





配对交易:基于协整的配对选择(2)
系列文章
1 概述
2.1.1 基于距离的配对选择(1)
2.2.1 基于协整的配对选择(1)
前言
在上一篇文章中,我们发现虽然协整方法为我们提供了更多潜在可交易的对,但我们选择最佳交易对的方法未如预期。大多数选择的对在交易期间偏离过多。在本文中,我希望测试几种机器学习技术,以结合多个指标并使用它们预测哪些股票在交易期间会表现“良好”。
第一步是为机器学习算法准备数据。我将有两个数据集:一个用于训练和选择模型,另一个用于纯样本外测试。两个数据集中的股票范围相同(来自VBR小盘股ETF的股票),但我将使用不同的不重叠时间段:
- 2013年1月1日–2016年6月30日用于训练数据(3年形成期 + 6个月交易期)
- 2016年7月1日–2019年12月31日用于测试数据(也是3年形成期 + 6个月交易期)
然后对于每个数据集,我执行以下操作:
- 使用形成期的股票价格选择潜在的交易对,应用与前一部分相同的标准:
- CADF p值 < 0.01
- Hurst指数 < 0.5
- 均值回复半衰期1 < 半衰期 < 30
- 每年零交叉次数 > 12
- 对于每个选定的对,我创建一个投资组合(价差),并计算以下指标(仅使用形成期的价格):
- 到均值的欧几里得距离
- CADF p值
- ADF p值
- 价差标准差
- 皮尔逊相关系数
- 零交叉次数
- Hurst指数
- 均值回复半衰期
- 在历史2倍标准差带内度过的天数百分比
- 套保比率
- 对于每对,使用交易期的价格计算零交叉次数。这是我们的因变量,我们尝试预测的目标。
我决定使用零交叉次数,因为在所有其他指标中,这是我们进行成功交易真正需要的指标,因为我们在投资组合价格穿越其历史均值时关闭头寸。没有交叉 -> 没有关闭头寸 -> 没有利润。
在执行上述所有程序后,我们得到了以下数据集:
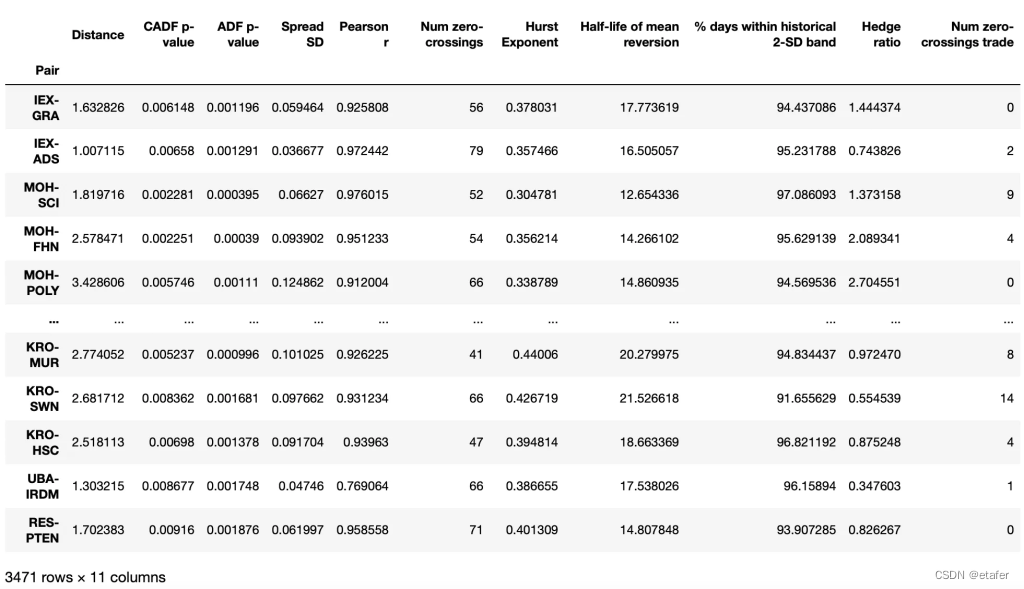
我们开始探索数据。首先,我们查看统计信息。
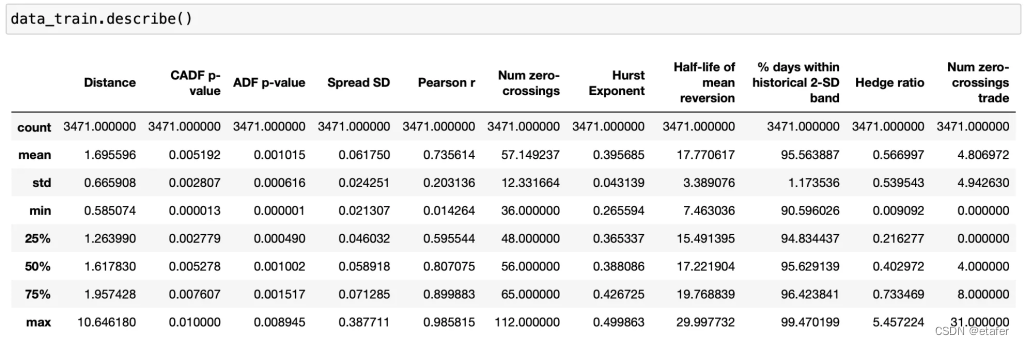
我注意到以下几点:
套保比率的最小值太低。这基本上意味着我们需要将99%的资本分配给一只股票,1%的资本分配给另一只股票,我认为这不是一个好主意。因此,我们需要删除对冲比率如此小的对。
最有趣的对(在交易期间零交叉次数最多的对)基本上是异常值。75%的对的零交叉次数少于8次。
并非所有特征都在同一尺度上,这意味着我们可能需要对数据进行一些转换。
在进一步进行之前,我将删除所有对冲比率小于0.2和大于5的对。
现在来看相关性。
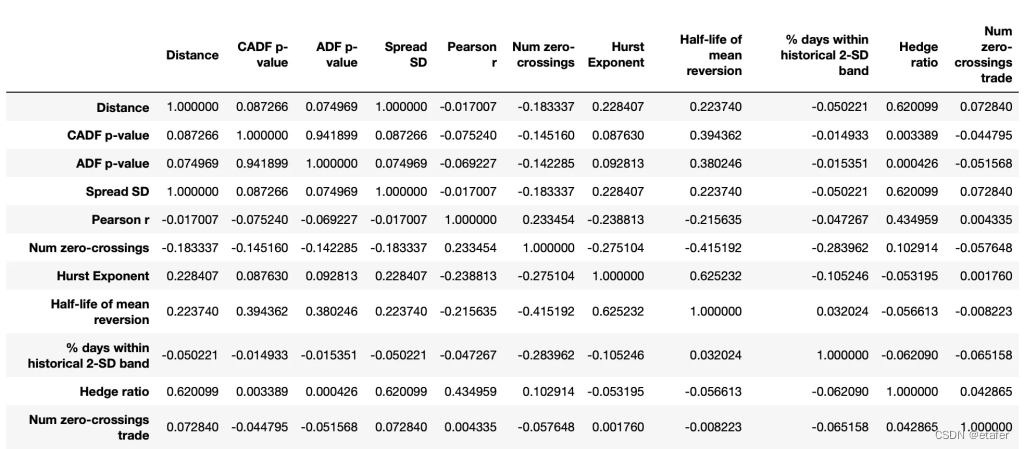
需要注意几点:
- 我们的一些自变量具有较高的相关系数,这可能会影响某些机器学习算法的性能。
- 自变量与因变量几乎没有相关性,这不是一个好兆头。
现在我们将尝试可视化我们的数据。
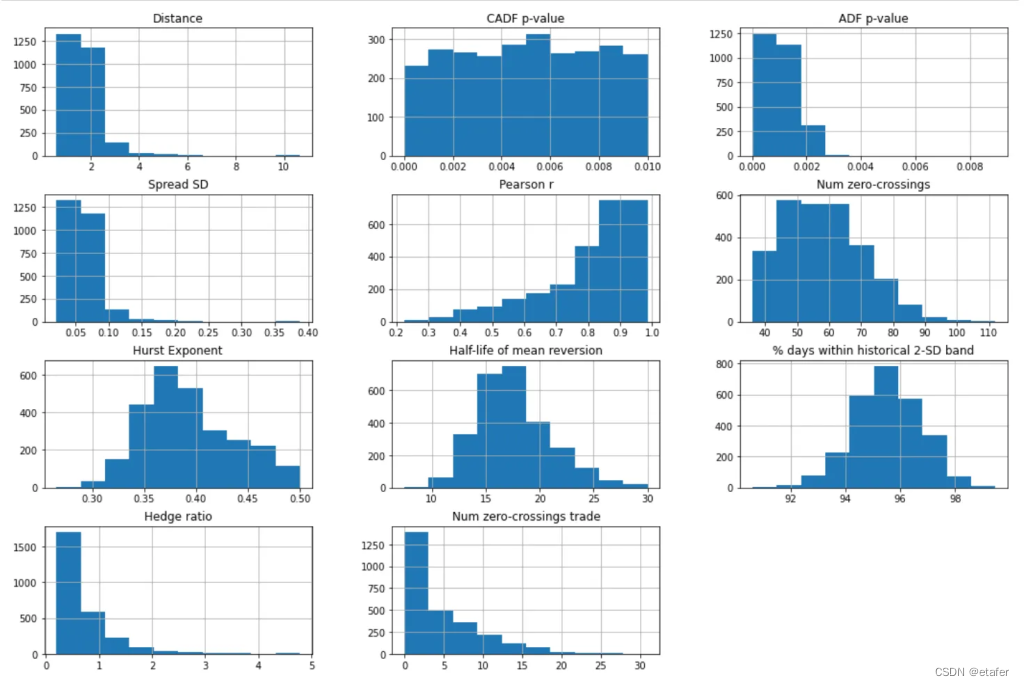
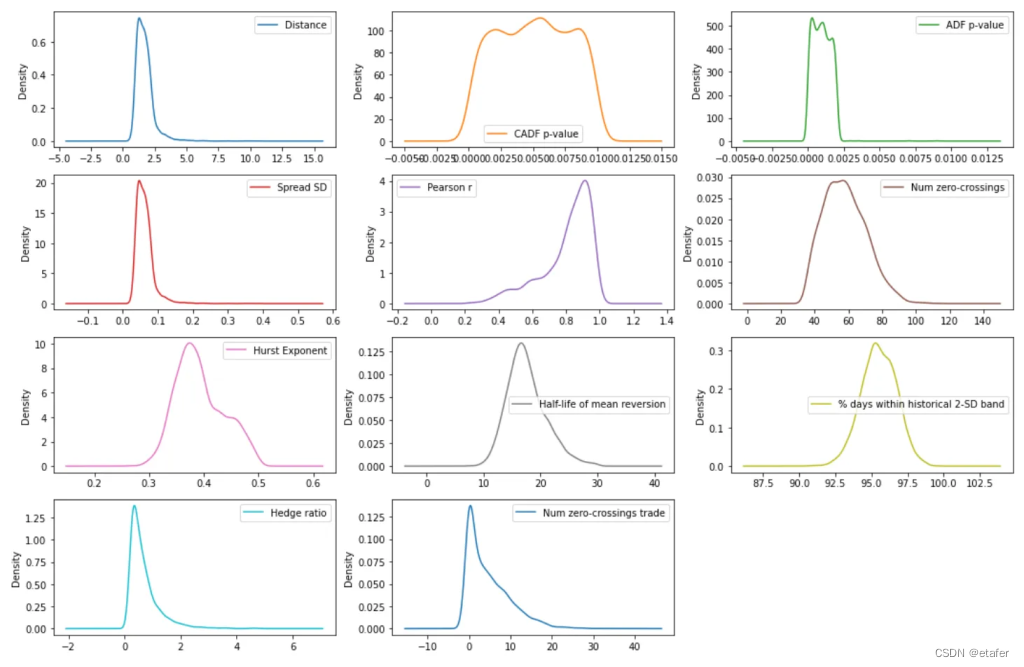
我们看到很多分布是偏斜的,所以我们可能想对特征应用幂变换。
在测试不同的机器学习算法之前,我们需要明确我们的最终目标。我们并不需要确定每对在交易期间的零交叉次数。我们需要的是找到几个具有较多零交叉次数的对。因此,我认为我们应该将问题表述为一个分类任务。
在选择潜在对时,我们要求每对每年有超过12次零交叉。由于我们的交易期是6个月,让我们尝试预测哪些对会有超过6次零交叉。
首先,我们准备训练和测试数据集:
X_train = data_train.values[:,:10]
X_test = data_test.values[:,:10]
y_train = data_train.values[:,10]
y_test = data_test.values[:,10]
现在让我们确定基线。如果我们随机选择,超过6次零交叉的对有多少?

大约30%。但要想有一个成功的交易算法,我们需要正确识别超过50%(假设我们在亏损头寸上损失的钱与在盈利头寸上获得的钱相同)。
def top10_accuracy(estimator, X, y):
'''
计算前10个预测的准确性:
选择属于类别1概率最高的前10个样本
返回实际属于类别1的样本比例
'''
pred_prob = estimator.predict_proba(X)
top10_ind = np.argsort(pred_prob[:,1])[-10:]
score = sum(y[top10_ind] == np.ones(10)) / 10
return score
它使用提供的估计器预测每对属于类别1(在交易期间有6次零交叉)的概率,选择概率最高的10对,并计算这些对实际属于类别1的比例(实际上在交易期间有超过6次零交叉)。
现在我们需要将结果变量二值化,然后就可以开始了。
from sklearn.preprocessing import Binarizer
# 二值化因变量
binarizer = Binarizer(threshold=6).fit(y_train.reshape(-1, 1))
y_train_bin = binarizer.transform(y_train.reshape(-1, 1))
binarizer = Binarizer(threshold=6).fit(y_test.reshape(-1, 1))
y_test_bin = binarizer.transform(y_test.reshape(-1, 1))
我将使用以下函数来自动化模型检查过程。
def test_models_class(models, X=X_train, y=y_train_bin.flatten(), n_folds=10, scoring=top10_accuracy, seed=45):
'''
使用n_folds和scoring对每个模型进行交叉验证
'''
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=seed)
cv_results = cross_val_score(model, X, y, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
print(f'{name}: {cv_results.mean()} ({cv_results.std()})')
return results, names
首先,我将测试几种机器学习算法,不进行任何调整。我只在适用的情况下使用class_weight属性,因为我们在类别0中的样本远多于类别1。我得到的结果如下:
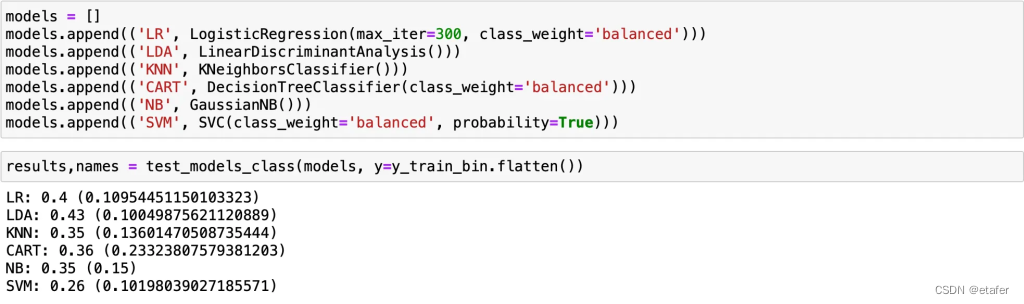
基本上和随机选择对没有什么区别,可能稍微好一点。现在,我将尝试应用Box-Cox幂变换到数据上,以消除我们在图表上看到的偏态。

结果非常相似,只有SVM的表现有所改善。让我们尝试使用SelectKBest函数移除不必要的特征。
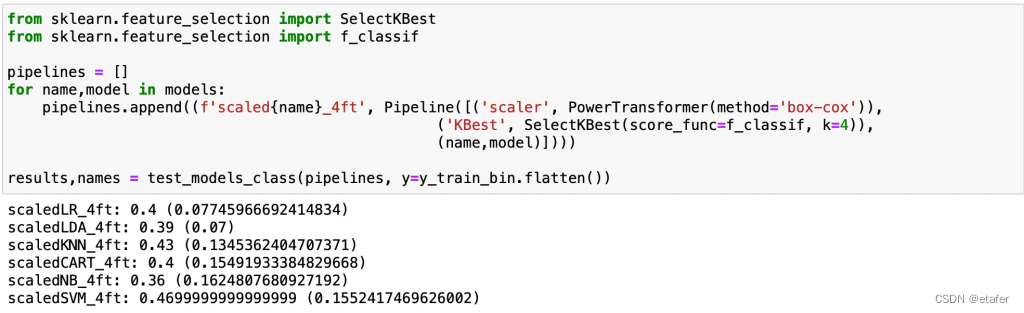
平均得分没有真正的提高,但我们看到逻辑回归和线性判别分析的标准差减少了。现在我将尝试几个集成模型。
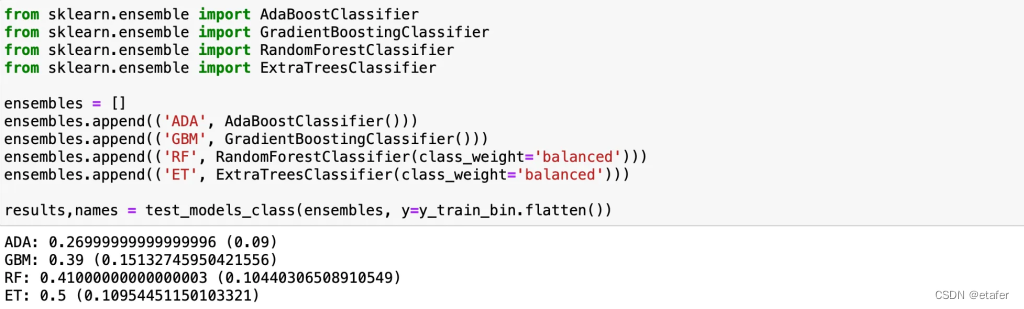
ExtraTreesClassifier在这里似乎是最好的。我将尝试使用网格搜索来调整其参数以提高性能。
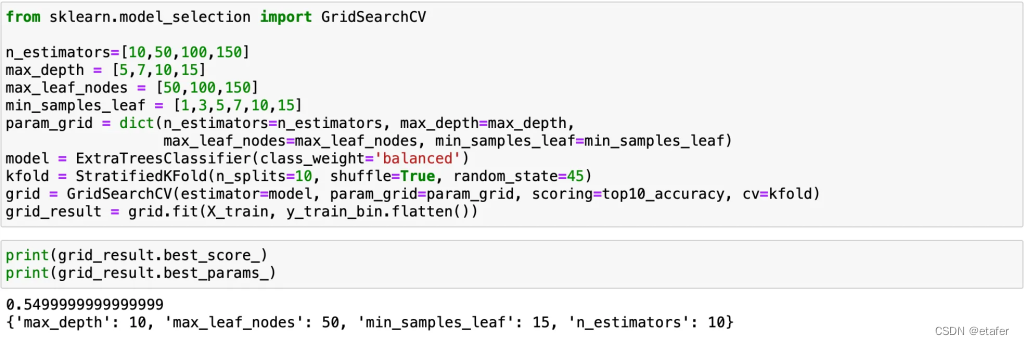
看起来我们能够取得一些小的改进。让我们尝试调整其他几个模型。为了调整逻辑回归模型,我将使用sklearn中包含的LogisticRegressionCV类。

逻辑回归模型没有改进。接下来我会尝试调整SVC。
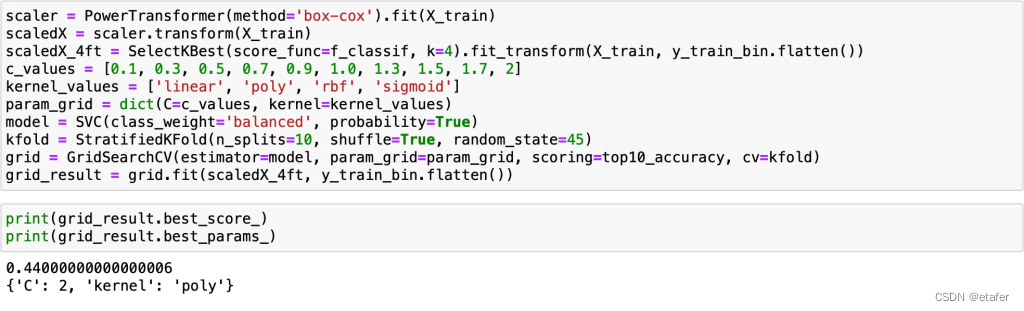
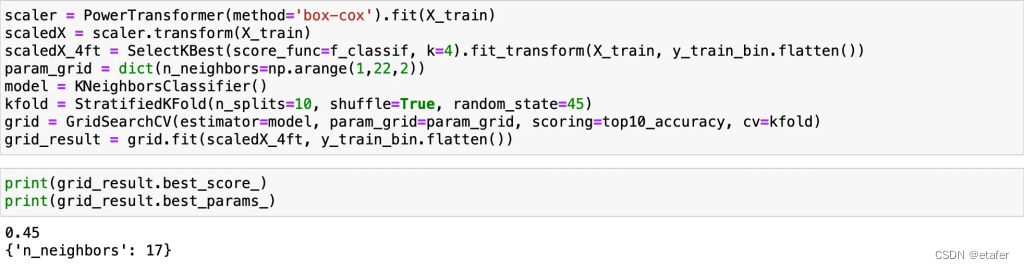
SVC没有改进,KNN只有非常小的提升。总体上,我们只有一个算法在交叉验证期间达到了超过50%的准确率。让我们尝试训练它,并看看它在未见数据上的表现如何。
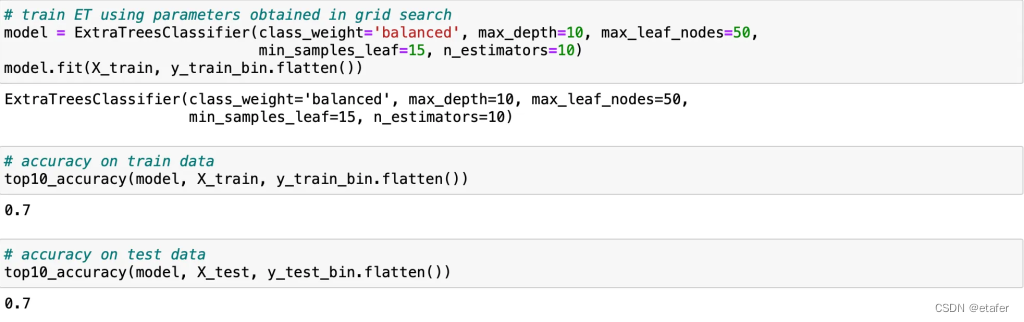
有趣的是,我们在样本内和样本外测试中都能达到70%的准确率。让我们来看看顶级对。
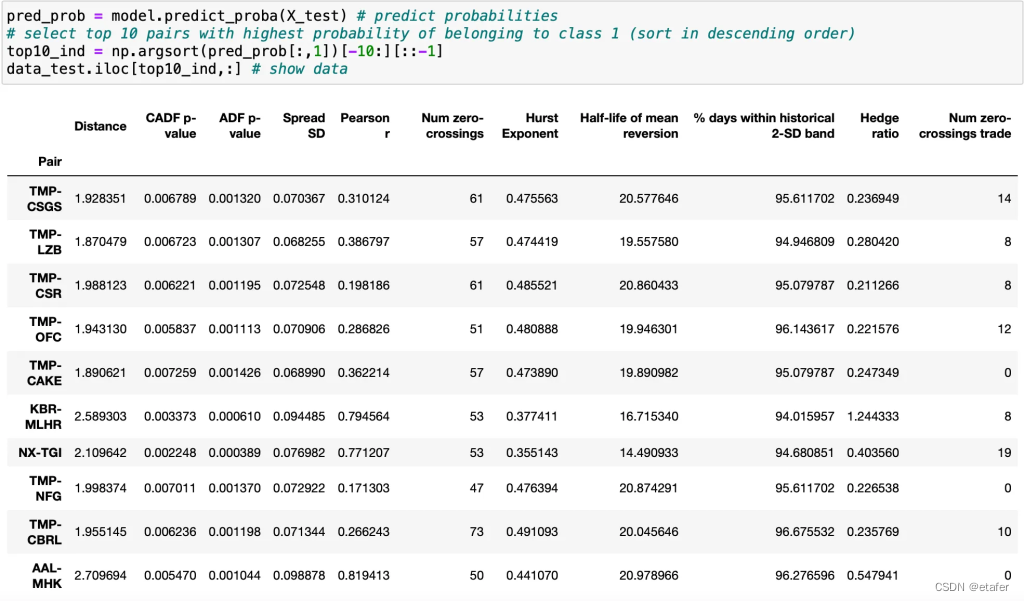
这里奇怪的是,几乎所有的对都包含TMP股票。这显然不利于多样化。另外请注意,这些对中的大多数都有非常小的套保比率,我们可能应该进一步限制其范围。让我们尝试选择包含不同股票的预测前5对。
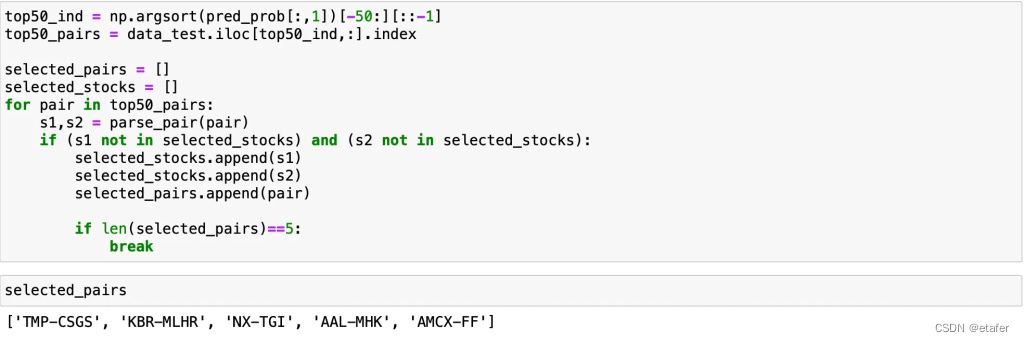
结果并不算太好,但我相信它们比上一篇文章中的结果要好。现在至少大多数对在交易期间保持在其2个标准差带内。
总结
在尝试了不同的机器学习模型之后,我们明白了选择配对交易的对并不是一项简单的任务。所有测试的算法都未能做出良好的预测,最佳模型的准确率略高于50%(相比于30%的基线还是有所提高)。我认为我们可以得出结论,没有任何一种众所周知的简单启发式方法(例如选择欧几里得距离最小的对)能提供更好的结果。
可能的改进:
- 使用异常检测算法进行分类
- 尝试一些其他的特征转换或特征工程
- 尝试更长的形成期
- 使用其他的因变量(例如,欧几里得距离或皮尔逊相关系数)
- 尝试分类那些满足潜在对的所有标准(CADF p值 < 0.01,Hurst指数 <0.5等),但在交易期间。(在我们的训练数据中,这样的对只有33对,共3471对,或许这里可以使用异常检测。)
Jupyter笔记本及源代码可在此处获取。
注意:如果你想在你的笔记本电脑上运行这段代码,你可能想使用较小的股票池;否则可能需要很长时间(尤其是选择潜在对的部分)。你可以在这里下载select_pairs函数的输出:pairs_train, pairs_test。















 2230
2230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









