







3.Tensorflow实现逻辑回归
实现逻辑回归算法和线性回归差不多,也是三个步骤:
1.使用tensorflow定义逻辑回归的预测函数(sigmoid)和损失函数(交叉熵)
2.使用梯度下降优化器,找到损失函数最小时的w和b
3.将预测出的概率转化为类别
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_blobs
#创建二分类数据
data,target = make_blobs(centers=2)
#将x,y定义为tensor常量,将w,b定义为tensor变量
x = tf.constant(data,dtype=tf.float32)
y = tf.constant(target,dtype=tf.float32)
#因为这里x是二维的,所以也应该有两个w
w = tf.Variable(np.random.randn(2,1) * 0.02,dtype = tf.float32)
b = tf.Variable(0.,dtype = tf.float32)
#定义预测函数sigmoid
def sigmoid(x):
linear = tf.matmul(x,w) + b
return tf.nn.sigmoid(linear)
#定义交叉熵损失函数
def cross_entorpy_loss(y_pred,y_true):
y_pred = tf.reshape(y_pred,shape=[100])
return tf.reduce_mean(-(tf.multiply(y_true,tf.math.log(y_pred)) + tf.multiply(1-y_true,tf.math.log(1 - y_pred))))
#优化器
optimizer = tf.optimizers.SGD(0.0005)
#定义优化过程
def optimize_process():
#梯度带,用于保存梯度计算的值
with tf.GradientTape() as g:
pred = sigmoid(x)
loss = cross_entorpy_loss(pred,y)
#计算梯度
gradients = g.gradient(loss,[w,b])
#更新w和b
optimizer.apply_gradients(zip(gradients,[w,b]))
#将概率转化为分类值
def accuary(y_pred,y_true):
#设置阈值,当预测值的概率大于0.5时为正值
y_pred = tf.reshape(y_pred,shape=[100])
y_ = y_pred.numpy() > 0.5
y_true = y_true.numpy()
return (y_ == y_true).mean()
#训练
for i in range(5000):
optimize_process()
if i % 100 == 0:
pred = sigmoid(x)
loss = cross_entorpy_loss(pred,y)
acc = accuary(pred,y)
print(f'step:{i},acc:{acc},loss:{loss}')输出:
step:0,acc:1.0,loss:0.09253621846437454
step:100,acc:1.0,loss:0.0774950310587883
step:200,acc:1.0,loss:0.06659203767776489
step:300,acc:1.0,loss:0.05834386870265007
...
...
step:3900,acc:1.0,loss:0.010652526281774044
step:4000,acc:1.0,loss:0.010417823679745197
step:4100,acc:1.0,loss:0.01019334327429533
step:4200,acc:1.0,loss:0.009978425689041615
step:4300,acc:1.0,loss:0.009772470220923424
step:4400,acc:1.0,loss:0.009574925526976585
step:4500,acc:1.0,loss:0.009385292418301105
step:4600,acc:1.0,loss:0.00920309592038393
step:4700,acc:1.0,loss:0.009027909487485886
step:4800,acc:1.0,loss:0.008859342895448208
step:4900,acc:1.0,loss:0.008697017095983028与sklearn中的逻辑回归比较:
logsitic = LogisticRegression()
logsitic.fit(data,target)
#绘制图像
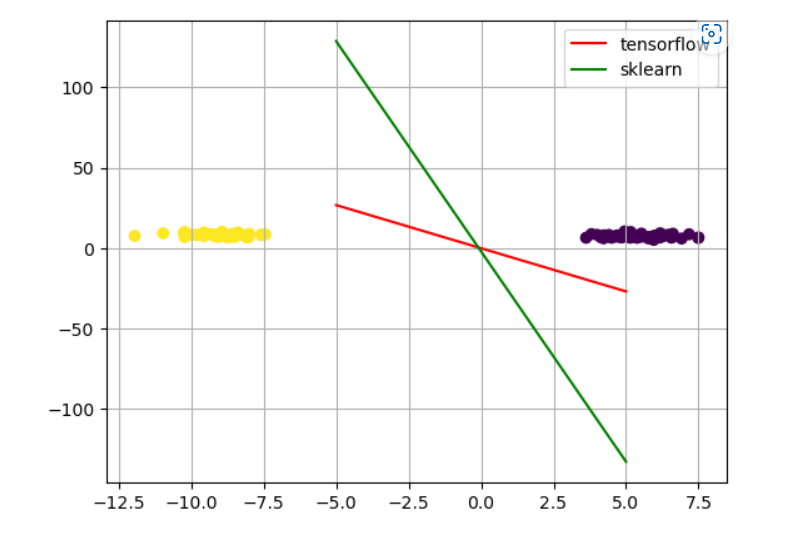
plt.scatter(data[:,0],data[:,1],c = target)
x_test = np.linspace(-5,5,200)
plt.plot(x_test,(-w.numpy()[0]/w.numpy()[1]) * x_test + b.numpy(),c = 'r',label = 'tensorflow')
plt.plot(x_test,(logsitic.coef_[0][0] /logsitic.coef_[0][1]) * x_test + logsitic.intercept_,c = 'g',label = 'sklearn')由于使用的优化器的差异,可能会导致最后的分类器不一致















 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









