





支持向量机(SVM)在配对交易中的应用
系列文章
1 概述
2.1.1 基于距离的配对选择(1)
2.2.1 基于协整的配对选择(1)
github仓库地址:https://github.com/financialnoob/pairs_trading
原文链接:https://financialnoob.me/pairs-trading-with-support-vector-machines/
前言
在本文中,我将实现并测试一种交易策略,灵感来自于论文《算法资产管理的数据挖掘:一种集成学习方法》(Montana, Parella, 2009)。该论文中提出的策略并非真正的股票配对交易策略。相反,它使用合成资产(从几个横截面数据流生成)来确定目标资产(我们交易的资产)是被高估还是被低估。
算法的一般思想如下:
- 从n+1个数据流开始:目标资产的价格加上其他n个数据流,这些数据流用于确定资产的公允价格(其他资产的价格,市场因素,指标等)。
- 在每个时间步骤(市场收盘前每日),我们使用支持向量回归(SVR)算法根据其他市场数据估算目标资产的公允价格。
- 如果公允价格低于当前市场价格,我们卖出目标资产(做空)。
- 如果公允价格高于当前市场价格,我们买入目标资产(做多)。
- 用于估算公允价格的数据流数量可能相当大,其中许多数据流可能与彼此高度相关,为算法提供了冗余信息。为解决这个问题,使用主成分分析(PCA)提取解释最大方差且彼此不相关的多个特征。然后将提取的特征用作SVR模型的输入。
支持向量回归模型有几个需要确定的超参数:
- C — 正则化参数
- gamma — 核系数(在论文中标记为sigma)
- epsilon — 在损失函数中不给予惩罚的管道宽度
与尝试确定要使用的固定超参数集不同,论文中训练了整个模型集合(称为专家),并使用了加权多数投票(WMV)算法进行最终预测。作者总共使用了2560个模型,每个模型都有不同的超参数集。
WMV算法工作如下:
- 所有模型都从权重为一开始
- 对输入数据对每个模型进行训练,并用于预测下一个市场移动的方向(目标证券价格是否会在第二天上涨或下跌)
- 最终决定是通过比较预测价格上涨的模型的总权重与预测价格下跌的模型的总权重来确定的
- 如果最终决定是正确的,则不对权重进行调整
- 如果最终决定是错误的,则将错误的模型的权重乘以参数beta(由用户选择,应在零和一之间)
该算法允许我们通过逐渐减少犯错误的模型的权重来适应动态市场条件。
在论文中,作者描述了用于PCA和SVR算法的增量算法,这些算法允许在每个时间步骤更新模型而无需重新训练它们。我尚未完全理解并实现增量算法,因此我决定测试类似的策略,但使用常规(非增量)PCA和SVR。
我将使用的目标资产是VanEck生物技术ETF(BBH)。其他数据流(用作输入)包括该ETF持仓的价格,其他生物技术ETF的价格以及SPY ETF的价格。
要对该策略进行回测,我们需要确定几个参数,即:
- 下调错误模型权重的参数beta。(在论文中测试了几个值。)
- 要提取并用作特征的主成分数量。(在论文中只使用了一个成分。)
- 要训练的模型数量,以及网格中要使用的模型超参数的值。(在论文中使用了2560个模型,但没有提供有关超参数确切值的信息。只提供了它们的范围:epsilon变化在0.00000001到0.1之间,C和gamma变化在0.0001到1000之间。)
- 用于模型训练的最后交易日的数量。(在论文中使用了最后20天。)
我还将尝试测试几个beta值和不同数量的主成分,以确定哪个效果最好。我将使用较少数量的模型 — 512个。模型训练中使用的交易日数量将保持不变 — 20天。
让我们开始吧。
数据预处理
首先,我加载数据并将价格转换为累积收益率。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests
from time import sleep
bbh = ['MRNA', 'AMGN', 'IQV', 'ICLR', 'VRTX', 'GILD', 'REGN', 'ILMN', 'CRL', 'SGEN', 'ILMN',
'BIIB', 'TECH', 'BNTX', 'BGNE', 'EXAS', 'ALNY', 'NVAX', 'QGEN', 'GH', 'NTRA', 'BMRN',
'INCY', 'TXG', 'NTLA', 'CRSP', 'BBH']
other_etfs = ['SPY', 'IBB', 'XBI', 'ARKG', 'FBT', 'LABU', 'IDNA', 'PBE', 'GNOM', 'BIB', 'SBIO', 'BTEC']
symbols = bbh + other_etfs
# 将价格转换为累积收益率
data = (data.pct_change()+1).cumprod()
data = data.iloc[1:]
data = data / data.iloc[0]
然后,我将目标资产的价格与其他输入数据分开。
# 输入数据
s = ['MRNA', 'AMGN', 'IQV', 'ICLR', 'VRTX', 'GILD', 'REGN', 'ILMN', 'CRL',
'SGEN', 'ILMN.1', 'BIIB', 'TECH', 'BNTX', 'BGNE', 'EXAS', 'ALNY',
'NVAX', 'QGEN', 'GH', 'NTRA', 'BMRN', 'INCY', 'TXG', 'NTLA', 'CRSP',
'SPY', 'IBB', 'XBI', 'ARKG', 'FBT', 'LABU', 'IDNA', 'PBE',
'GNOM', 'BIB', 'SBIO', 'BTEC']
# 目标资产
y = ['BBH']
现在,我想知道使用多少个主成分是合理的。为了做到这一点,我将绘制一个碎石图。
from sklearn.decomposition import PCA
Xtmp = data[s] # 选择没有目标资产的数据
pca = PCA(n_components=10)
pca.fit(Xtmp)
n_comp = np.arange(1,11)
plt.plot(n_comp, pca.explained_variance_ratio_)
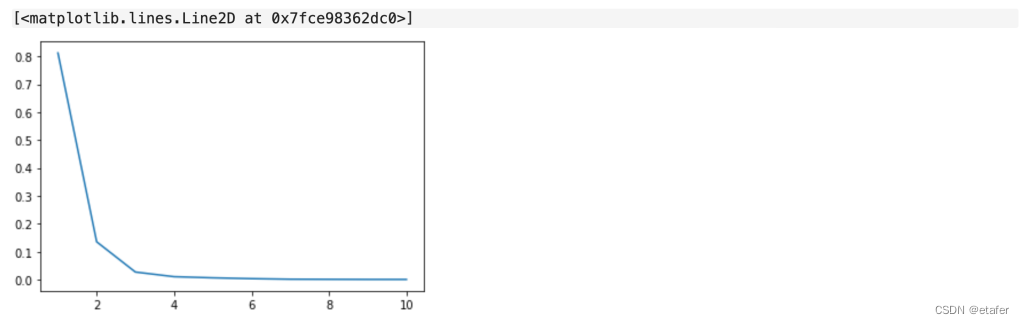
我们可以看到,在第2-3个成分之后,解释的方差比显著下降。因此,我认为我们应该提取不超过3个主成分作为我们的特征。
回测
首先,我将回测不同的beta值,将主成分数量固定。
首先,我将回测不同的beta值,将主成分数量固定。
python
复制代码
# 策略参数
betas = [0.1,0.3,0.5,0.7] # 用于降低权重的beta值
lookbacks = [20] # 训练模型时包含多少个最近交易日
pca_comps = [1] # 使用的主成分数量
以及以下SVR超参数值(共有888=512个模型):
# SVR超参数
Cs = set((0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000))
gammas = set((0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000))
epsilons = set((0.00000001, 0.0000001, 0.000001, 0.00001, 0.0001, 0.001, 0.01, 0.1))
我在计算策略表现时跳过了前50天,以允许WMV算法的权重调整。以下是我得到的结果:

我们可以看到,所有策略都是盈利的,并且参数beta的值对算法的表现没有太大影响。这与论文中的结果一致,在论文中,该算法在各种beta值下表现良好。还请注意,策略的收益与交易资产的收益不相关。
我们注意到,只使用一个主成分可以获得最佳结果,这与论文中使用的数量相同。可能其他成分只会提供噪音,这就是为什么当我们使用两个或三个成分时,性能会显著下降的原因。
现在,我将更仔细地观察使用1个主成分和beta=0.5的算法的表现。下面是该算法和目标资产(BBH)的累积收益的图表。
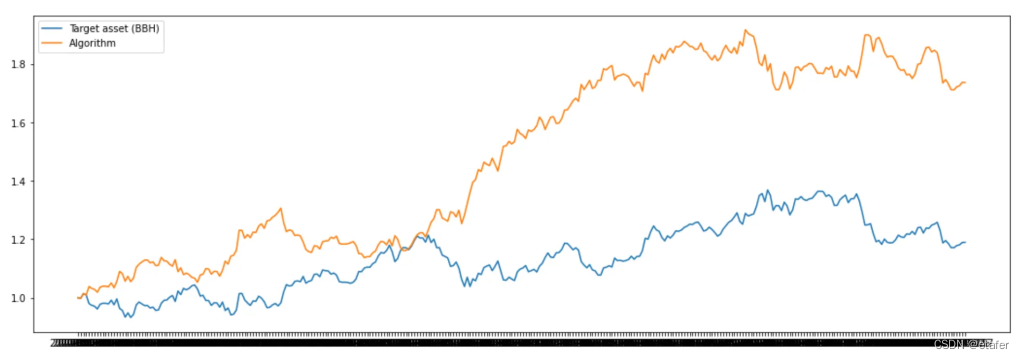
如上图所示,我们的策略明显优于简单地购买并持有目标资产。现在让我们看看我们的算法与市场(SPY)相比的表现。
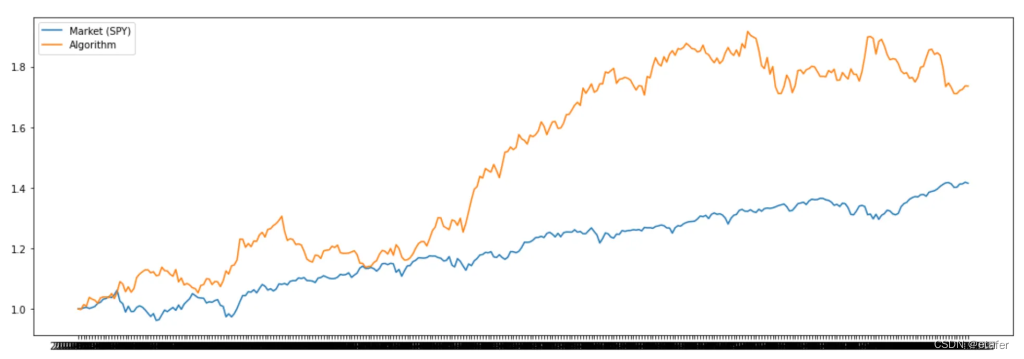
似乎我们甚至可以超越市场。当然,我们没有考虑交易成本。让我们尝试添加交易成本,看看策略是否仍然盈利。我假设双向交易成本为0.2%,这应该足以覆盖经纪费和买卖价差。当我们从做多转为做空或反之时,我将从策略收益中减去交易成本。下面是我们得到的收益的图表。
最后让我们比较一些绩效指标。
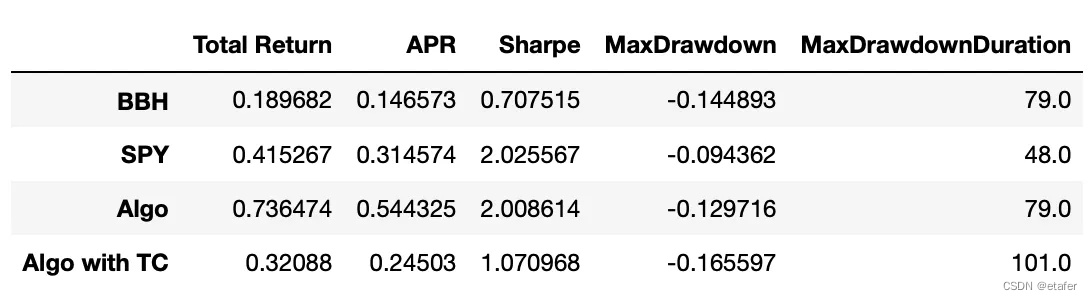
SPY的夏普比率略高于我们算法的夏普比率,其最大回撤稍小,最大回撤持续时间较短。但我们策略的回报是SPY的1.7倍。这是在计算交易成本之前。添加交易成本会显著降低策略的表现,但结果仍然优于简单的买入并持有交易资产。另外,我认为我用于计算交易成本的数值过于保守,可能可以以更低的费用进行交易,从而提高总体绩效。
现在让我们检查我们的策略的日收益是否与SPY和BBH的日收益相关。

如上所示,相关系数非常低。
进一步的改进:
- 添加更多的输入数据流(更多的生物技术ETF、不同的指数等)
- 添加入场阈值,仅当所有投票支持其的模型的权重超过某个数值时才进入做多/做空头寸(目前我们只是在所有投票支持其的模型的权重超过投票支持相反头寸的模型的权重时进入头寸,即使只是非常小的量)
- 尝试使用更多的专家(模型)
- 实现增量PCA和SVR算法
总结
尽管这种策略并不是真正的配对交易策略,但它仍具有相同的优点。它的回报与市场或目标资产的回报不相关,并且有可能可以在基本市场条件下盈利。
Jupyter笔记本的源代码可以在此处找到。
引用
[1] Data mining for algorithmic asset management: an ensemble learning approach (Montana, Parella, 2009)
[2] Learning to Trade with Incremental Support Vector Regression Experts (Montana, Parella, 2009)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









