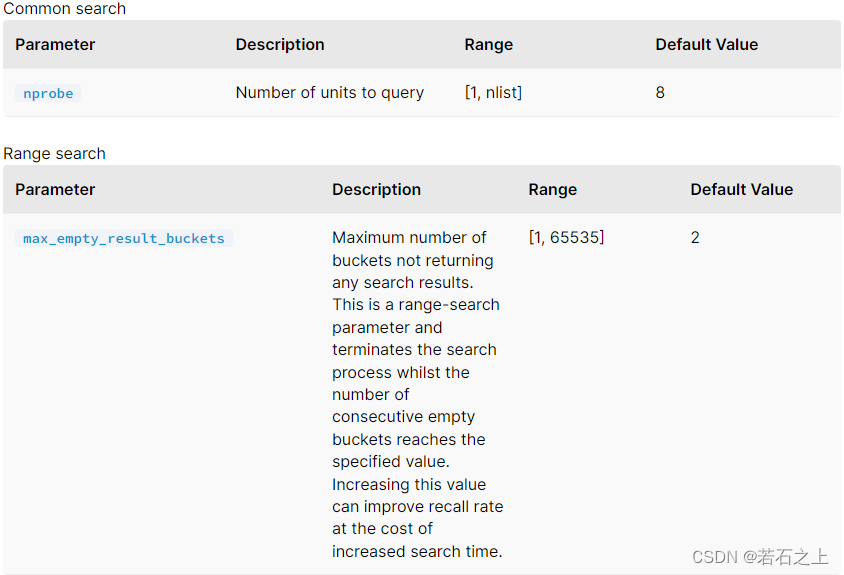
IVF_FLAT将向量数据分成 nlist 个聚类单元,然后比较目标输入向量与每个聚类中心的距离。依赖系统设置为查询(nprobe)的聚类大小,相似搜索结果的返回只基于比较目标输入与最相似的聚类的向量,从而显著的降低查询时间。
通过适配nprobe,对于特定的场景可以找到准确率与速度之间的完美平衡。根据IVF_FLAT性能测试报告,随着目标输入向量(nq)和要搜索的聚类数量(nprobe)的增加,查询时间急剧增加。
IVF_FLAT是最基本的IVF索引,存储在每个单元的编码数据与原始数据一致。
索引构建参数

查询参数
IVF_SQ8
IVF_FLAT没有进行任何的压缩,所以它产生的索引文件和原始没有索引的向量数据大小差不多。例如 1B的SIFT原始数据集的大小是476GB,它的IVF_FLAT索引文件稍微小一点点(470GB)。加载所有的索引文件到内存将会占用470GB的存储。
当磁盘、CPU或者GPU内存大小受限的时候,IVF_SQ8是比IVF_FLAT更好的选择。此索引类型通过执行标量量化(Scalar Quantization)将会把每个浮点数(4字节)转换为无符号的整数(1字节) 。这就会降低70~75%的磁盘、CPU和GPU内存占用。对于1B的SIFT数据集,IVF_SQ8索引文件只需要140GB的存储。
索引构建参数:
| Parameter | Description | Range |
|---|---|---|
nlist | Number of cluster units | [1, 65536] |
查询参数:
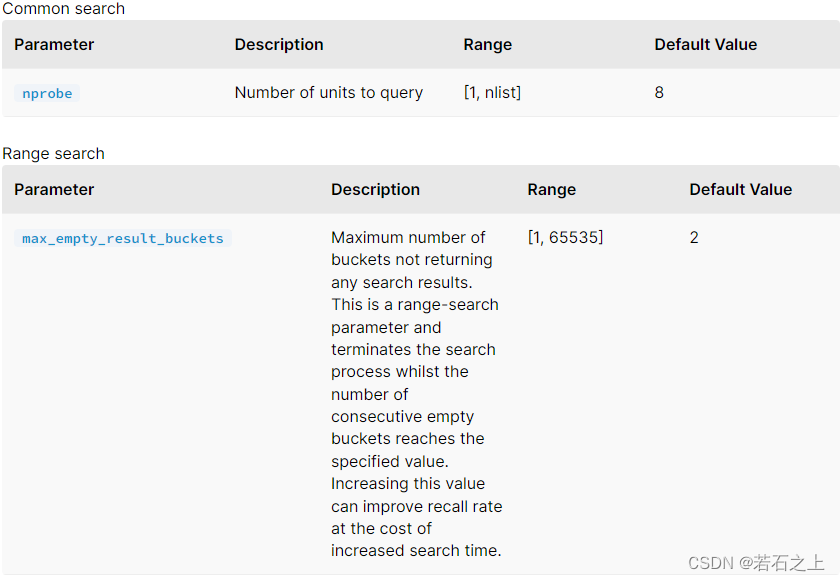
IVF_PQ
PQ(Product Quantization) 将原始高维度的向量空间分解为 m 个低维度向量空间的笛卡尔乘积,然后再量化这些分解之后的低维度向量空间。不再计算目标向量和所有单元中心的距离,PQ计算目标向量和每个低维度空间的聚类中心的距离,这样将会极大的降低算法的时间复杂度和空间复杂度。
IVF_PQ在量化向量的积之前执行IVF索引聚类,它的索引文件比IVF_SQ8还要小,但是同时也在搜索向量的时候降低了准确率。
索引构建参数:
| Parameter | Description | Range |
|---|---|---|
nlist | Number of cluster units | [1, 65536] |
m | Number of factors of product quantization | dim mod m == 0 |
nbits | [Optional] Number of bits in which each low-dimensional vector is stored. | [1, 16] (8 by default) |
查询参数:
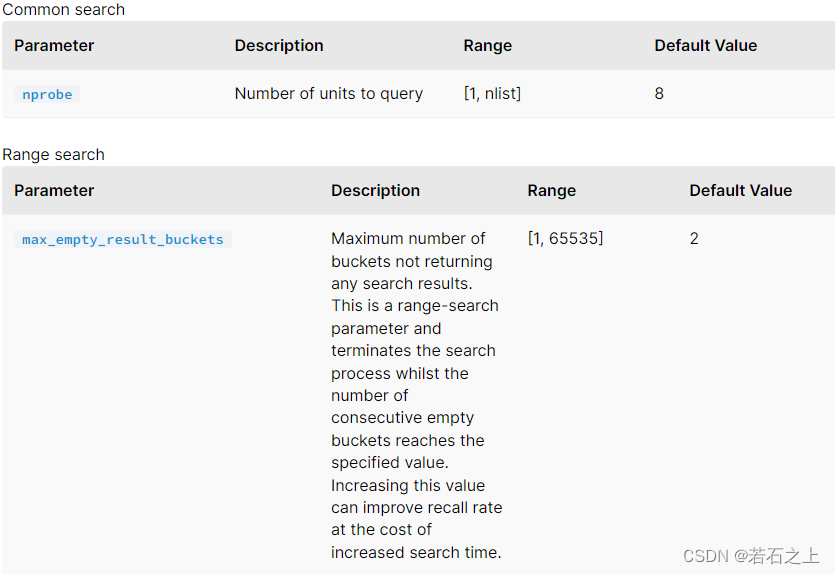
SCANN
SCANN (Score-aware quantization loss)在向量聚类和乘积量化方面和IVF_PQ很像。它们不同的地方在于乘积量化的实现细节和使用SIMD (Single-Instruction / Multi-data)进行有效计算方面。
索引构建参数:
| Parameter | Description | Range |
|---|---|---|
nlist | Number of cluster units | [1, 65536] |
with_raw_data | Whether to include the raw data in the index | True or False. Defaults to True. |
查询参数:

HNSW
HNSW (Hierarchical Navigable Small World Graph) 是一个基于图的索引算法。它根据某种规则来为图片构建多层导航结构。在这种结构中,最上层更加稀疏且节点之间的距离更远,最下层更加稠密且节点间距离更近。搜索从最上层开始,在该层找到与目标最近的节点,然后进入下一层开始再一次查找。经过多轮迭代,它可以快速找到目标位置。
为了提高性能,HNSW限制每层节点的最大连接数为M,另外我们可以使用 efConstruction(当构建索引)或者 ef(当搜索目标)来声明搜索范围。
索引构建参数:
| Parameter | Description | Range |
|---|---|---|
M | M定义图中节点最大对外连接的数量,当ef/efConstruction固定时,M越大则精度和执行时间越大 | (2, 2048) |
efConstruction | ef_construction控制索引搜索速度和构建速度。增加efConstruction会提高索引质量,同时也增加了索引构建时间 | (1, int_max) |
查询参数
| Parameter | Description | Range |
|---|---|---|
ef | 控制查询时间和准确率。大的ef会导致更精确但是更慢。 | [1, int_max] |
BIN_FLAT
它和FLAT实现原理一模一样,这里就不再介绍了,仅仅是它只能用于二进制embedding。
查询参数:
BIN_IVF_FLAT
它和IVF_FLAT实现原理一模一样,这里就不再介绍了,仅仅是它只能用于二进制embedding。
索引构建参数
查询参数
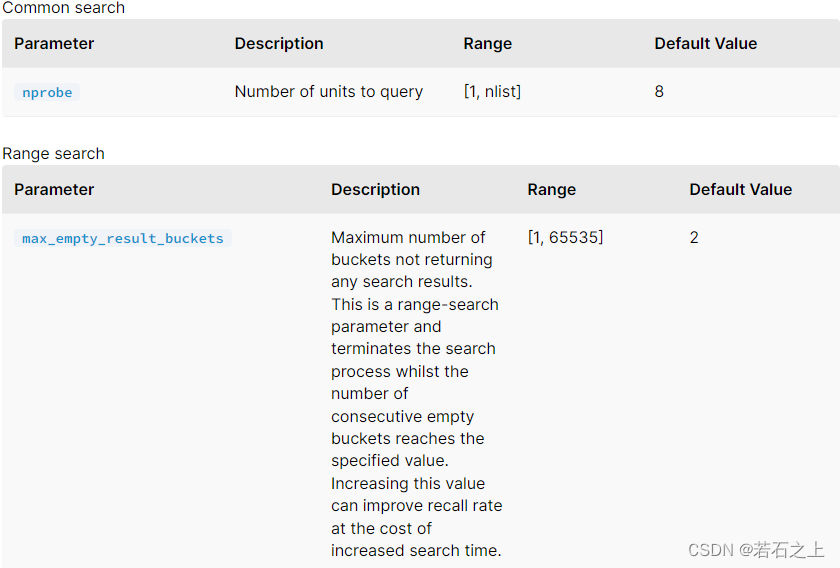
SPARSE_INVERTED_INDEX
每个维度都维护一个向量列表,这些向量在该维度上具有非零值。在搜索过程中,Milvus遍历查询向量的每个维度,并计算在这些维度中具有非零值的向量的分数。
索引构建参数:
| Parameter | Description | Range |
|---|---|---|
drop_ratio_build | 在索引过程中排除小向量值的比例,该选项允许我们调整索引处理,通过在构建索引的过程中丢弃小的值来权衡效率和准确率 | [0, 1] |
查询参数:
| Parameter | Description | Range |
|---|---|---|
drop_ratio_search | 在搜索过程中丢弃小向量值的比率,此选项允许通过指定要忽略的查询向量中最小值的比率来微调搜索过程。它能平衡搜索精度和性能。设置比较小的 | [0, 1] |
SPARSE_WAND
此索引与SPARSE_INVERTED_INDEX有相似之处。它利用 Weak-AND算法在搜索过程中来进一步降低 全IP距离评估的数量。
基于我们的测试,SPARSE_WAND在速度方面通常优于其他方法。其性能会随着向量密度的增加而迅速恶化。为了解决这个问题,引入 非零 drop_ratio_search来显著提升性能同时只产生最小的精度损失。
索引构建参数:
| Parameter | Description | Range |
|---|---|---|
drop_ratio_build | 在索引过程中排除小向量值的比例,该选项允许我们调整索引处理,通过在构建索引的过程中丢弃小的值来权衡效率和准确率 | [0, 1] |
查询参数:
| Parameter | Description | Range |
|---|---|---|
drop_ratio_search | 在搜索过程中丢弃小向量值的比率,此选项允许通过指定要忽略的查询向量中最小值的比率来微调搜索过程。它能平衡搜索精度和性能。设置比较小的 |

















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









