







“MIT全新神经网络结构KANs,200参数顶30万!3天1.4k star!轻松复现Nature封面AI数学研究!”。这个爆火的KANs是一种新型的神经网络,受到Kolmogorov-Arnold表示定理的启发,旨在替代传统的多层感知器(MLPs)。KANs的特点是其激活函数是可学习的,并且位于网络的边(权重)上,而不是节点(神经元)上。KANs没有线性权重矩阵,而是将每个权重参数替换为一个可学习的单变量函数,该函数以样条曲线的形式参数化。相信看完这段后绝大多数读者就晕了,那我试着做一些粗浅的解读。
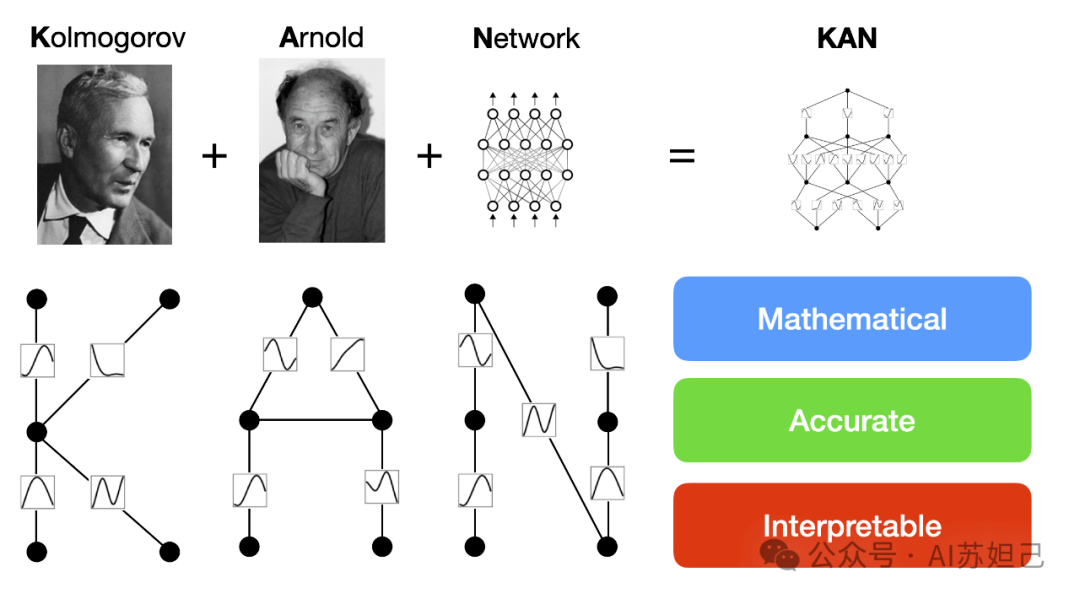
一、什么是Kolmogorov-Arnold表示定理?
在1900年,数学家大卫·希尔伯特提出了23个数学问题,这些问题被认为是数学领域的重要挑战。第13问题是关于是否存在一个通用的方法,能够用有限次的算术运算和根号运算来表示任意一个七次方程的解。这个问题后来被推广为是否可以用有限个二元连续函数来表示任意多元连续函数。Kolmogorov-Arnold表示定理是对希尔伯特第13问题的一个回答。该定理指出,任意一个定义在有界域上的多变量连续函数都可以表示为有限数量的单变量连续函数的两层嵌套叠加的形式。换句话说,无论一个函数有多少个变量,它都可以通过一系列单变量函数的组合来表达。
简单一句话,Kolmogorov-Arnold表示定理告诉我们,复杂的任务可以通过简单的步骤组合来完成。就像是一个工厂的生产线,每个工人只负责一个简单的步骤,但整个生产线能够生产出复杂的产品。
二、传统多层感知机(MLPs)又是什么?
多层感知机(Multi-layer perceptrons,MLPs)是受到人脑神经元网络连接方式的启发而设计的一种最基本的神经网络结构,它由多个层次组
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2858
2858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











