






配对交易:基于协整的配对选择(3)
系列文章
1 概述
2.1.1 基于距离的配对选择(1)
2.2.1 基于协整的配对选择(1)
前言
我认为我们迄今为止测试的所有配对选择方法的主要缺点是假设整个交易期间市场条件不会改变。我们分析了定价数据,并评估了哪些配对适合在周期开始时仅进行一次交易。然后,我们假设选定配对中的两只股票之间的关系将继续以之前相同的方式表现。我认为这种假设在现代金融市场中是不现实的,因为现代金融市场往往非常动态。
在这篇文章中,我想测试如果我们将交易期限限制为一个月,我们的配对选择方法将如何表现。以下是我想做的:
- 使用12个月的形成期来选择潜在的交易配对(使用与上一篇文章中相同的条件)。
- 在所有潜在配对中,只选择那些在形成期的最后一天距离历史平均值超过2个标准差但少于3个标准差的配对。
- 实施并评估几种机器学习算法在预测选定配对在未来30天内可能收敛的表现。
- 评估所取得的表现是否足以创建一个盈利的交易策略。
我将使用Vanguard Small-Cap Value Index Fund (VBR) 从2016年7月1日到2019年12月31日的历史价格数据。形成期将为12个月长,我将把它向前滚动一个月,以获得总共24个周期。
在处理完所有24个周期后,我们得到了下面的数据集。
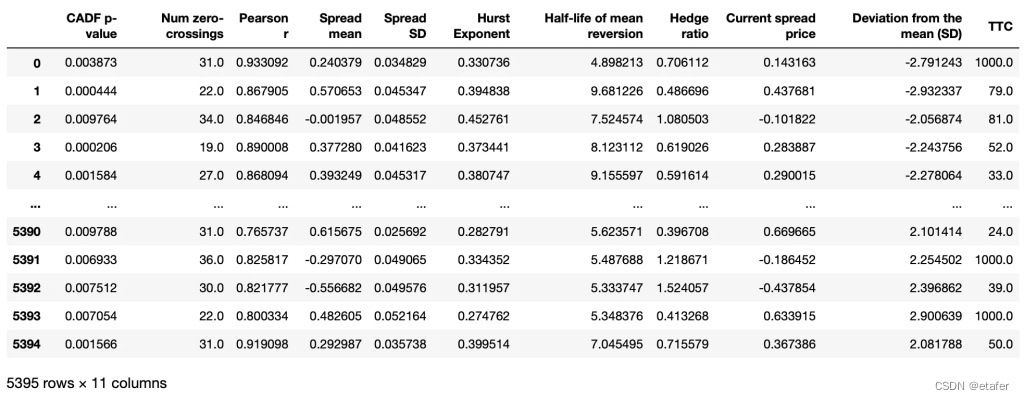
最后一列(TTC)表示价差回归到其历史平均值所需的日历天数。如果在接下来的6个月内价差没有收敛,它的值将为1000。
在进一步处理之前,我会删除对冲比率过大或过小的样本:大于3或小于0.33的样本将被删除。
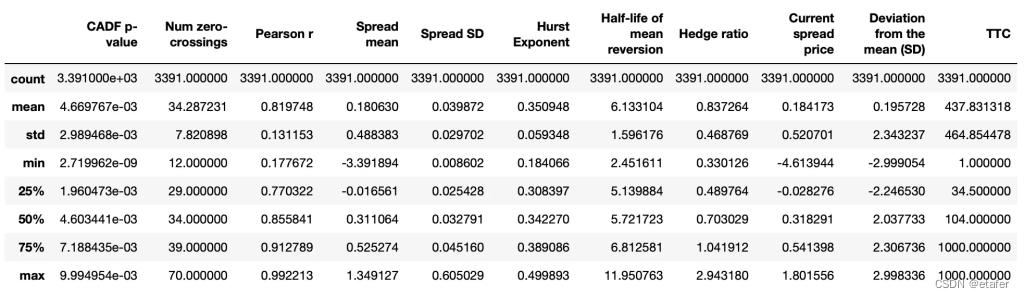
在那之后,我们剩下3391个样本。下面提供了摘要统计信息。
现在让我们看一下相关性矩阵。
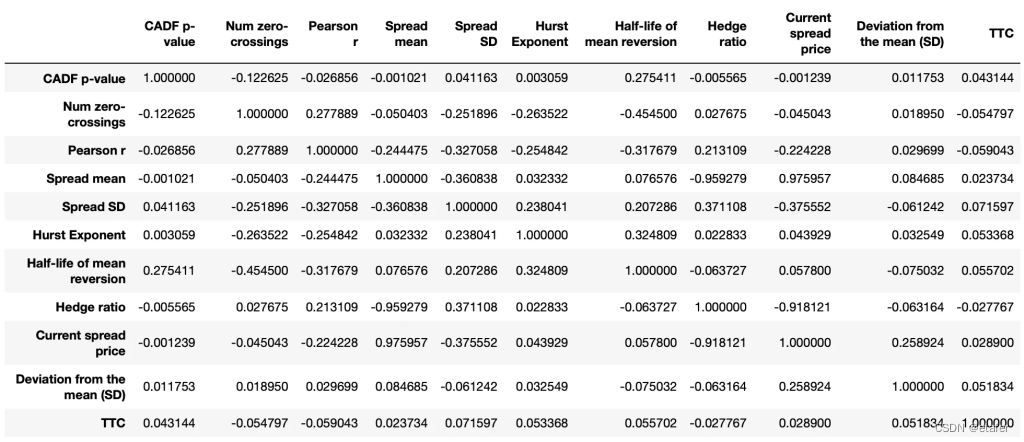
同样,如前面部分所示,我们可以注意到没有任何特征与因变量(TTC)相关。最高的相关系数是0.07。这不是一个好迹象。但是相关性只衡量线性关系,因此仍有可能达到令人满意的结果。
现在我们来看看数据的图表。
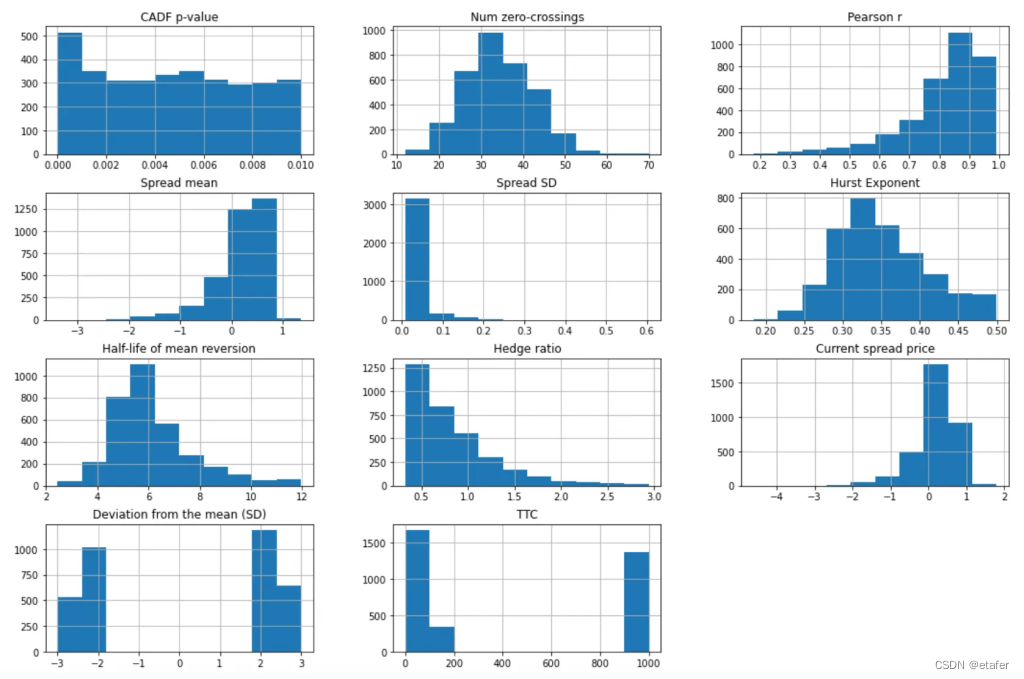
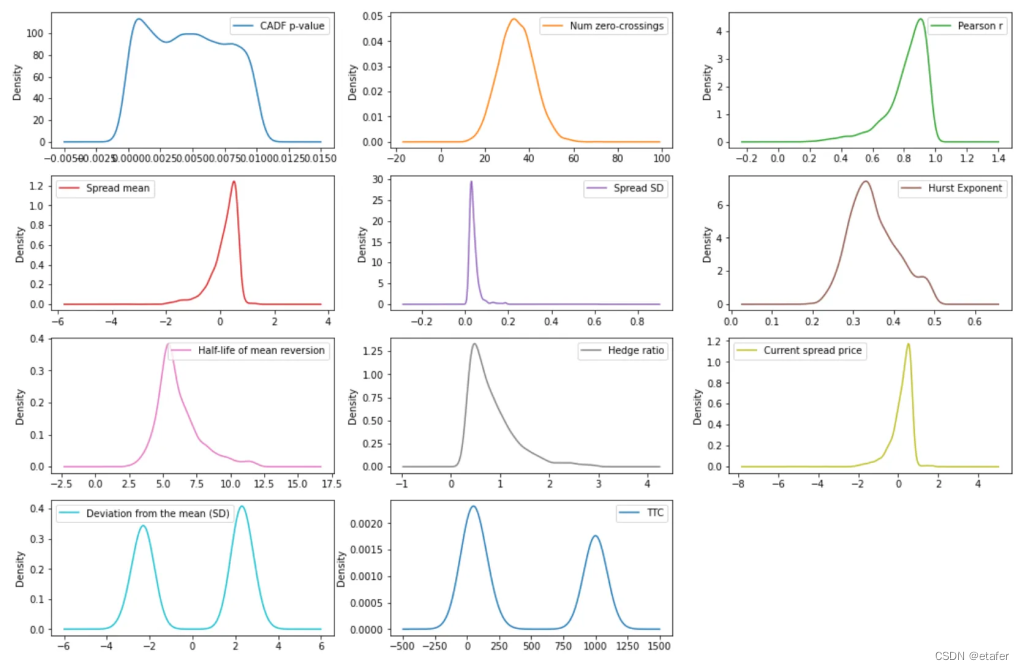
我们可以注意到某些特征的分布是偏态的,因此我们可能希望使用幂变换使它们看起来更像高斯分布。
我使用以下代码为机器学习算法准备数据。因变量(结果变量)被二值化,使得花费超过30天收敛的样本属于1类,花费少于30天收敛的样本属于0类。然后我将数据分成训练集和测试集(70-30),使用分层参数来保持原始数据集的类别分布。
X = data.values[:,:10]
y = data.values[:,10]
binarizer = Binarizer(threshold=30).fit(y.reshape(-1,1))
y_bin = binarizer.transform(y.reshape(-1,1)).flatten()
X_train, X_test, y_train, y_test = train_test_split(X, y_bin, test_size=0.3, shuffle=True,
random_state=14, stratify=y_bin)
我们的任务是预测哪些样本属于0类。我将使用与前面部分相同的自定义准确度评分函数,但稍作修改。我注意到许多机器学习算法不会给所有样本超过50%的概率属于0类。这样的算法对我们的最终目标无用,因为我们需要选择几对进行交易。所以现在我将给任何未能提供至少10个样本属于0类概率超过50%的算法一个0分。下面提供了这个度量的代码。
def top10_accuracy(estimator, X, y):
'''
计算前10个预测的准确率:
选择属于0类概率最高的前10个样本
返回实际属于0类的样本比例
'''
pred_prob = estimator.predict_proba(X)[:,0]
top10_ind = np.argsort(pred_prob)[-10:]
top10_prob = pred_prob[top10_ind]
# 如果前十个概率中至少有一个小于0.5,则返回0分
if len(top10_prob[top10_prob<0.5])>0:
score = 0
else:
score = sum(y[top10_ind] == np.zeros(10))/10
return score
我们还需要计算一个基线准确率,即如果我们随机选择配对时所能达到的准确率。大约是23%。

我将测试以下机器学习算法:
- 逻辑回归
- 线性判别分析
- 二次判别分析
- K近邻
- 决策树
- 朴素贝叶斯
- 高斯过程
- 多层感知机
- 支持向量机
首先,我将在未经任何转换的原始数据上测试它们。下面提供了这些测试的结果。
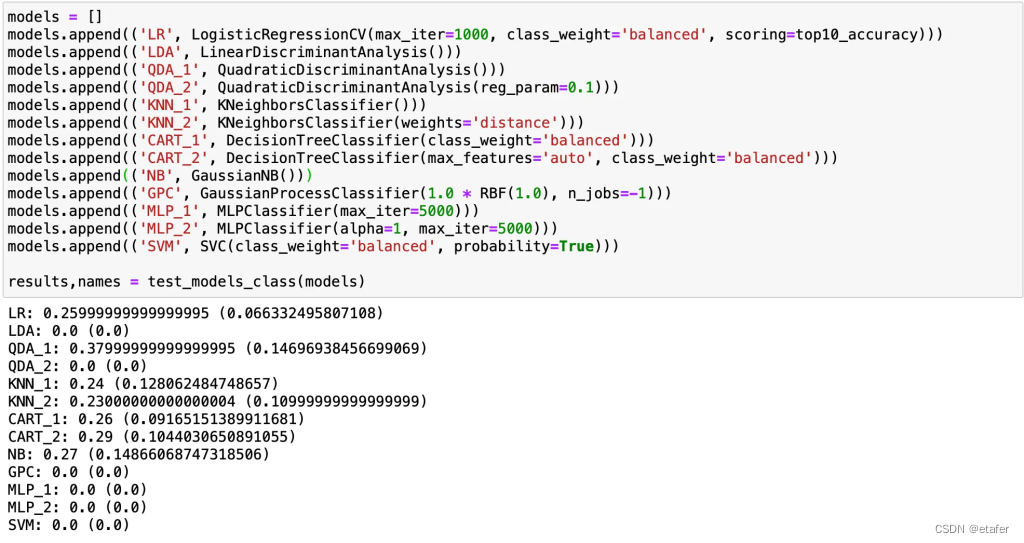
大多数算法的准确率与我们的基线准确率23%相当。我们还可以注意到,几乎有一半的算法得分为零,这意味着它们未能提供至少10个属于0类的概率超过50%的样本。现在,让我们进行相同的测试,但首先使用PowerTransformer转换数据。
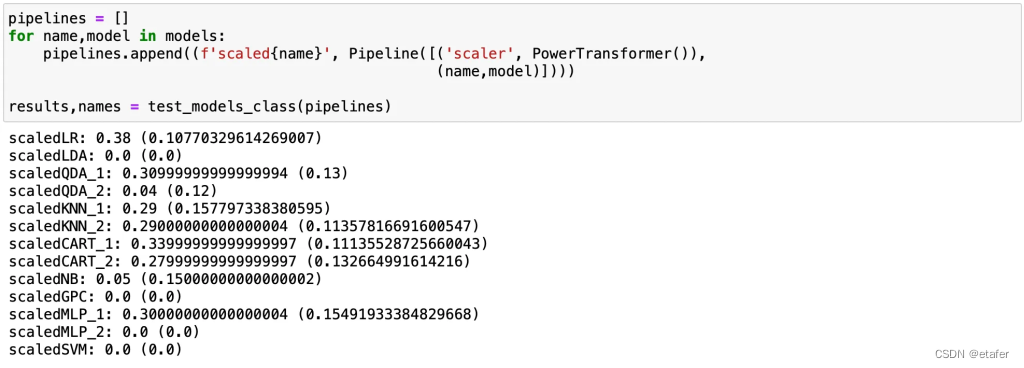
大多数算法的表现与之前大致相同。逻辑回归的表现略有改善。如果我们也尝试应用PCA来减少特征数量呢?
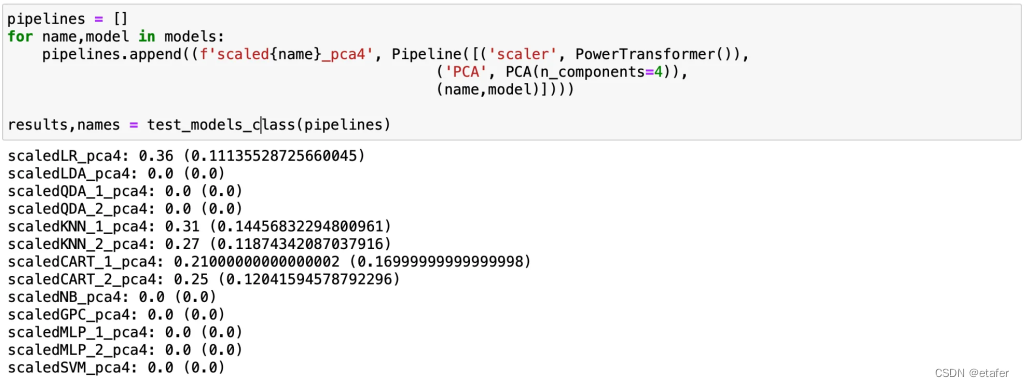
大多数算法的准确率下降。让我们尝试应用几种集成算法。
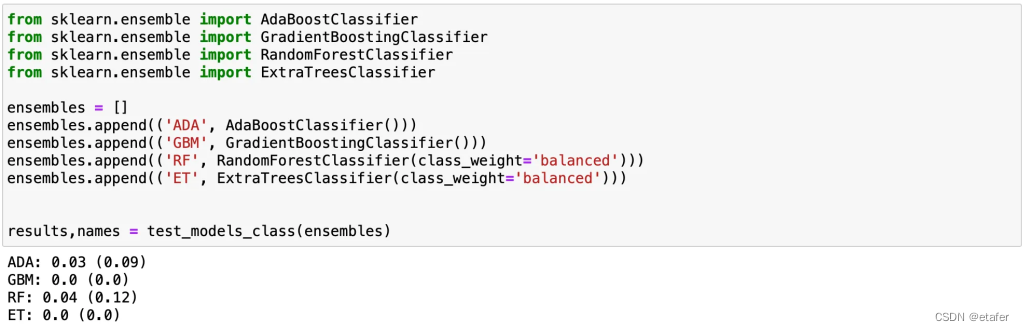
集成模型在这个数据集上表现不佳。
最好的算法只能正确识别大约30-35%的收敛对,这比我们的基线指标略好一些。让我们尝试评估我们其中一个模型的表现。我认为逻辑回归是最佳候选。
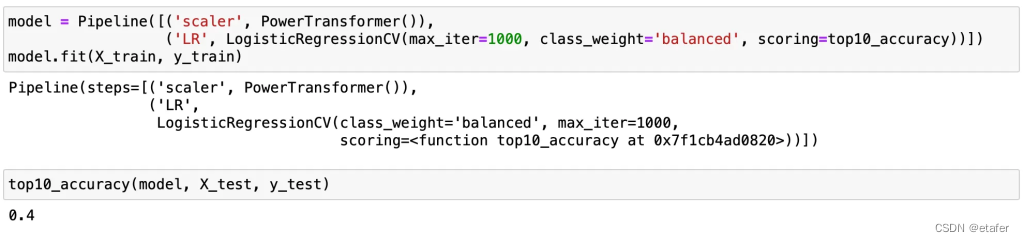
我们达到了0.4的表现,这意味着在接下来的30天内,只有4对中的10对预测对会收敛。如果我们假设从正确识别的对中获得的收益与从错误识别的对中的损失相同,那么这样的表现不足以形成一个盈利的交易策略。
总结
在之前的文章中,我试图找到在接下来的6个月内应表现出均值回归行为的股票对。我所有的尝试都失败了。在这篇文章中,我试图简化任务并将预测时间范围缩短到1个月。然而,我再次未能取得满意的结果。
我们还可以做一些其他的改进:
- 尝试更多不同的数据转换来提高机器学习算法的性能
- 使用特征工程为数据添加一些新特征
- 收集更多数据
- 找到一种即使不到50%的预测对实际收敛也能盈利的策略(例如以这样的方式创建我们的交易规则:我们在收敛对上获得的收益超过在非收敛对上的损失)
我认为我迄今为止测试的不同方法的最大缺点是没有使用最新市场数据。我们应该尽可能快地将新数据纳入我们的模型中(至少每天一次),使用这些数据更新我们对市场的看法并相应调整我们的头寸。另一个可能的缺点是这些方法非常知名且非常简单,这意味着很多人都在使用它们,交易机会很快就会消失。在接下来的文章中,我将尝试测试更高级的配对交易方法和技术。
包含源代码的Jupyter笔记本可以在这里获取。
注意:如果你想在你的笔记本电脑上运行这段代码,你可能想使用较小的股票组合;否则可能需要很长时间。你可以在这里下载我用于机器学习部分的数据集。















 4250
4250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









