






配对交易:基于协整的配对选择(1)
系列文章
1 概述
2.1.1 基于距离的配对选择(1)
2.2.1 基于协整的配对选择(1)
感谢原作者Alexander授权我进行翻译,原文链接为:https://financialnoob.me/pairs-trading-pair-selection-cointegration-part-1/
在组建一对股票的投资组合时,我们默认了给这对股票平均分配资本。这样的做法可能就限制了咱们后续分析的股票对的数量。即使是受同样风险因素影响的两只股票,这些因素对它们的影响力度也不见得是一样的。
来,咱们假设个例子。假如有两只股票:A股和B股。它们都受到同一个风险因素F的影响,这个因素按照随机漫步的模式变动,但它们对这个风险因素的依赖程度(我们通常称之为“贝塔值”)是不一样的。更具体点说,就是下面这样:

这个公式描述了两只股票价格与一个共同风险因素的数学关系。股票A和股票B的价格(
P
a
,
t
P_{a,t}
Pa,t和
P
b
,
t
P_{b,t}
Pb,t)和被设定为受到同一个风险因素
F
t
F_t
Ft的影响加上一个随机干扰项(
w
a
,
t
w_{a,t}
wa,t和
w
b
,
t
w_{b,t}
wb,t)。
具体来说:
P
a
,
t
=
1.5
∗
F
t
+
w
a
,
t
P_{a,t} = 1.5 * F_t+w_{a,t}
Pa,t=1.5∗Ft+wa,t这表明股票A的价格是风险因素
F
t
F_t
Ft的1.5倍加上一个服从正态分布
N
(
0
,
1
)
N(0,1)
N(0,1)的随机干扰项
w
a
,
t
w_{a,t}
wa,t。这里的1.5可以被理解为股票A对风险因素的敏感度或者贝塔值。
P
b
,
t
=
0.5
∗
F
t
+
w
b
,
t
P_{b,t} = 0.5 * F_t+w_{b,t}
Pb,t=0.5∗Ft+wb,t这说明股票B的价格是风险因素
F
t
F_t
Ft的0.5倍加上另一个随机干扰项
w
b
,
t
w_{b,t}
wb,t,它也服从正态分布
N
(
0
,
1
)
N(0,1)
N(0,1)。这里的0.5代表股票B对风险因素的敏感度较低。
这里的
F
t
F_t
Ft代表风险因素,在时间点t的状态,它遵循一个随机漫步过程,意味着它的下一个状态是由当前状态加上一个随机变化决定的。
w
a
,
t
w_{a,t}
wa,t和
w
b
,
t
w_{b,t}
wb,t是随机干扰项,代表除了风险因素
F
F
F之外的其他影响,它们假设服从均值为0,标准差为1的正态分布,这是一个常见的假设,代表这些干扰项是随机的,没有系统性偏差,且变化范围(波动性)是标准化的。
import pandas as pd
import numpy as np
# 生成随机漫步过程
np.random.seed(112)
F = [15]
for i in range(252):
F.append(F[i] + np.random.randn())
F = np.array(F)
# 生成价格序列
P_a = 1.5*F + np.random.randn(len(F))
P_b = 0.5*F + np.random.randn(len(F))

如果我们通过对每只股票分配相同的资金来构建一个配对投资组合(比如,买入股票A,卖空股票B),我们将无法抵消掉那个“随机漫步”的部分,因此我们的投资组合就不会是稳定的。你看下面的情况,这个组合的平均值是不稳定的。这是因为在我们的投资组合价格序列中,还存在着一个随机漫步成分。
这里的“随机漫步”用来形容一个可能朝任意方向移动的不确定性因素,就像醉汉走路一样,下一步往哪儿走完全是随机的。在这个例子中,意味着即便我们在两只股票之间分配了相同的资金,但是由于每只股票对风险的反应不一样,所以我们的投资组合总体上还是会受到市场随机因素的影响,导致投资结果不确定。


不过注意,创建一个稳定的投资组合还是有可能的,我们只需要调整投资组合中股票的权重,以便可以抵消掉随机漫步成分。我们新投资组合的公式将是这样的:

对于投资组合中分配给股票A多头仓位的每一个单位资金,我们分配对冲比率(hedge_ratio)个单位的资金给股票B的空头仓位。
为了计算这个对冲比率,我们可以使用最小二乘法(Ordinary Least Squares, OLS)进行计算。计算对冲比率以及绘制结果投资组合图表的代码如下。
from statsmodels.regression.linear_model import OLS
# 计算对冲比率
res = OLS(P_a, P_b).fit()
hedge_ratio = res.params[0]
# 使用计算得出的比率创建投资组合
spread_hr = P_a - hedge_ratio*P_b
plt.figure(figsize=(18,6))
plt.plot(spread_hr, label='spread (hedge ratio)')
plt.legend()
这个投资组合比我们用等权重构建的那个看起来稳定多了。
基本上,如果我们有两个时间序列,而且能够构造出它们的线性组合是稳定的(具有常数的平均值和方差),那么这些时间序列就被认为是协整的。(这不是一个严格的数学定义,但它解释了基本原理)。让我们尝试对我们的价格序列应用协整检验(Cointegrated Augmented Dicker-Fuller test),以确认它们是否确实协整。

第二个数字是P值,它非常接近零,所以我们可以拒绝原假设,即价格序列不是协整的。因此,当我们有两只价格协整的股票时,我们可以尝试使用上述方法来创建一个均值回归的投资组合。现在,让我们试着将这种方法应用到真实数据上。
在之前关于配对选择的距离方法的文章中,我演示了许多被选出的股票对根据CADF测试是协整的,所以我们现在知道,仅仅选择CADF p值小于0.01的股票对是不够的,这并不能保证这些股票对在接下来的交易期间仍然保持协整。因此,在这篇文章中,我将结合之前我用过的一些测试方法和协整方法。
在第一部分,我将执行与前几篇文章中相同的测试,但现在我将允许价差为每只股票赋予不同的权重。提醒一下,我将只选择那些满足以下条件的股票对:
- 协整的(CADF p值 < 0.01)
- 价差的赫斯特指数 < 0.5
- 价差的均值回归半衰期超过1天且小于30天
- 价差的零交叉次数 > 每年12次
赫斯特指数 (Hurst exponent):
- 这是用来衡量时间序列长期记忆性的一个指标。数值范围通常在0到1之间。
- 如果指数小于0.5,意味着时间序列展示出反持续性,即当前发生的趋势->- 未来可能会逆转,这通常与均值回归行为相关联。
- 如果指数等于0.5,表明序列是完全随机的,类似于随机漫步。
- 如果指数大于0.5,意味着序列具有持续性,当前的趋势未来很可能会继续。
均值回归半衰期 (Half-life of mean reversion):
- 这个概念来源于物理学中的“半衰期”,它用来衡量一个偏离平均值的时间序列回到平均值所需的时间。
- 在金融分析中,均值回归半衰期是指一个价格序列回到其历史均值所需时间的估计。时间越短,表明股价回到均值的速度越快。
这个概念来源于物理学中的“半衰期”,它用来衡量一个偏离平均值的时间序列回到平均值所需的时间。
零交叉次数 (Number of zero crossings):
- 这是指时间序列在其均值水平上下波动时穿过均值线的次数。
在股票市场分析中,我们关注的通常不是零交叉,而是历史均值交叉次数,即价格序列穿越其历史平均价格的次数。- 这个指标反映了市场波动性的一个方面。交叉次数越多,表明价格波动越频繁。
在第二部分,我会尝试结合几个指标并使用一些机器学习技术来确定哪些股票对应选作交易。
注:在我开始写这篇文章的时候,我意识到在用来计算某些指标的函数中犯了一些小错误:
- 我们应该计算历史均值交叉的次数,而不是零交叉的次数。以前这不重要,因为大多数价差的均值非常接近零,但现在不是这样。我们现在可以有均值远离零的价差。
- 图表上的2-SD带是围绕零而不是历史均值计算的。再次强调,以前这不重要,但现在,由于上述相同的原因,它变得重要了。
“2-SD带”指的是“两个标准差(Standard Deviation)带”
def parse_pair(pair):
'''
函数接收一个字符串参数,该字符串应该包含两个股票的代码,中间用短横线(-)分隔。
函数会找到短横线的位置,然后分别提取出两个股票的代码,并返回。
'''
dp = pair.find('-')
s1 = pair[:dp]
s2 = pair[dp+1:]
return s1,s2
def cadf_pvalue(s1, s2, cumret):
'''
函数接收两个股票代码和一个累积收益率的DataFrame,然后对这两个股票进行协整测试。
协整测试是一种统计方法,用于检验两个时间序列是否存在长期的均衡关系。
这个函数会对两个股票进行两次协整测试(一次以s1为因变量,一次以s2为因变量),
然后返回两次测试中p值较小的一个。
'''
from statsmodels.tsa.stattools import coint
p1 = coint(cumret[s1], cumret[s2])[1]
p2 = coint(cumret[s2], cumret[s1])[1]
return min(p1,p2)
def calculate_halflife(spread):
'''
函数接收一个价差序列,然后计算这个价差的半衰期。
半衰期是一个重要的统计指标,用于衡量价差回归到均值所需要的时间。这个函数首先计算价差的滞后值和差分值,然后用滞后值对差分值进行回归,得到回归系数。
最后,用对数函数和回归系数计算出半衰期。
'''
from statsmodels.regression.linear_model import OLS
from statsmodels.tools.tools import add_constant
ylag = spread.shift()
deltay = spread - ylag
ylag.dropna(inplace=True)
deltay.dropna(inplace=True)
res = OLS(deltay, add_constant(ylag)).fit()
halflife = -np.log(2)/res.params[0]
return halflife
def calculate_metrics(pairs, cumret, pairs_df):
'''
函数接收一个股票对列表、一个累积收益率的DataFrame和一个股票对的DataFrame
然后计算每个股票对的一些统计指标,包括距离、协整测试的p值、ADF测试的p值、价差的标准差、皮尔逊相关系数、零交叉次数、赫斯特指数、半衰期和在历史2-SD带内的天数比例。
这些指标都存储在一个新的DataFrame中,并返回。
'''
from hurst import compute_Hc
from statsmodels.tsa.stattools import adfuller
from statsmodels.regression.linear_model import OLS
from statsmodels.tools.tools import add_constant
from statsmodels.tsa.stattools import coint
cols = ['Distance', 'CADF p-value', 'ADF p-value', 'Spread SD', 'Pearson r',
'Num zero-crossings', 'Hurst Exponent', 'Half-life of mean reversion', '% days within historical 2-SD band']
results = pd.DataFrame(index=pairs, columns=cols)
for pair in pairs:
s1,s2 = parse_pair(pair)
hedge_ratio = pairs_df.loc[pair]['Hedge ratio']
spread = cumret[s1] - hedge_ratio*cumret[s2]
results.loc[pair]['CADF p-value'] = coint(cumret[s1], cumret[s2])[1]
results.loc[pair]['ADF p-value'] = adfuller(spread)[1]
hist_mu = pairs_df.loc[pair]['Spread mean'] # historical mean
hist_sd = pairs_df.loc[pair]['Spread SD'] # historical standard deviation
results.loc[pair]['Spread SD'] = hist_sd
results.loc[pair]['Pearson r'] = np.corrcoef(cumret[s1], cumret[s2])[0][1]
# subtract the mean to calculate distances and num_crossings
spread_nm = spread - hist_mu
results.loc[pair]['Distance'] = np.sqrt(np.sum((spread_nm)**2))
results.loc[pair]['Num zero-crossings'] = ((spread_nm[1:].values * spread_nm[:-1].values) < 0).sum()
results.loc[pair]['Hurst Exponent'] = compute_Hc(spread)[0]
results.loc[pair]['Half-life of mean reversion'] = calculate_halflife(spread)
results.loc[pair]['% days within historical 2-SD band'] = (abs(spread-hist_mu) < 2*hist_sd).sum() / len(spread) * 100
return results
def plot_pairs(pairs, cumret_train, cumret_test):
'''
函数接收一个股票对列表和两个累积收益率的DataFrame(一个用于训练,一个用于测试),然后对每个股票对的价差进行绘图。图中包括价差的历史均值和2-SD带。
'''
from statsmodels.regression.linear_model import OLS
from statsmodels.tools.tools import add_constant
for pair in pairs:
s1,s2 = parse_pair(pair)
res = OLS(cumret_train[s1], add_constant(cumret_train[s2])).fit()
spread_train = cumret_train[s1] - res.params[s2]*cumret_train[s2]
spread_test = cumret_test[s1] - res.params[s2]*cumret_test[s2]
spread_mean = spread_train.mean() # historical mean
spread_std = spread_train.std() # historical standard deviation
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18,4))
fig.suptitle(f'Spread of {pair} pair', fontsize=16)
ax1.plot(spread_train, label='spread')
ax1.set_title('Formation period')
ax1.axhline(y=spread_mean, color='g', linestyle='dotted', label='mean')
ax1.axhline(y=spread_mean+2*spread_std, color='r', linestyle='dotted', label='2-SD band')
ax1.axhline(y=spread_mean-2*spread_std, color='r', linestyle='dotted')
ax1.legend()
ax2.plot(spread_test, label='spread')
ax2.set_title('Trading period')
ax2.axhline(y=spread_mean, color='g', linestyle='dotted', label='mean')
ax2.axhline(y=spread_mean+2*spread_std, color='r', linestyle='dotted', label='2-SD band')
ax2.axhline(y=spread_mean-2*spread_std, color='r', linestyle='dotted')
ax2.legend()
def select_pairs(train):
'''
函数接收一个DataFrame,然后选择满足一定条件的股票对。
选择的条件包括协整测试的p值小于0.01、对冲比率大于0、赫斯特指数小于0.5、半衰期在1到30之间、零交叉次数大于数据长度的一半。
满足这些条件的股票对会被添加到一个新的DataFrame中,并返回。
'''
tested = []
from statsmodels.regression.linear_model import OLS
from statsmodels.tools.tools import add_constant
from hurst import compute_Hc
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.stattools import coint
cols = ['Distance', 'Num zero-crossings', 'Pearson r', 'Spread mean',
'Spread SD', 'Hurst Exponent', 'Half-life of mean reversion', 'Hedge ratio']
pairs = pd.DataFrame(columns=cols)
for s1 in train.columns:
for s2 in train.columns:
if s1!=s2 and (f'{s1}-{s2}' not in tested):
tested.append(f'{s1}-{s2}')
cadf_p = coint(train[s1], train[s2])[1]
if cadf_p<0.01 and (f'{s2}-{s1}' not in pairs.index): # stop if pair already added as s2-s1
res = OLS(train[s1], add_constant(train[s2])).fit()
hedge_ratio = res.params[s2]
if hedge_ratio > 0: # hedge ratio should be posititve
spread = train[s1] - hedge_ratio*train[s2]
hurst = compute_Hc(spread)[0]
if hurst<0.5:
halflife = calculate_halflife(spread)
if halflife>1 and halflife<30:
# subtract the mean to calculate distances and num_crossings
spread_nm = spread - spread.mean()
num_crossings = (spread_nm.values[1:] * spread_nm.values[:-1] < 0).sum()
if num_crossings>len(train.index)/252*12:
distance = np.sqrt(np.sum(spread_nm**2))
pearson_r = np.corrcoef(train[s1], train[s2])[0][1]
pairs.loc[f'{s1}-{s2}'] = [distance, num_crossings, pearson_r, spread.mean(),
spread.std(), hurst, halflife, hedge_ratio]
return pairs
12个月的形成期 / 6个月的交易期
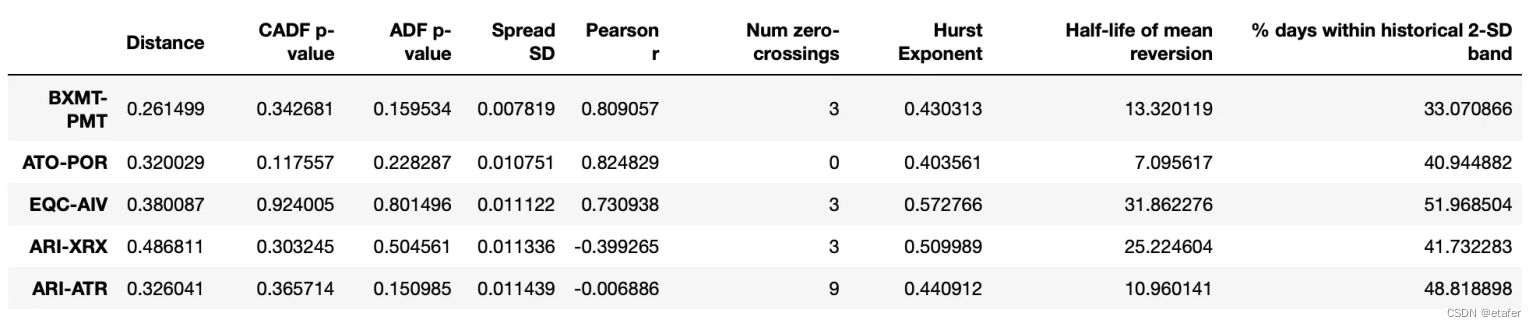
在测试了263901对可能的股票对后,我们找到了4760对满足所有标准的股票对(相较于使用等权重投资组合发现的1703对)。所以我们有了几乎是之前三倍的潜在股票对。
既然我们知道可以构建非等权重的配对投资组合,我们就不再使用两只股票价格之间的欧几里得距离了。相反,我将选择那些与其历史均值之间距离最小的股票对。下面你可以看到被选中的股票对以及它们投资组合的图表。
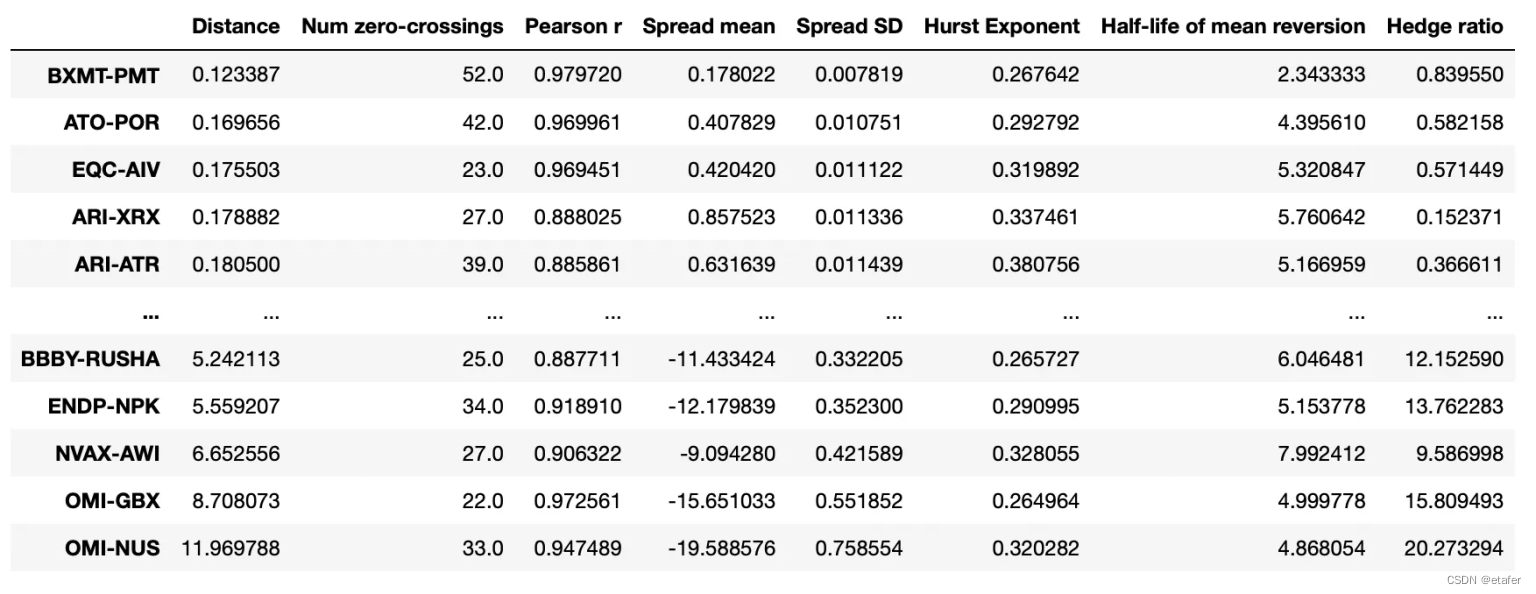
Distance:这是两个股票的累积收益率之差(即价差)与其历史均值之差的平方和的平方根。这个指标可以反映价差的波动程度。
Pearson r:这是两个股票的累积收益率的皮尔逊相关系数。这个指标可以反映两个股票的收益率是否存在线性关系。
Spread mean:这是两个股票的累积收益率之差(即价差)的历史均值。这个指标可以反映价差的中心位置。
Spread SD:这是两个股票的累积收益率之差(即价差)的历史标准差。这个指标可以反映价差的波动程度。
Hurst Exponent:这是价差的赫斯特指数。
Half-life of mean reversion:这是价差的均值回归半衰期。这个指标可以反映价差回归到均值所需要的时间。
Hedge ratio:这是对冲比率,也就是在构建价差时,两个股票的权重比例。这个指标可以反映在对冲交易中,应该如何分配资金到两个股票上。
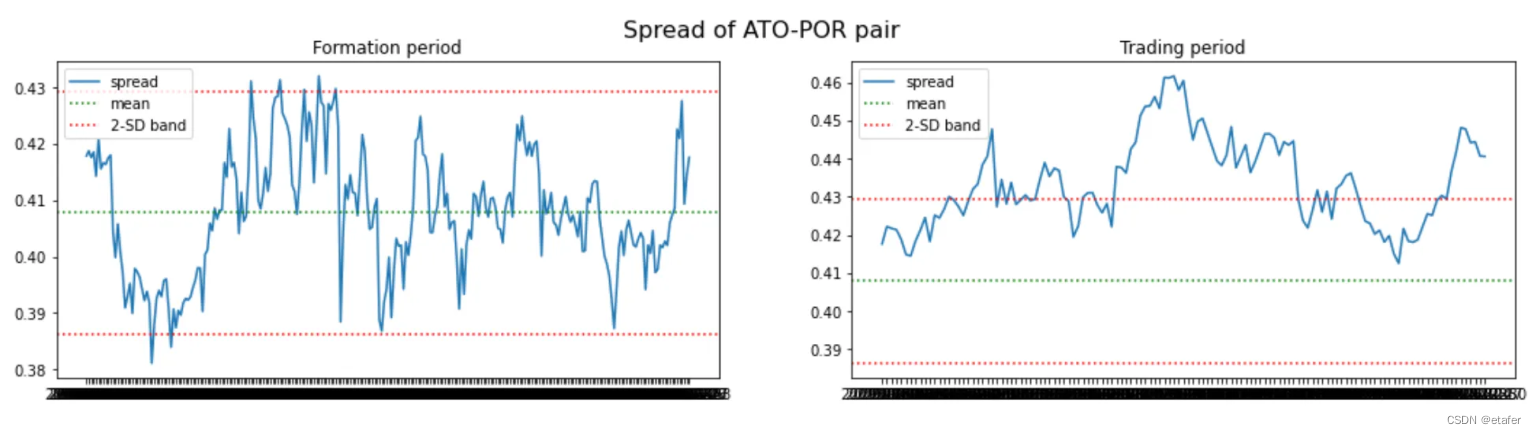
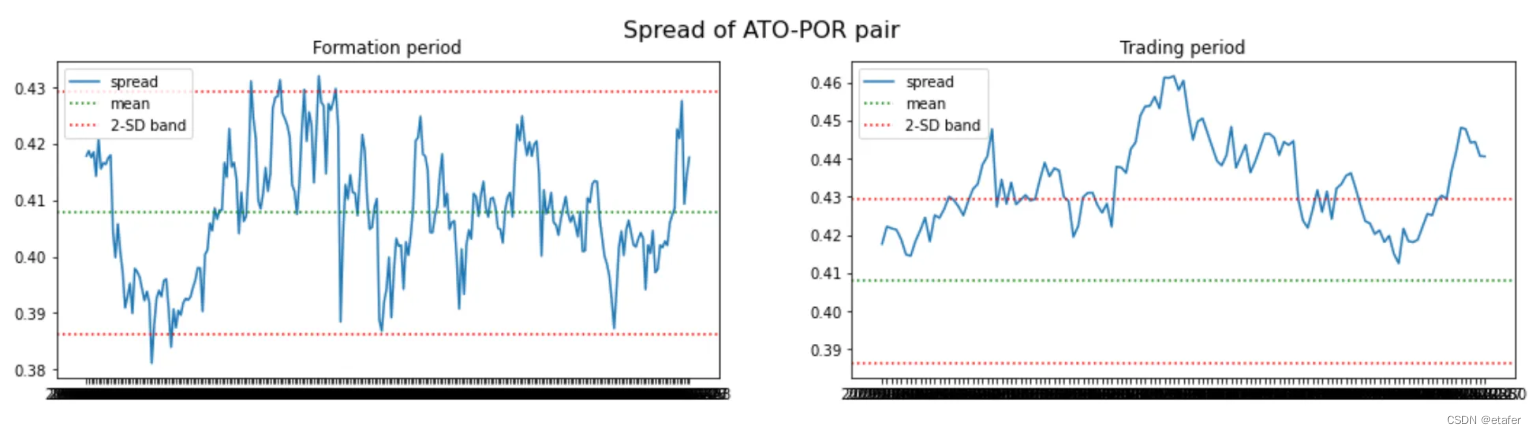
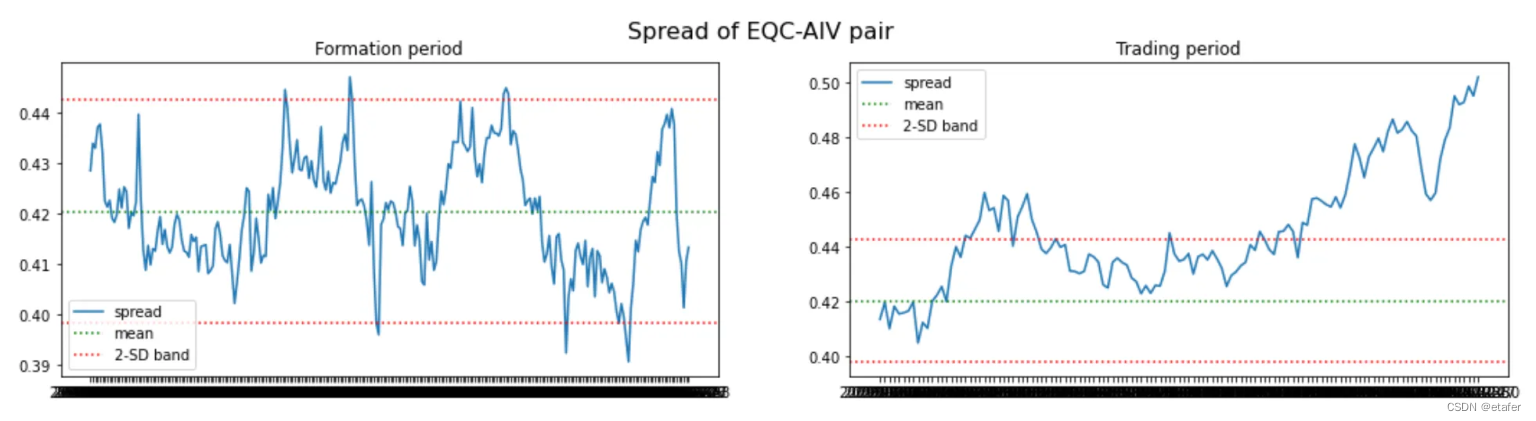
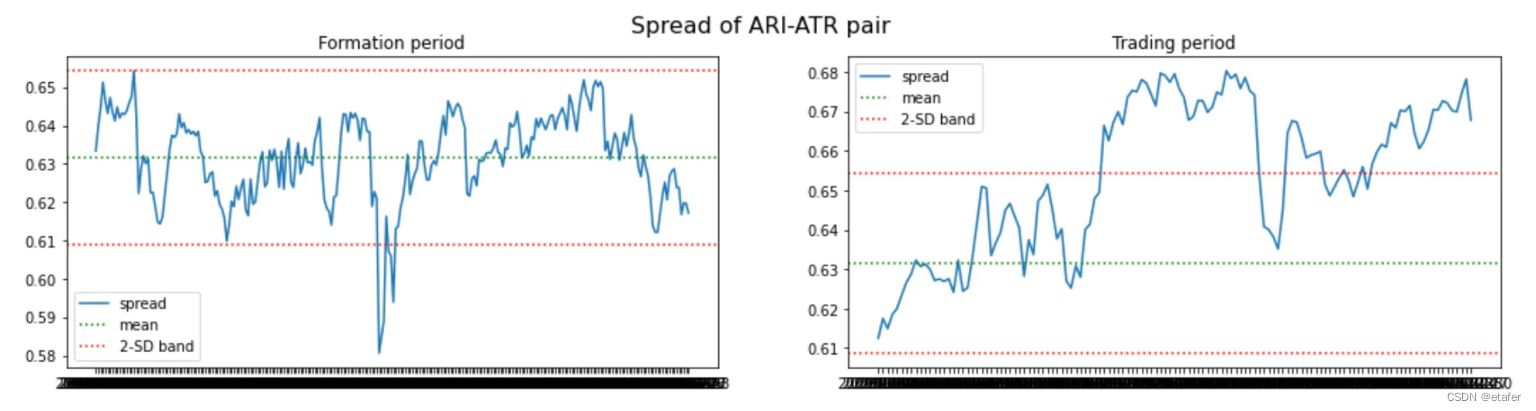
ADF是指Augmented Dickey-Fuller(ADF)测试,这是一种用于检验时间序列数据是否存在单位根的统计测试。单位根是一种特性,如果一个时间序列数据具有单位根,那么这个序列就是非平稳的,也就是说,它的统计特性(如均值和方差)会随着时间的推移而改变。
又是没有实质性的进步。或许我们应该尝试延长形成期?
36个月的形成期 / 6个月的交易期
在这里,我找到了2639对潜在的股票对,相比之前的236对,多了十倍还要多。让我们看看这是否会提高我们选出来用于交易的股票对的质量。
距离均值欧氏距离最小的股票对:
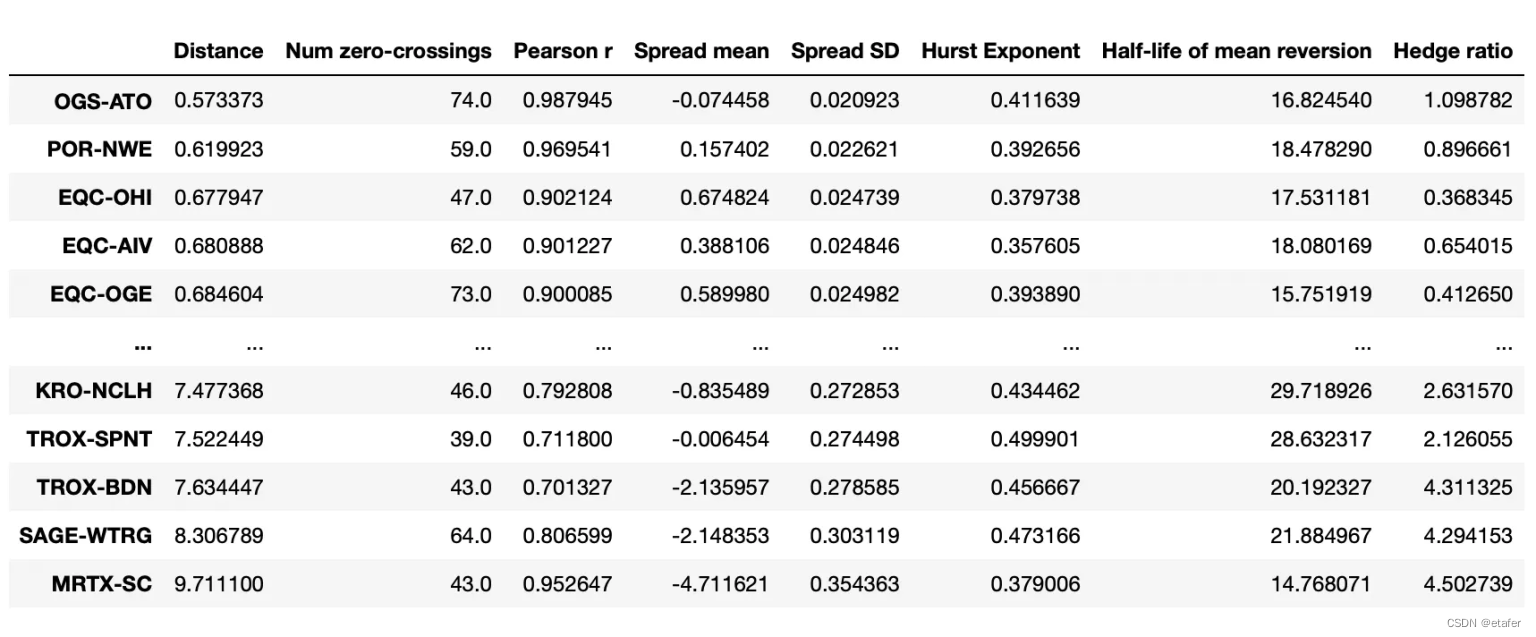
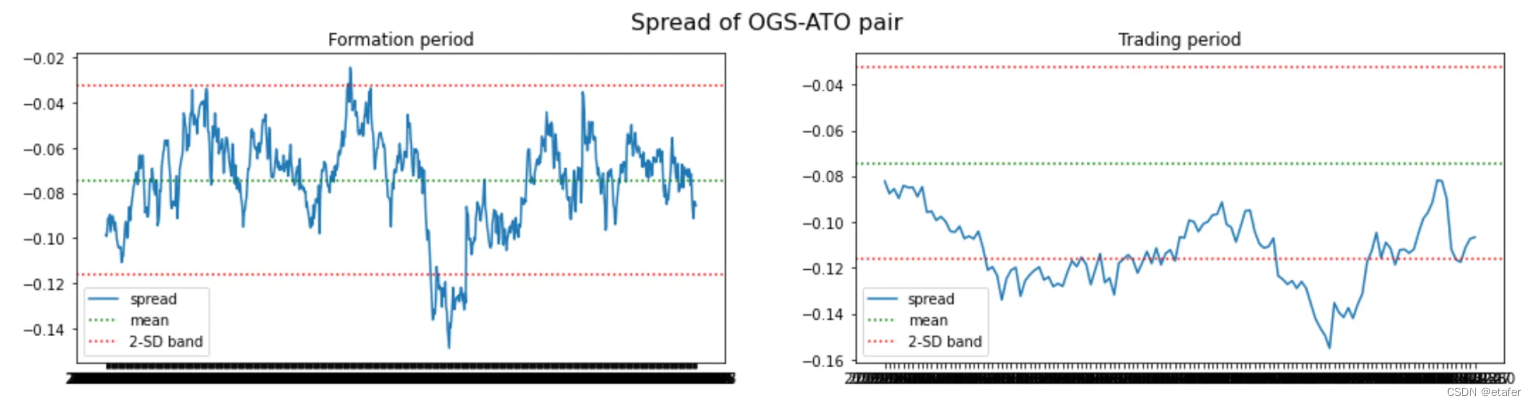
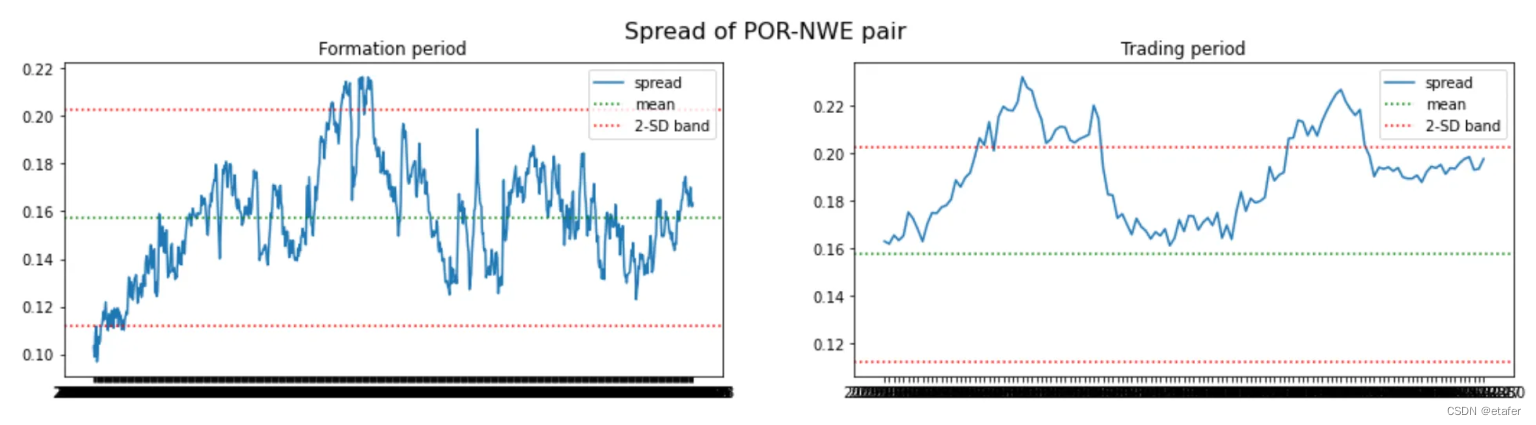
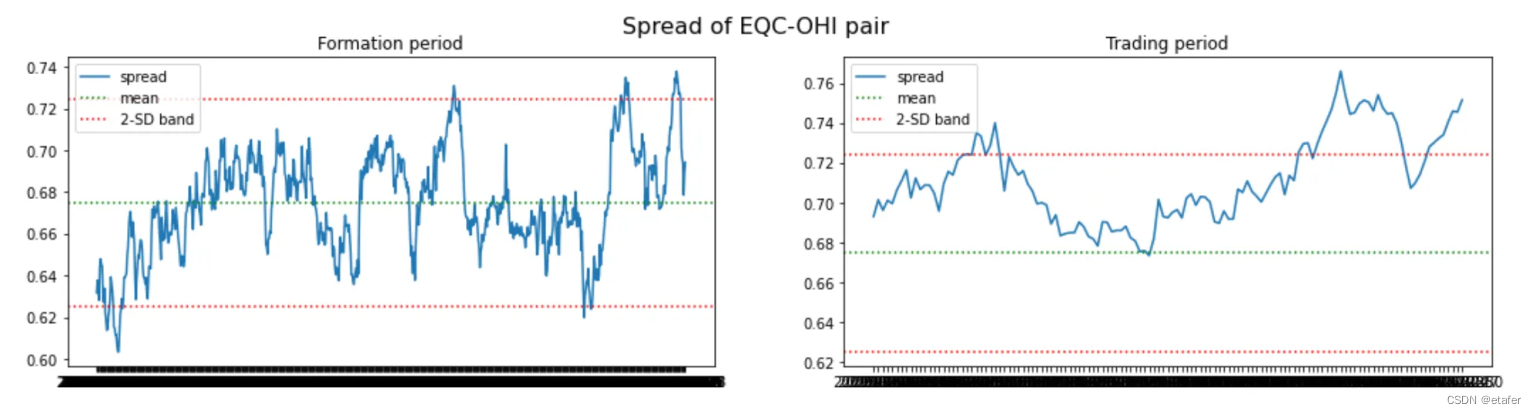
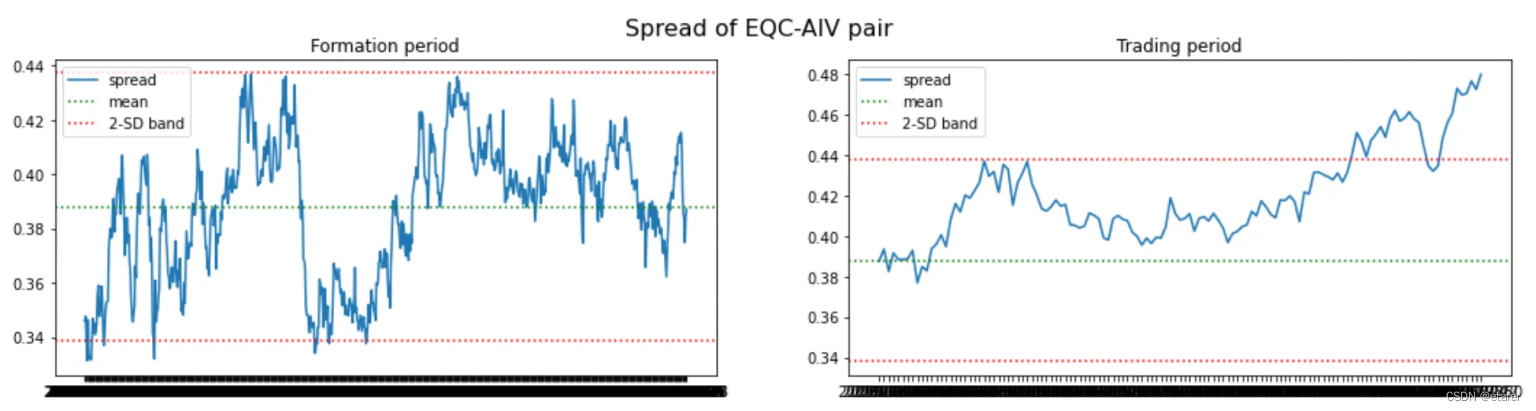
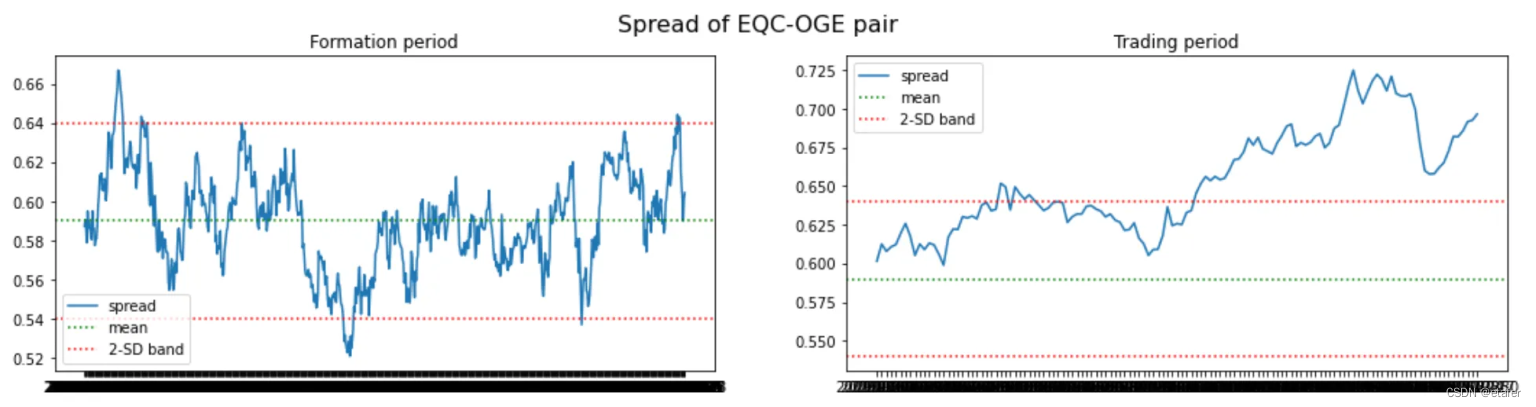
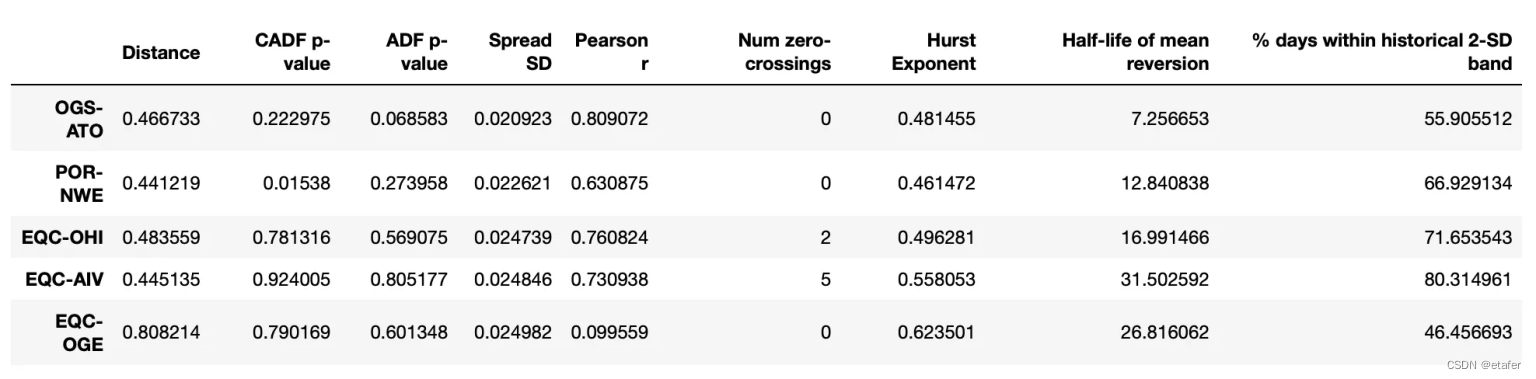
我们再次看到,大多数股票对偏离它们的历史均值太远。有趣的是,最后三对股票对都包含同一只股票(EQC)。我们可能会想避免交易这样的股票对。拥有一个多对股票组成的投资组合,如果有几对包含相同的股票,那么它对来自该股票的风险就非常敏感。如果EQC的价格因为一些特定于该公司的新闻而大幅上涨或下跌,我们将在所有这三对中遭受损失,因为它们都会偏离。
现在,我们将选择零交叉次数最多的股票对。
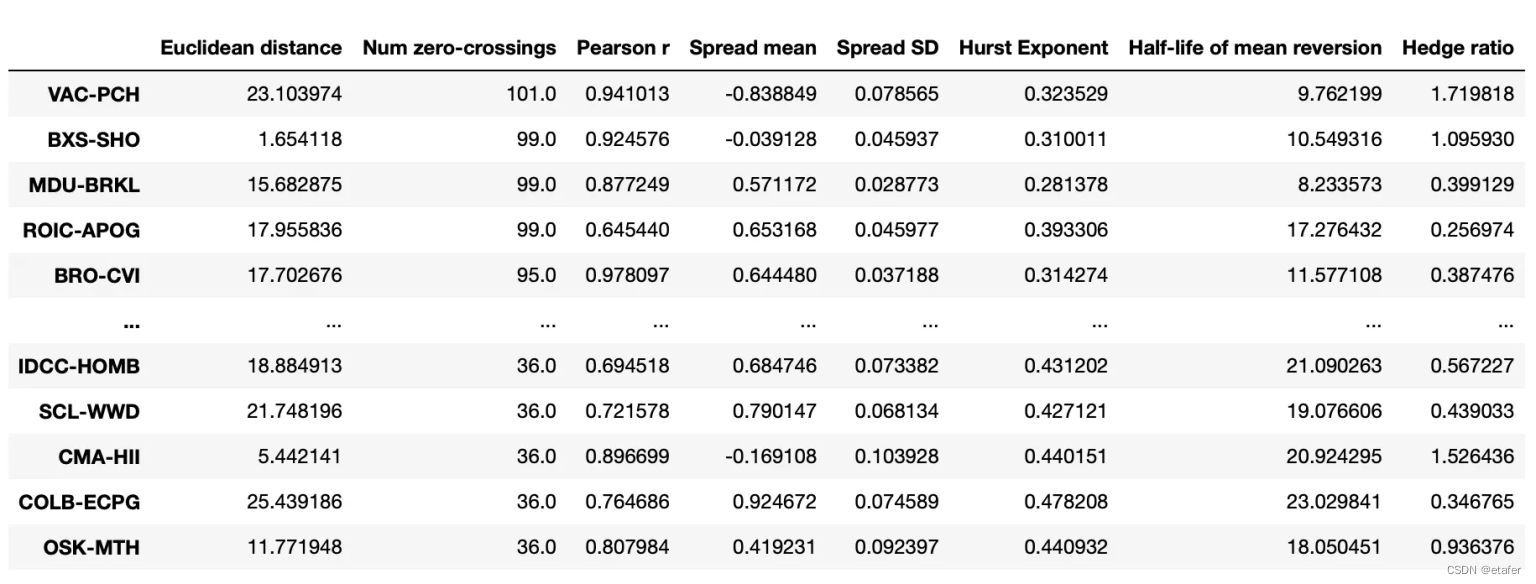
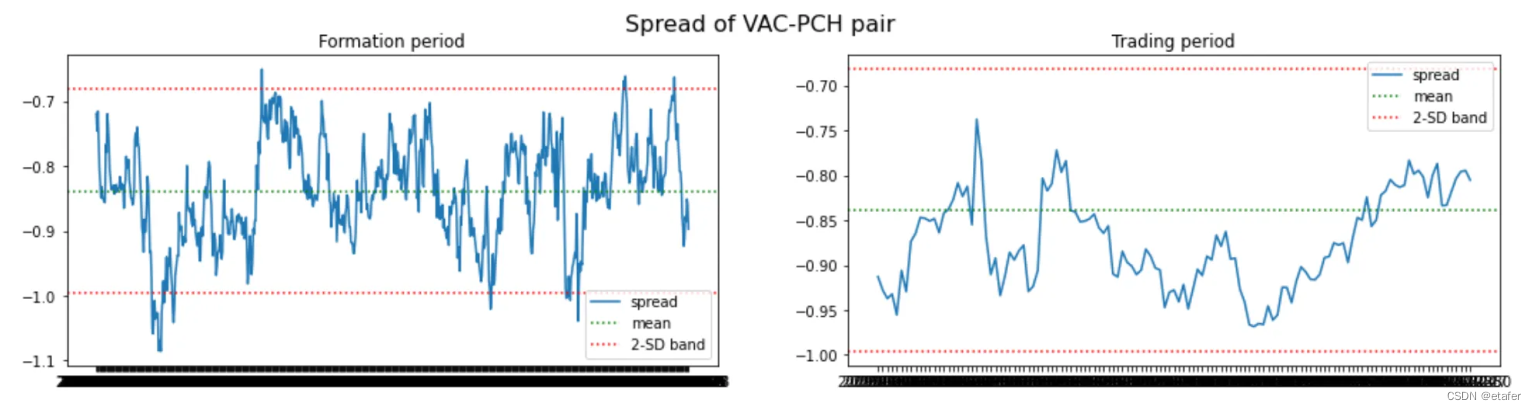
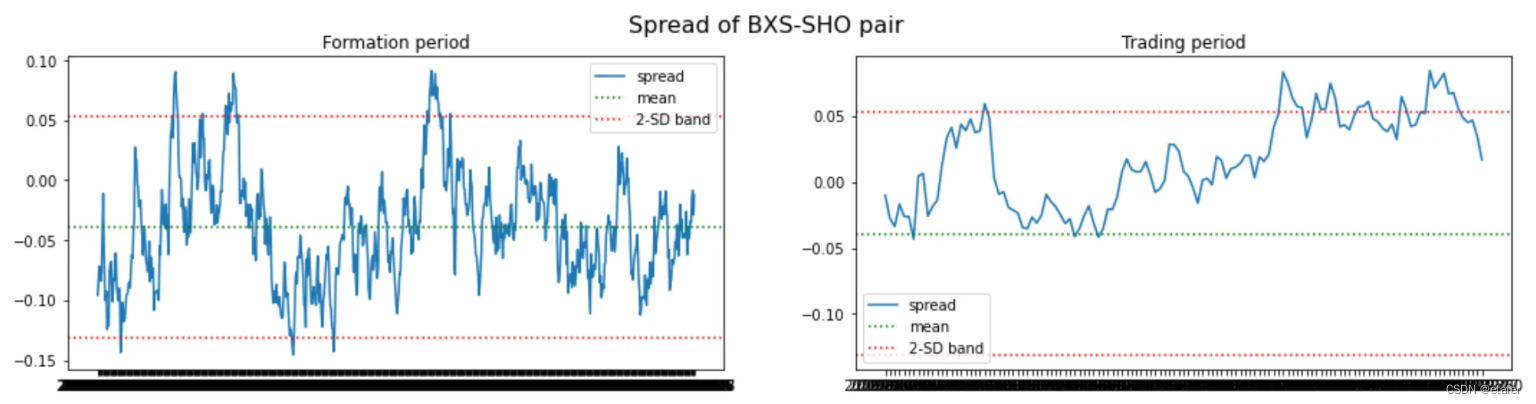
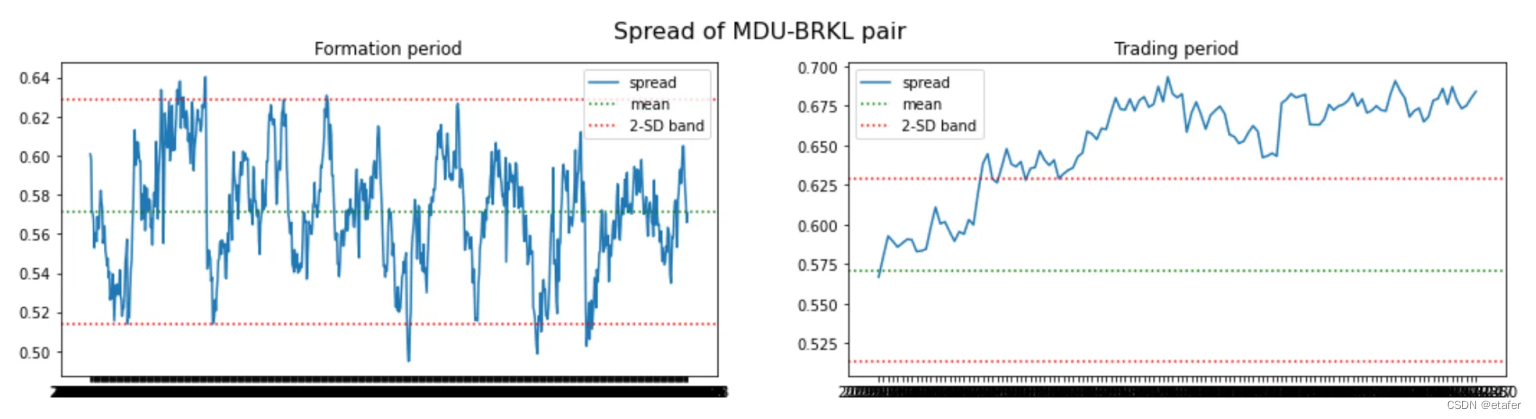
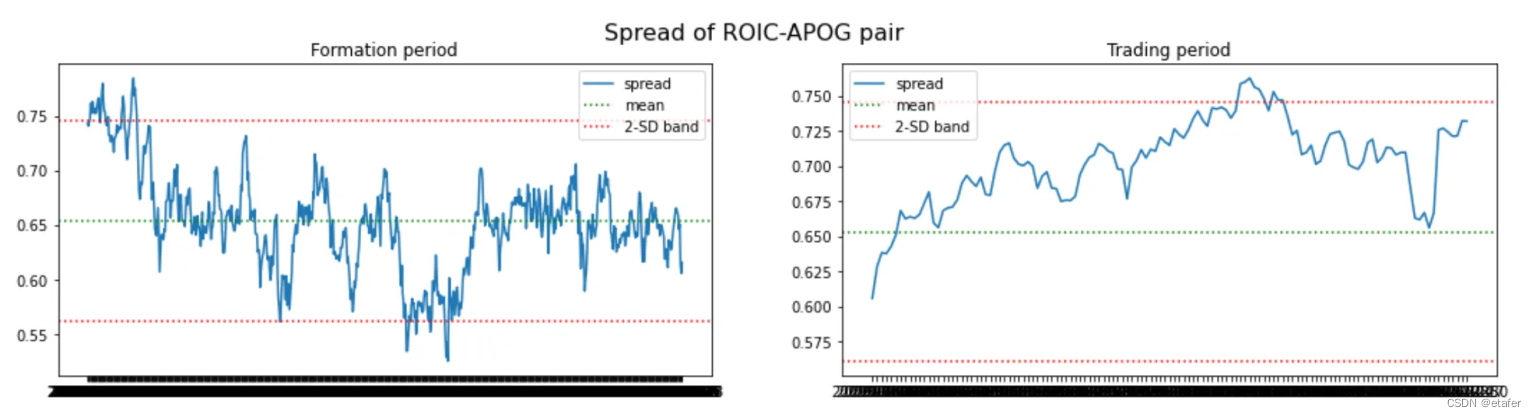
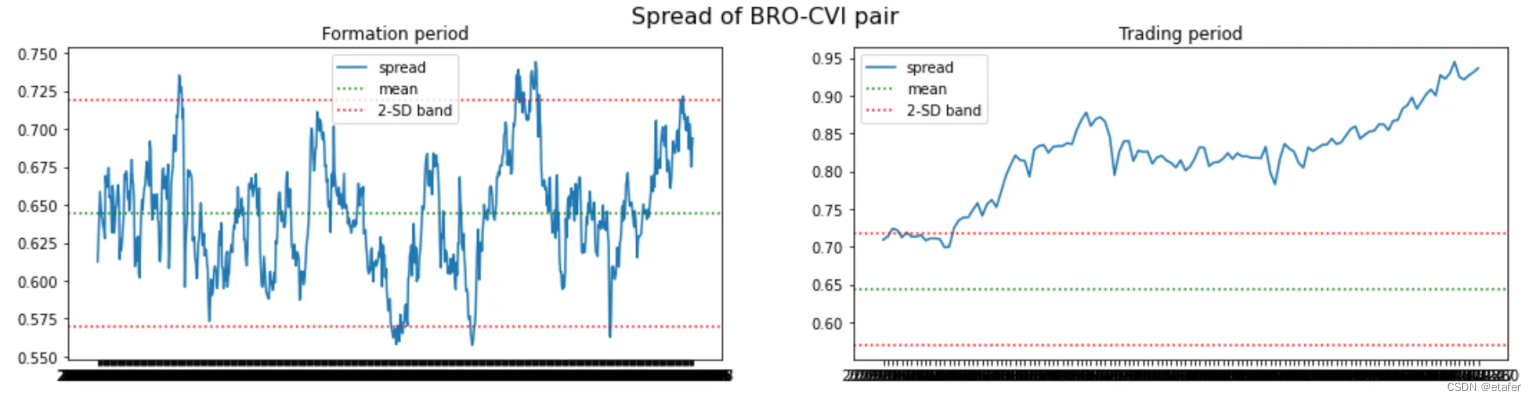
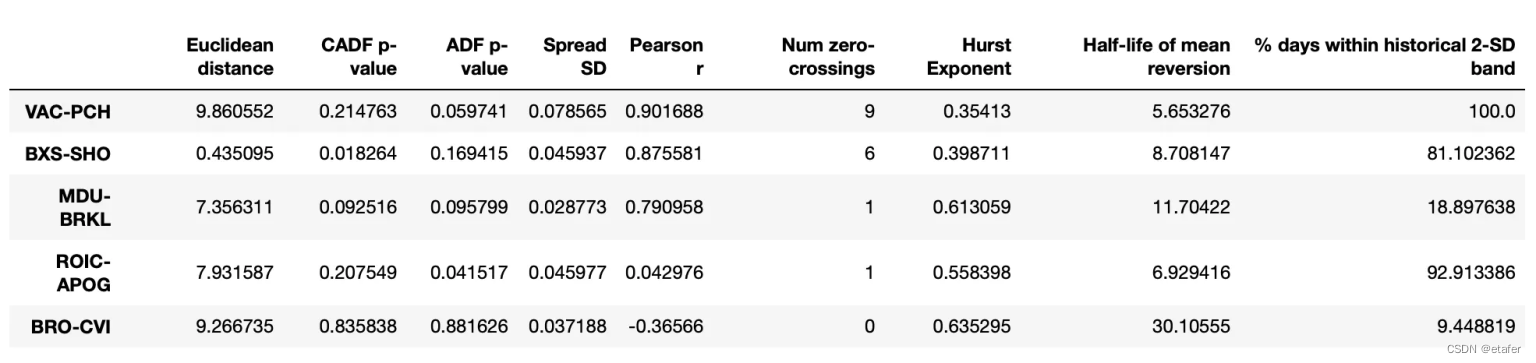
结果与我们在上一个测试中得到的类似。
最后,让我们尝试选择皮尔逊相关系数最高的股票对。
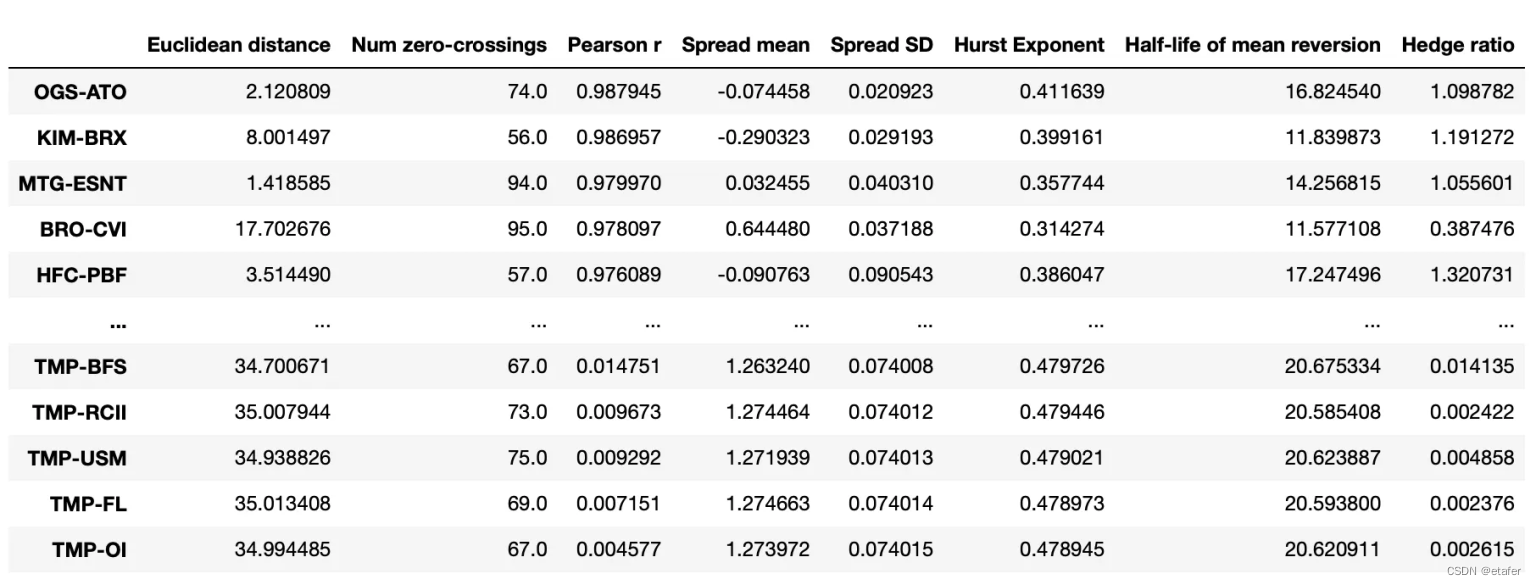
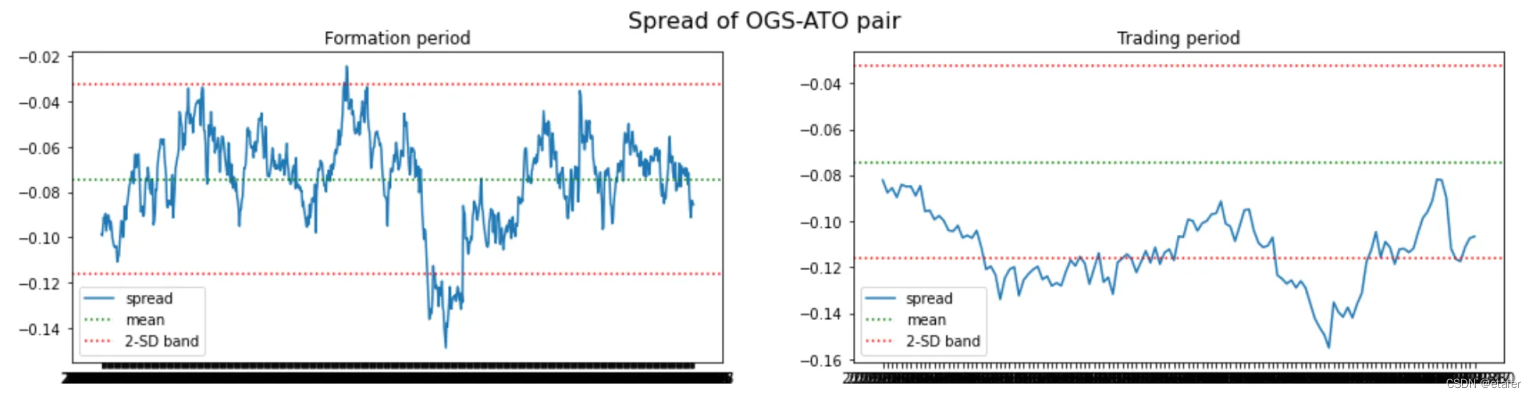
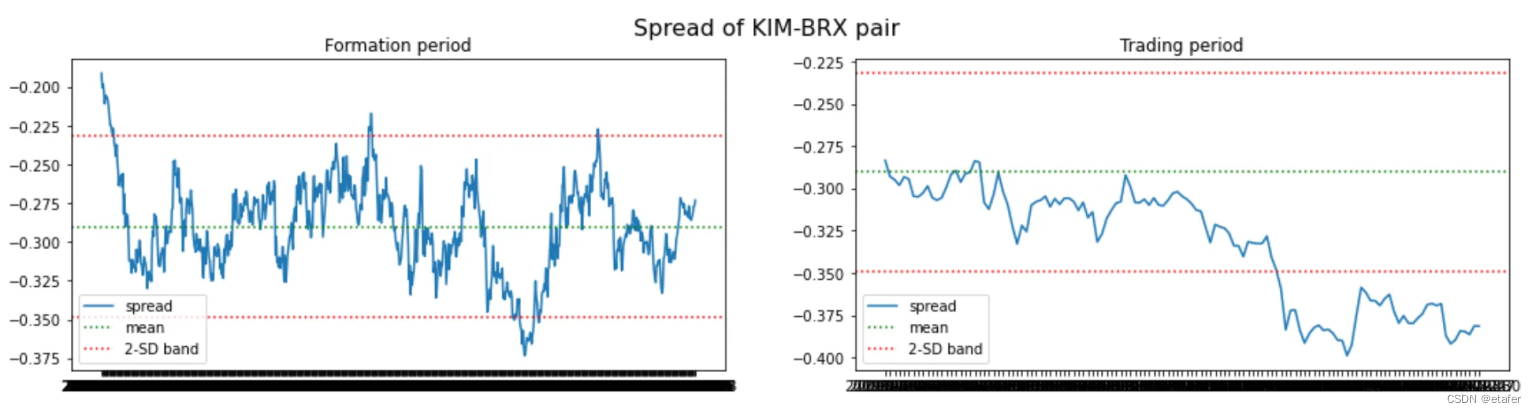
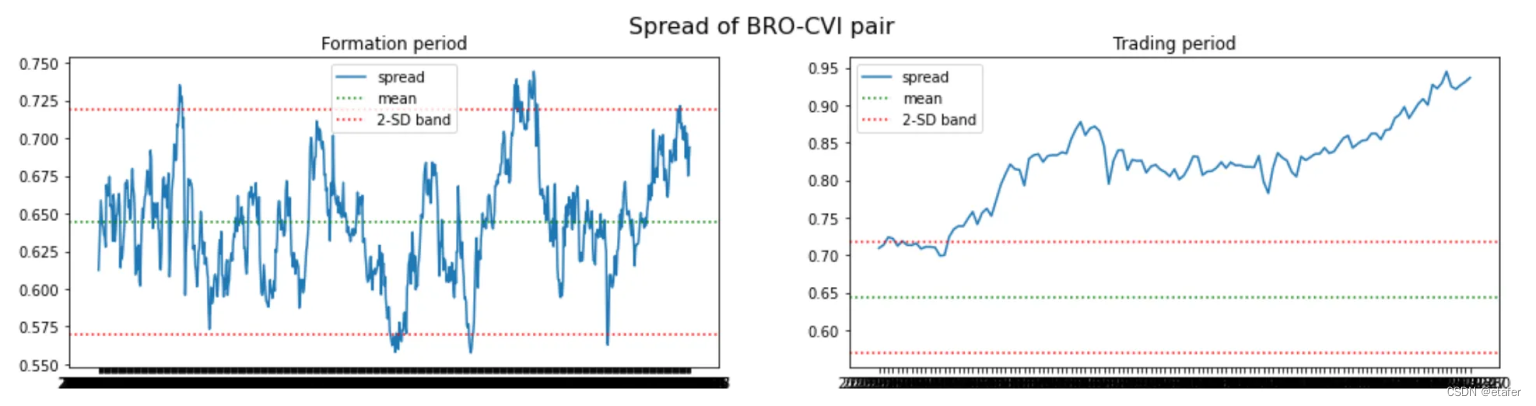
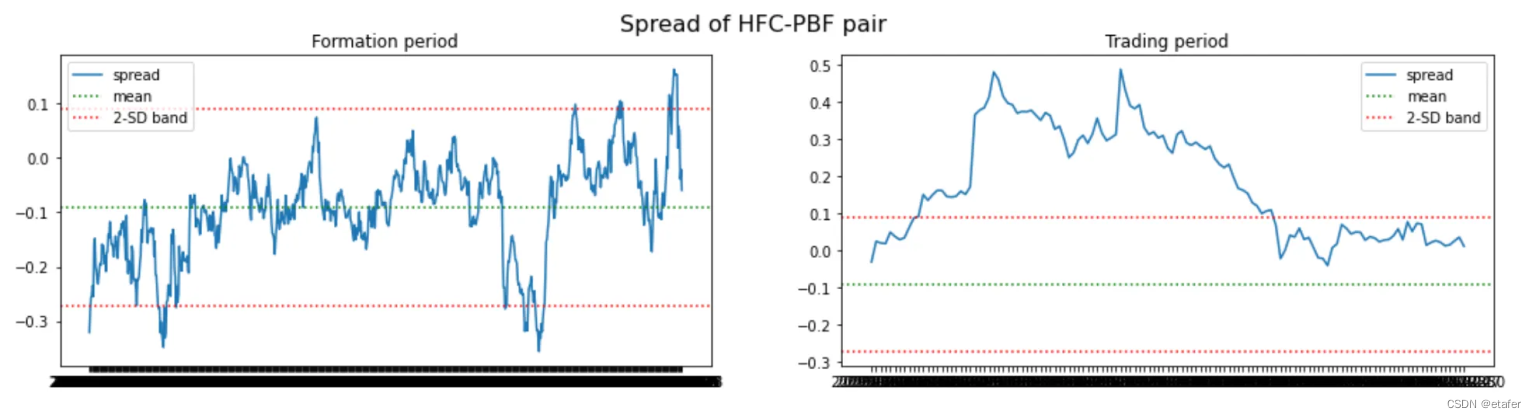
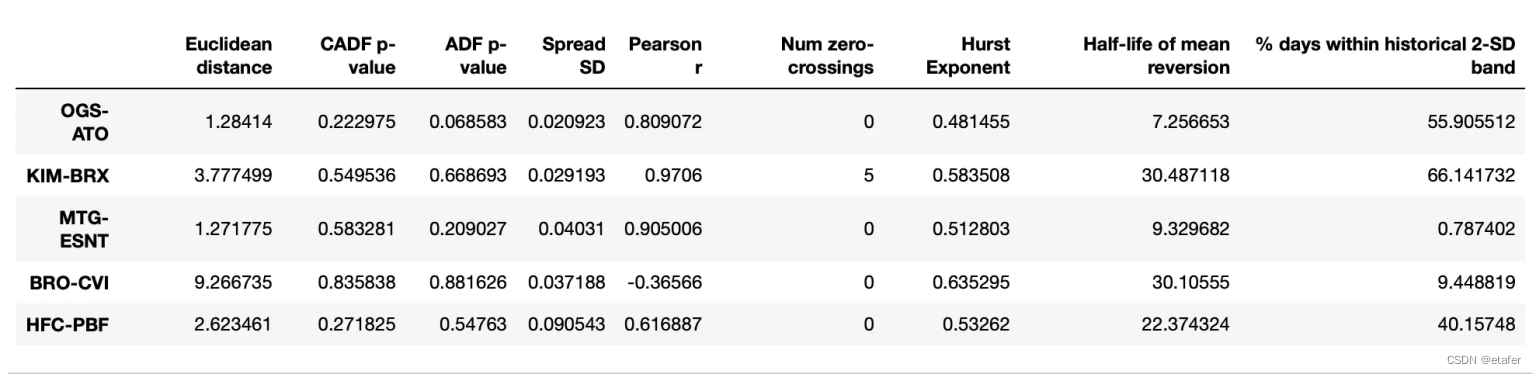
这里没有好的股票对,它们都与历史均值偏离得太远。
结论
到目前为止,我们看到协整方法的主要优点是我们有了更多潜在的股票对。主要问题是,我们用来选择“最佳”交易股票对的技术并没有像我们需要的那样好。在下一篇文章中,我将尝试测试几种机器学习技术,以依据多个指标同时选择股票对。















 6180
6180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









