






[2312.07353] CLIP in Medical Imaging: A Survey
GitHub - zhaozh10/Awesome-CLIP-in-Medical-Imaging: A Survey on CLIP in Medical Imaging
沈定刚老师团队
abstract
Contrastive Language-Image Pre-training(CLIP)对比语言-图像预训练模型,将图像监督引入到视觉模型。CLIP在普适性generalizability和可解释性interpretability有着显著优势。在医学图像领域CLIP优先视作图像文本对齐image-text alignment的预训练范式pre-training paradigm。
1、introduction
视觉模型在out-of-distribution上的性能还是不佳,主要原因是没有和人类认知对齐。相比而言,文本监督形式具有更丰富的语义信息,特别是现在很流行的大语言模型,将文本信息纳入视觉模型也变得有意义。(与人类认知对齐,增加丰富的语义信息)
CLIP的灵感来源于contrastive pre-training,从文本监督text supervision中学习可解释的视觉表示interpretable visual representations。与单一的视觉模型不同,CLIP认为文字说明text caption是对图像的一种语言观点linguistic view,并期望它与图像具有内在的一致性consistent。因此在潜在空间latent space中尽可能接近成对的图像和文本表示。通过这种方式,图像-文本对通过CLIP的视觉和文本编码器进行对齐,从而在视觉编码器中编码了广泛的知识。在图像生成、分割、检测、分类中有广泛的运用。
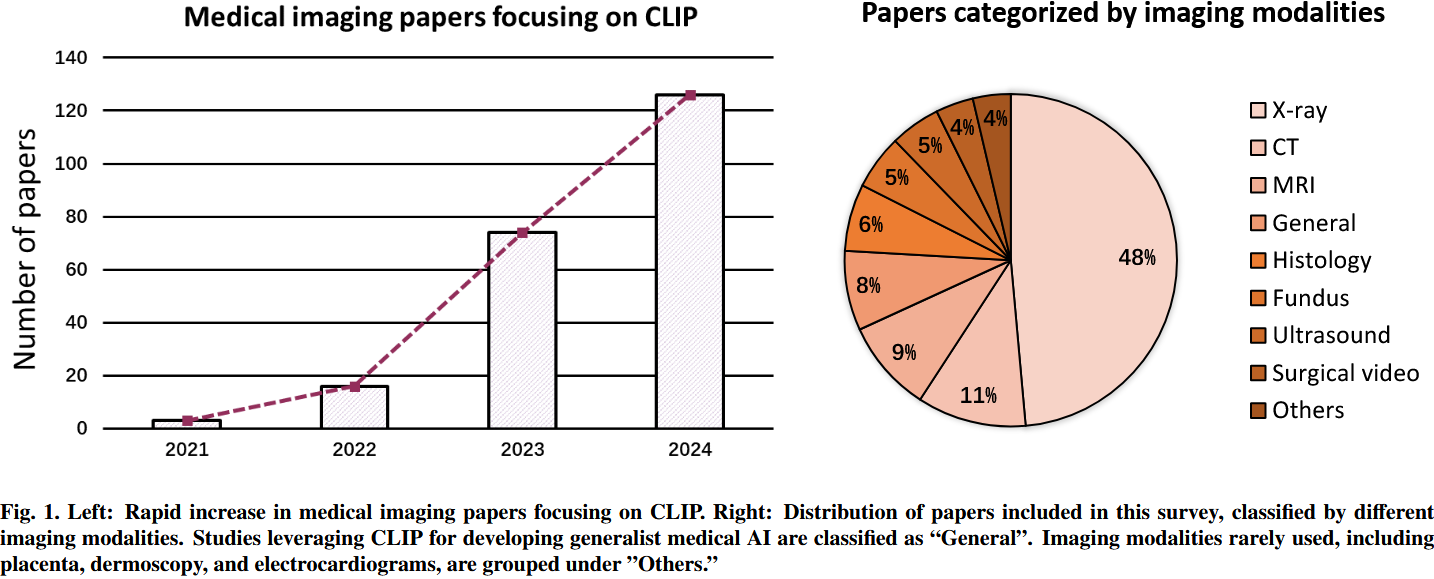
CLIP在医学影像领域运用几倍several-fold的增长,这可以归因于can be attributed to其将神经网络与人类认知congnition相结合align的能力,这满足了人工智能在医疗保健领域healthcare的可解释性interpretability要求 。以前的视觉模型需要大量的标注,比如检测分割,但是如果可以利用文本知识的话,对标注的依赖就大大降低了,CLIP为例提供了更好的思路。
motivation:需要一篇这样的CLIP综述survey
search strategy:一共检索出了224篇论文
- 搜索数据库:Google Scholar, DBLP, ArXiv, and IEEE Xplore
- 搜索关键字:“CLIP”, “image-text alignment”, and “medical imaging”、diffusion models
- 搜索范围:high-impact journal papers, conference/workshop papers, and preprints still under review.
- 过滤条件:非医学影像领域。video clips
- manually reviewed
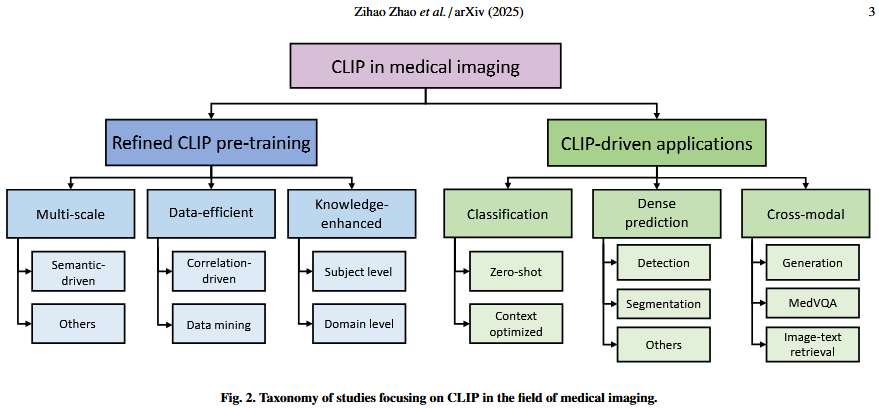
Taxonomy:
- refined CLIP pre-training:关注预训练范式
- CLIP-driven applications:关注于提升临床任务的DL可解释性interpretability和鲁棒性robustness。
Relevant surveys :没人比这篇论文更专注,更细致,以及有更多的讨论。
Contribution:
- 回顾医学影像中的CLIP运用
- 分类taxonomy
- 讨论现有问题,提出未来发展趋势。
Paper organization:
- 第二部分:CLIP的结构
- 第三部分:CLIP医学影像中如何运用。
- 第四部分:CLIP的临床运用。
- 第六部分:存在的问题,对未来的展望
- 第七部分:总结。
2、background
描述一下CLIP的基本结构和变体。分享一些可用的medical image-text pairs的开源数据集。
2.1 contrastive language-image pre-training
CLIP是OpenAI提出来的,目的是弥补image和text之间的差距。CLIP通过连个vison encoder和text encoder,确保image-text pairs在共享的潜在空间中closely aligned。与其他方法相比,不需要大量的人工监督或者复杂度结构,尊存奥卡姆剃刀原则Occam's Razor,倾向于简单有效的结果。
architecture:CLIP无缝结合视觉模型(RestNet、ViT)和语言模型(BERT).
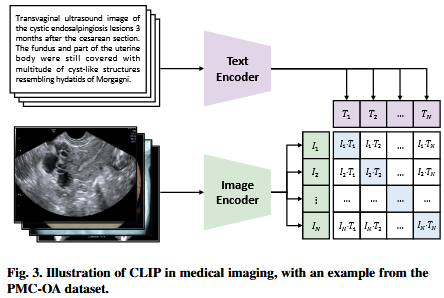
图3中,每次迭代的输入是批量的images+对应的文本描述。 在编码过程之后,embedding被归一化并映射到一个图像-文本联合的潜在空间。图像编码为,文本编码为
,此处的N事batch size,D是embedding dimensionality。
Contrastive pre-training CLIP的学习轨迹围绕成对图像-文本信息之间的对比预训练。在batch size = N的情况下,可以构造个图像-文本对,其中有N个配对matched的图像-文本对(positive pairs,如图3中蓝色突出显示)和(
)个不配对unmatched的图像-文本对(negative pairs)。
图像编码器的预训练目标记为:

其中表示余弦相似度,
是可学习的温度参数,
和
分别表示
图像嵌入image embedding和文本嵌入text embedding。
文本编码器的目标是对称定义is defined symmetrically的:
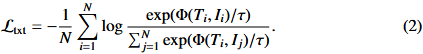
由式(1)和式(2)的平均值计算CLIP的总优化目标:
![]()
零样本能力和泛化性zero-shot capability and generalizability。因为CLIP被预训练为预测图像和文本描述之间的匹配,因此天然的就有zero-shot识别能力。这个过程是通过比较图像嵌入image embeddings和文本嵌入text embedding来完成的,文本嵌入text embeddings对应于指定某些感兴趣类的文本描述textual descriptions。
让表示图像编码器image encoder对给定图像
提取的图像特征image features,
为文本编码器text endcoder生成的类嵌入集合set of class embedding。
因此就是类别数number of class,
每个都是从类似于“[CLASS]的照片”的文本提示text prompt中派生出来的,其中类令牌class tokent被特定的类名替换。
预测概率计算如下:
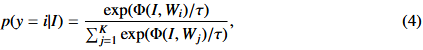
式中,是预训练过程中学习到的温度参数temperature parameter(温度参数就是超参),
表示余弦相似度。与从零scratch开始学习闭集视觉概念closed-set visual concepts的传统分类器学习方法相比,CLIP预训练允许通过文本编码器探索开放集open-set visual concepts视觉概念。这导致了更广泛的语义空间broader semantic space,因此,使学习到的表示更容易转移transferable到下游任务。
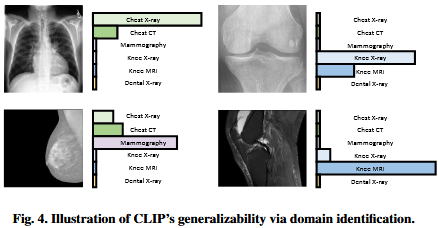
当应用于医学影像等专业领域时,CLIP pre-trained预训练模型的通用性变得明显。尽管最初是在互联网图像internet image及其文本说明textual captions上进行训练,CLIP已经证明了识别recognize和分类categorized医学图像的能力。图4通过域识别说明了CLIP的通用性,其中文本提示text prompt中的类标记被替换为特定的类名称,例如“胸部x射线Chest X-ray”、“乳房x射线Mammography”、“膝关节x射线Knee X-ray”或“牙科x射线Dental X-ray”。它的零样本zero-shot推理能力使其能够识别给定医疗领域,而无需在这些数据集上进行明确的事先训练。虽然需要进一步的研究和验证,但初步研究结果表明the preliminary findings suggest,预训练pre-trained的CLIP的零样本能力zero-shot capability可以减少对大量extensive标记医疗数据集的依赖,并为更有效efficient和可推广generalizable的人工智能驱动的诊断工具铺平道路pave the way。
2.2. Variants of CLIP
遵循CLIP的理念,GLIP (Li et al., 2022b)通过将每个区域region或边界框bounding box与相应的文本短语text phrases对齐aligning,将检测重新表述reformulates为一个基准任务grounding task。它同时simultaneously训练图像编码器image encoder和语言编码器language encoder,以准确预测区域regions和单词words之间的关联associations between。进一步提出融合模块fusion module,增强图像和文本信息之间的对齐alignment,提高模型学习语言感知视觉表示language-aware visual representation的能力。GLIP在目标水平object level上进行了专门的预训练pre-trained,表现出了显著的性能demonstrated remarkable performance,甚至可以与完全监督fully supervised的方法在零样本目标检测zero-shot object detectiob和短语基础任务phrase grounding task 中相媲美comparable。
同时,CLIPSeg (Lu ddecke and Ecker, 2022)和CRIS (Wang et al., 2022c)将CLIP扩展到分割segmentation领域。CLIPSeg固定了预训练的CLIP图像编码器image endcoder和文本编码器text encoder,同时为分割任务引入了可训练的解码器trainable decoder。将编码endcoded后的图像image和文本提示符text prompt融合fused,然后输入到可训练解码器trainable decoder中生成generate预测分割掩码。在概念上一致conceptually aligned,在CRIS中提出了类似的范例。这些具有代表性的变化具有通用性generalizability,进一步显示further showcasing了CLIP的适应性adaptability。
这些变体的潜力在于它们对内容细节的关注attention to content details 。他们可以将视觉visual和文本信息textual information结合起来,对医学图像提供更细致入微nuanced understanding的理解。对于医学影像来说,识别细微的特征subtle features是至关重要的,例如与肿瘤或骨折bone fractures有关的特征。这种技术可以提供显著的好处,潜在地potentially能够在提供提示given the provied prompt的情况下对临床研究进行空间定位spatially locate clinical finding,如“恶性肿块malignant mass ”或“钙化calcification”。
2.3. Medical image-text dataset
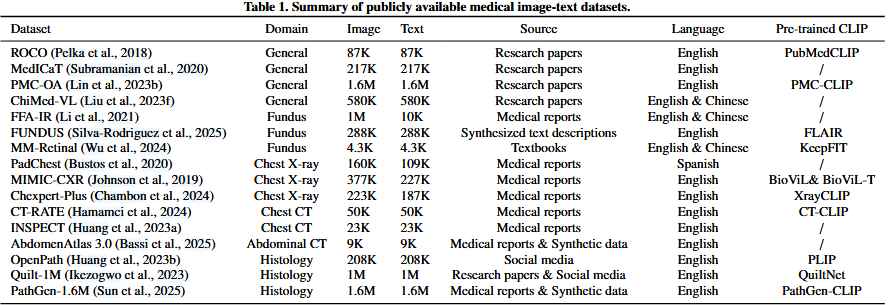
表1是公开的医学图像文本数据集,包含不同的domain、source,以及是否存在一个开源可用的pre-trained CLIP模型。
ROCO (Pelka et al., 2018), MedICaT (Subramanian et al., 2020), PMC-OA (Lin et al., 2023b), and ChiMed-VL (Liu et al., 2023f)是来自研究论文的四个大规模数据集。他们通过PubMed Central从开放获取open-access的研究论文中收集并过滤生物医学图片说明对biomedical figure-caption pairs。医学图像组成,包括x射线,PET, MRI等。
FFA-IR (Li et al., 2021)、PadChest (Bustos et al., 2020)和MIMIC-CXR (Johnson et al., 2019)从日常医疗报告daliy medical reports中收集。在临床实践中,诊断报告往往来自多个图像。因此,图像样本和文本样本的数量表现出明显的差异,特别是在FFAIR数据集的情况下。
OpenPath (Huang et al., 2023b)从社交媒体平台Twitter获取组织学histology图像及其配对说明paired captions。提出的组织学基础模型histology foundation model,PLIP,具有显示了令人印象深刻的表现impressive performance,社交媒体衍生数据social media-derived data的启发性意义illuminating significance。
Quilt-1M (Ikezogwo et al., 2023)从研究论文和YouTube等社交媒体平台中提取图像-文本对。
PathGen-1.6M (Sun et al., 2025)通过利用预训练的图像字幕模型pre-trained image captioning model扩展了图像文本对imaged-text pairs的规模,使其成为截至2025年2月最大的组织学histological图像文本数据集。
Silva-Rodriguez等人(2025)采用了类似的策略,通过从分类标签categorical labels生成文本描述generating text descriptions来制作FUNDUS数据集。
AbdomenAtlas 3.0 (Bassi et al., 2025)作为第一个公开可用的数据集脱颖而出stands out,提供高质量的腹部CT和成对的放射学报告radiology reports。它还提供体素级分割标注。
请注意,并非所有这些数据集都是英文的。PadChest有西班牙文版本,而FFAIR、ChiMed-VL和MM-Retinal有各自的中文版本。不同语言之间的差异在对来自不同语言社区language communities的数据集组合进行预训练时可能会引入语言偏差language bias(Zhou et al., 2021),这最近推动了医学影像学社区跨语言预训练cross-lingual pre-training的研究(Wan et al., 2023)。
3. CLIP in medical image-text pre-training
大多数CLIP模型都是在网络抓取web-crawled数据上训练的(Radford等人,2021;Cherti et al., 2023;Sun et al., 2023),没有过多考虑医学影像和报告的特殊性special characteristics。为了满足专业基础模型specicalized foundational models的需求(Zhang和Metaxas, 2023),已经做出了一些努力several efforts,以使CLIP范式paradigm适应特定的医学成像领域,例如胸部x射线Chest X-ray,脑MRI等。
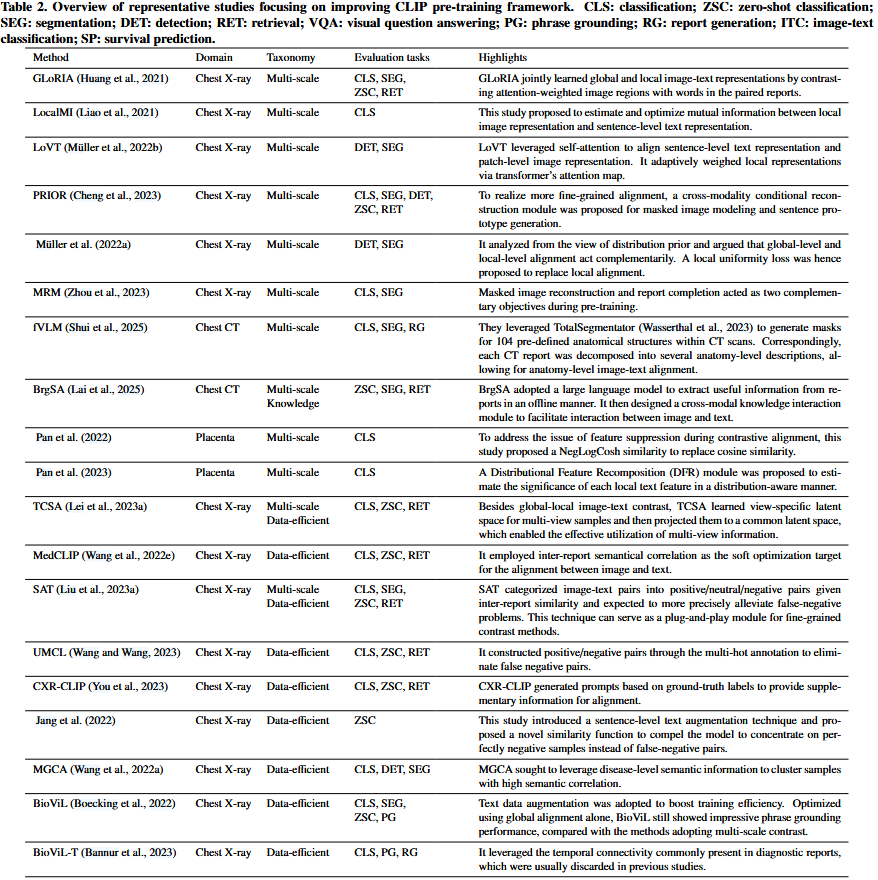
在本节中,描述了医学图像-文本预训练medical image-text pre-training的具体挑战,并提供了现有研究的分类taxonomy,给出了他们的解决方案。本节中包含的代表性方法如表2所示。他们的预训练图像领域,具体的分类,评估任务和值得注意的问题进行了演示。这里的评价任务是指对预训练的视觉模型和文本模型的质量进行评价,通过直接观察它们在目标任务上的性能而无需进行太多修改,这与第4节中提到的CLIP-driven的应用程序不同。
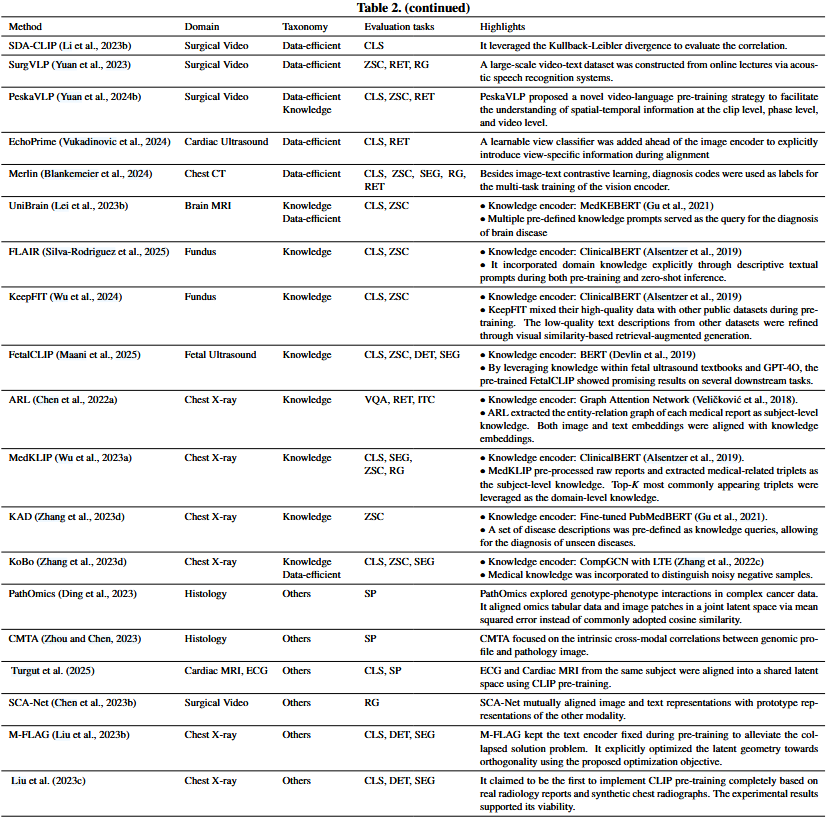
3.1. Challenges of CLIP pre-training
CLIP最初是在自然图像数据集上提出的,由于三个关键挑战,这可能导致医学影像的性能不理想。
- Multi-scale features.医学图像与自然图像的一个主要区别是多尺度特征的重要性significance。除了全局级视觉特征外global-level vision features,局部级视觉特征local-level vision features在医学图像的解释interpretation中也很重要matter(Huang et al., 2021;Lv等人,2023;Chaitanya et al., 2020;Dubey et al., 2015)。例如,一些异常abnormalities或病变lesions,如肺结节lung nodule,在胸片chest radiograph上可能只occupy占很小的比例proportions,但yet它们的关键crucial视觉线索cues可以显著significantly影响诊断diagnostic结果(Austin et al., 1992;Lo et al., 1995;Samei et al., 2003;Li等人,2020)。除了图像信息外,相应的文本信息还具有多尺度文本特征(Morid et al., 2016;Luo et al., 2020;Yang et al., 2021;Tanida et al., 2023)。医学报告往往比自然图像说明captions更复杂(Chen et al., 2020b;Miura et al., 2021)。例如,自然图像说明captions通常是简洁的concise,并提供图像的全局特征概述overview。相反,如图5所示,医学报告由多个句子组成,每个句子描述一个特定区域的图像发现。例如,图5中的第一句话(以绿色高粱显示)描述了肿块的存在presence of a mass,这对准确诊断diagnosis至关重要essential。一般来说,在预训练过程中,除了全局级的图像-文本对比global-level image-text contrast外,还需要考虑局部级的图像特征local-level image features和局部级的文本特征local-level text features,这对基线baseline CLIP预训练中仅在solely at 全局级对齐图像和文本信息的方法提出了挑战。
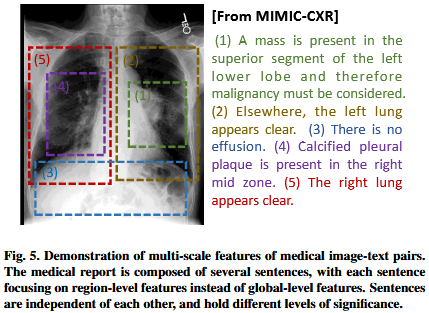
- Data scarcity.与自然图像-文本数据集不同,自然图像-文本数据集很容易达到十亿规模bilion-scale(Schuhmann et al., 2022;翟等,2022;Zhu et al., 2023),成对的图像和报告paired images and reports的医学数据集(Johnson et al., 2019;Ikezogwo et al., 2023)保持相对有限的规模。由于数据集的规模会对根据scaling laws进行的CLIP-style预训练产生重大影响(Cherti et al., 2023),有限的医疗数据会阻碍其在医学影像领域的表现。
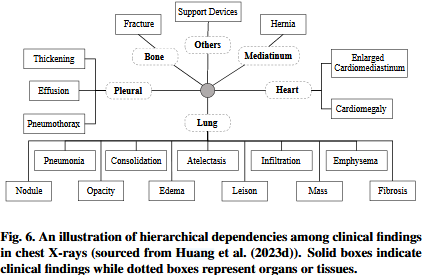
- High demands for specialized knowledge.各种临床概念various clinical concepts之间的层次依赖关系hierarchical dependencies可能是复杂intricate和高度专业化highly specialized的(Zhang et al., 2020;Jain et al., 2021)。如图6所示depicted,该图是基于胸部x光片chest X-rays的专家观点构建的constructed,考虑了临床表现clinical finding的相关性、特征characteristics和发生位置occurence loations(Huang et al., 2023)。当面对来自移位分布shifted distribution的数据时,缺乏对医学概念的深入理解可能会导致性能下降degraded performance,甚至是捷径解决方案shortcut solutions(Geirhos等人,2020)。因此,为了提高可靠性reliability和鲁棒性roubustness,在预训练过程中明确地加入知识explicitly incorporating knowledge可能是一种可行的解决方案viable solution。
这些挑战突出了在医学图像-文本数据集上直接应用CLIP预训练的不可行性,激励了相关工作来改进医学成像领域的CLIP式预训练。
3.2. Multi-scale contrast
尽管一些早期研究(Zhang et al., 2022b;Zhou等人,2022a)试图将CLIP预训练扩展到医学成像领域,但他们仍然遵循Radford等人(2021)提出的全局级对比global-level contrast,因此在语义分割和目标检测等任务上表现不佳。为了解决这个问题,一些研究尝试在预训练中进行多尺度对比multi-scale contrast。
Semantic-driven contrast。Huang等人(2021)通过引入语义驱动的多尺度对比概念concept of semantic-driven multi-scale contrast,在这一领域做出了开创性的贡献pioneering contribution。所提出的GLoRIA遵循与CLIP类似的范例paradigm来实现全局级对比global-level contrast,但它通过在每个单词表示word representation及其语义相似的视觉对应物之间semantically similar visual counterparts实现局部级对比local-level contrast来区分自己distinguished itself。如图7(a)所示,GLoRIA将每个单词word和每个图像image子区域sub-region分别定义为局部文本和图像特征。为了执行局部级别的对比local-level contrast,它计算单词文本特征word-wise text features和子区域图像特征sub-region-wise image features之间的语义相似度semantic similarity。在获得语义相似度后semantic similarity,GLoRIA利用它对所有局部图像特征local image features进行加权求和weighted summation,从而为每个单词表示word representation得到一个加权注意力的局部图像表示attention-weighted local image representation,其中他们论文中使用的“attention”表示语义相似度semantic。单词表示word representation和加权图像表示weighted image representation是语义相似semantically similar,因此通过局部对比损失localized contrastive loss在潜在空间latent space中被拉得更近pulled closer。由于局部级对比local-level contrast是在单词级word level进行的,因此GLoRIA会将所有局部级对比损失累加起来accumulate all localized contrastive loss,作为医疗报告medical report的总局部级对比目标total local-level contrast objective。图7(b)显示了GLoRIA学习的语义亲和力semantic affinity的有效性。文本到图像的语义关联semantic affinity,可视化为热图heatmap,能够正确识别给定单词given word的相关图像子区域sub-regions。例如,基于“肺炎Pneumonia”一词的语义亲和力semantic affinity正确定位了右下叶right lower lob含有异质实变混浊的区域heterogenous consolidative opacities,此外,与“气胸Pneumothorax”相关的注意权重准确地强调emphasize右肺尖right lung apex的透明度lucency,表明气胸pneumothorax。类似的analogous结果也可以在“水肿edema”和“不透明opacity”中观察到,突出了局部级对齐local-level aligment的有效性。
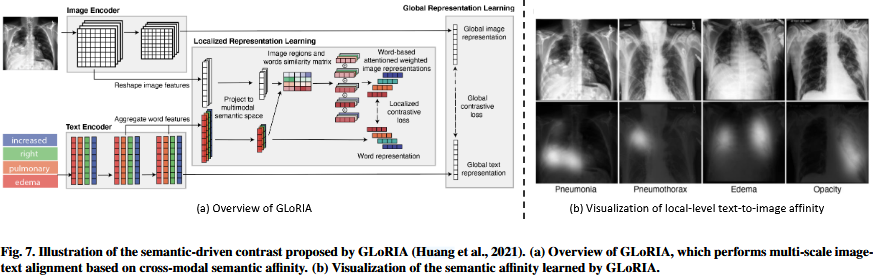
Huang等人(2021)提出的语义驱动的多尺度对比方法semantic-driven multi-scale contrast直观intuitive,但仍然存在一些明显的弱点apparent weaknesses。(1)局部对比度设计不对称the local-level contrast is designed asymmetrically。它的对比目标contrastive objective是在文本和注意加权子区域特征text and attention-weighted sub-region feature之间进行优化。这只保证guarantees 从文本到图像的对齐alignment,忽略dismissing从图像到文本的对齐。(2)虽然while通过对局部图像特征的加权求和weighted summation of local image features来计算文本到图像的局部特征是直观的intuitive,但它可能难以struggle捕捉图像和文本特征之间的隐含语义相关性implicit semantic correlations。(3)总的局部目标简单地累积accumulates了所有的局部对比损失localized contrastive losses,意味implying着每个局部文本特征被平等地对待be treated equally。然而,如图5所示,医学报告中的不同句子对诊断diagnosis的重要性不同。
基于上述局限性motivated by the above-mentioned limitations,Müller等人(2022b)提出了一种改进的语义驱动对比方法improved semantic-driven contrastive method, LoVT,该方法涵盖了文本到图像的局部对齐text-to-image local alignment 和图像到文本的局部对齐image-to-text local alignment。它仍然将图像子区域特征image sub-region feature作为局部图像特征local image features,但将医学报告medical reports划分divides为句子sentences而不是单词words。为了更好地捕获隐含语义特征implicit semantic features,文本到图像的局部特征text-to-image local features和图像到文本的局部特征image-to-text local features都是通过变换层transformer layers来学习的,而不instead of是加权求和weighted summation。此外,通过变压器的注意力图transformer's attention map自适应adaprively地为每个词的局部对比损失localized contrasive loss分配is assigned 权重(Dosovitskiy et al., 2020)。Cheng等人(2023)将LoVT扩展为图像和文本表示合并incorporating的条件重建conditional reconstruction任务。该扩展促进了facilitates跨模式功能的交互,并学习了更细粒度的规模对齐more finegrained scale alignment。此外additionally,他们提出了一个用于句子级嵌入sentence-level embeddings的原型记忆库pototype memory bank ,期望在图像-文本联合空间joint image-text space中学习高级文本特征high-level text features。在一项平行研究parallel study(Zhang等人,2023b)中,也采用employed了类似的方法。然而,它的重点是focuses on重建reconstructing原始文本报告,而不是instead of使用原型存储库prototype memory bank。
除了这条研究路线之外besides this line of research,还有许多其他的研究关注多尺度的对比multi-scale contrast。Liao等(2021)优化了局部图像特征local image features和句子级文本表示sentence-level text representation之间的估计互信息mutual information来实现局部特征对齐local feature alignment。Seibold et al.(2022)假设assume每个句子sentence可以传达convery不同的诊断信息distinct information for diagnosis,并提出proposed进行图像-句子对齐perform image-sentence alignment。Palepu和Beam(2023)提出将文本标记text-token的熵惩罚penalize the entropy为图像补丁相似分数image-patch similarity scores。
Multi-scale contrast in volumetric imaging.虽然上述aforementioned研究主要集中在predominatly focus on胸部x线,但最近的研究也对容积成像模式volumetric iamging modalities进行了研究investigated。CT等方法以其详细的解剖结构anatomical structures和大量的冗余信息substantial redunant information为特征characterized。因此Consequently,最近的研究(Ketabi等人,2024;林等,2024;Shui等,2025;Lai等人,2025)倾向于tend to 利用utilize语义驱动的多尺度对比semantic-driven multi-scale contrast。这种方法approach优于第3.3节和第3.4节中讨论的方法methodologies。具体而言specifically,由Shui等人(2025)提出的fVLM模型使用TotalSegmentator (Wasserthal等人,2023)识别不同的解剖结构identifying distinct anatomical structures,从而进行performs 解剖学层面的图像-文本对齐anatomy-level image-text alignment。这突出了从专门模型中提取、分割或检测能力的潜力。
3.3. Data-efficient contrast
由于伦理问题ethical concerns ,具有配对报告paired reports的大规模医学影像数据集难以获得,这对CLIP预训练的有效性产生了不利影响adversely influences(Zhai et al., 2022;Cherti等人,2023年)。为了应对tackle这一挑战,各种研究试图endeavored以更有效的方式实现对比图像-文本的预训练contrastive image-text pre-training,大致分broadly falls 为两类,即相关驱动对比correlation-driven contrast和数据挖掘data mining。
Correlation-driven contrast.一些研究设法manage to 提高了boost基于语义关联的对比预训练的效率efficiency of contrastive pre-training based on semantic correlation。医疗报告和图像说明image captions的一个显著区别在于lies in,医疗报告是为了明确的诊断目的clear diagnostic而编写的。由于一小部分proportion疾病或发现通常涵盖大多数病例(Bustos等人,2020;Zhang和Metaxas, 2023),医学报告之间的语义重叠semantic overlap可能是显著的,特别是对于正常病例,如图8所示。因此,简单地对待不配对的图像和报告作为负对会导致假负false-negative问题,降低degrade预训练的效果efficacy。基于这一观察结果,Wang等人(2022e)遵循NegBio的实践,为训练集中的所有医疗报告构建了一个相关矩阵correlation matrix(Peng等人,2018)。然后使用预先计算的相关性pre-computed correlation作为软优化目标soft optimization,而不是instead of 原始的单热优化目标one-hot optmization target,用于图像-文本对齐image-text alignment,从而有效地利用未配对的假阴性报告。在没有not avaliable医疗报告的情况下,Wang and Wang(2023)通过测量不同样本的真值标签之间的相关性correlation,构建了多热优化目标multi-hot optimization targets进行对比预训练contrastive pre-training。在最近的一项研究中,Liu等人(2023a)基于报告间相关性进一步将所有图像文本对分为categorized正对positive、负对negative和中性对neutral pairs。这种改进的样本对分类categorization允许更精确地挖掘precise mining假阴性对false-negative pairs。MGCA (Wang et al., 2022a)侧重于疾病级别的样本间相关性,这是一种比图像级别语义image-level semantic更高的抽象级别。它设计了一种新的跨模式疾病水平比对框架a novel cross-modal disease-level alignment framework ,以服务具有相同疾病的样本。语义关联也可以扩展到成像模态层面。对于多模态脑MRI和相应的模态报告modality-wise reports,,UniBrain (Lei等人,2023b)对齐模态图像-文本特征modality-wise image-text features,然后将这些特征连接concatenates在一起,以实现主体图像-文本对齐realize subject-wise image-text alignment。
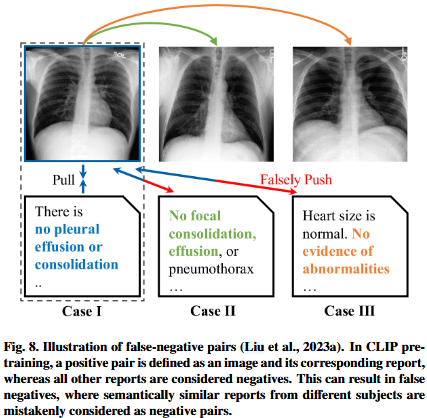
Data mining. 同时Simultaneously,许多其他研究试图通过挖掘补充信息sunpplementary information来提高boost训练效率。在诊断报告diagnostic report中,调查结果部分Findings section提供了临床观察的详细描述,而印象部分Impression section通常概括了encapsulates这些调查结果findings并提供了总体评估overall assessment (Wallis和McCoubrie, 2011;Ganeshan et al., 2018)。虽然以前的研究主要集中在从原始诊断报告中提取调查结果部分Findings section,通常忽略了overlooking印象部分Impression section,但Boecking等人(2022)将后一部分纳入incorporate其中,以丰富图像-文本对齐可用的信息。此外,由于句子之间的依赖性较弱weak(见图5),他们还建议在每个部分中随机打乱randomly shuffle句子。CXR-CLIP (You et al., 2023)探索并利用了不确定性标注utilized uncertainty annotations(Irvin et al., 2019)。它根据不确定标注uncertainty annotations生成提示generates prompts,为图像-文本对齐提供补充信息upplementary information for image-text alignment。
Data-efficient contrast in video-based imaging.在本综述review中,确定了identified一系列a line of专门针对基于视频的成像方式的研究,如内窥镜检查endoscopy(Li等人,2023b)、腹腔镜检查laparoscopy(Yuan等人,2023,2024a,b)和超声检查ultrasound(Christensen等人,2024;Vukadinovic et al., 2024)。鉴于它们共同的临床背景Given their shared clinical context,在这里将手术视频下的under the umbrella of surgical video内窥镜endoscopy和腹腔镜laparoscopy分类calssify。手术视频surgical video 和超声视频ultrasound video都包含丰富的时空信息spatio-temporal information,将它们与其他模式区分开来distinguishing,并强烈强调motivating a strong emphasis on数据高效的对比策略contrast strategies。Yuan等人(2023)通过利用by leverageing在线讲座和声学语音识别oline lectures and acoustic speed recognition,率先pioneers 开发了该领域的第一个大规模视频文本数据集large-scale video-text dataset。他们随后subsequent的研究(Yuan et al., 2024a,b)利用手术视频的顺序特性the sequential nature of surgical video,改进了refine图像-文本对齐方法。值得注意的是notably,PeskaVLP (Yuan等,2024b)通过集成integrating大型语言模型large language models来增强文本监督,并分层地hierarchically将文本与视频剪辑video clips、过程阶段procedural phases和整个视频entire videos对齐,取得了重大进展。
3.4. Explicit knowledge enhancement
虽然3.2节和3.3节的研究本质上nature仍然关注数据集的内部信息internal information,但一些研究人员已经研究了intergration外部医学知识的整合,以增强预训练过程。
现有研究采用employing统一医学语言系统(unified medical language system, UMLS)作为医学概念medical concepts的外部知识库external knowledge bses(Bodenreider, 2004),通常typically在主体层面subject level和领域层面domain level都有知识增强,如图9所示。在主体层面subject level,通常采用命名实体识别工具ScispaCy(a named entity recognition tool) (Neumann et al., 2019)从每个报告中提取医学实体medical entities,并将其链接到UMLS中相应的医学概念medical concepts,以消除实体歧义entity disambiguation。然后,基于UMLS或RadGraph (Jain et al., 2021)中定义的关系构建实体关系图entity-relation graph,其中前者former为一般医学概念general medical concepts建立关系established relations,后者为胸部x射线的实践practice量身定制tailores。这些关系,包括因果关系causal、位置关系positional和修改modifying关系,可以提供图像的视觉结构image's visual structures和人类推理过程the process of human的说明reasoning,增强每个图像-文本对之间的一致性。对于领域级增强domain-level,知识通常表示为特定领域的知识图domain-specific knowledge graph或针对目标医学成像领域targeted medical imaging domain(例如,胸部x射线和脑MRI)的描述性知识提示,涵盖covering相关器官、组织或临床发现。特定领域的知识图domain-specific knowledge graph 既可以定义为可训练的符号图a trainable symbolic graph,也可以定义为top-K最常见实体三元组的集合entity triplets(Wu et al., 2023a)。描述性知识提示descirptive knowledge prompt通常提供对所包含实体encompassed entities的详细观察或解释。
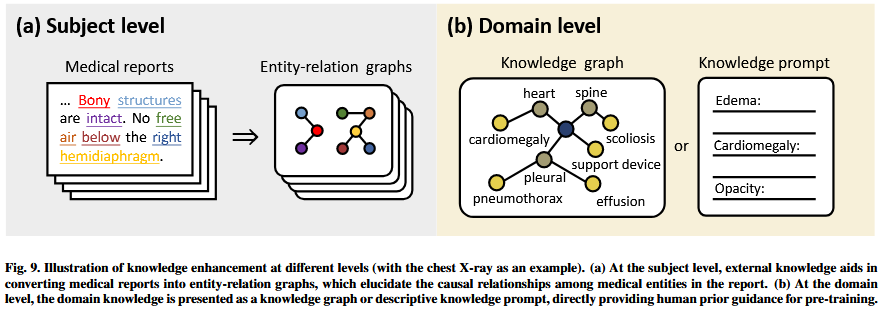
为了将外部知识纳入incorporate预训练阶段pre-training,通常需要使用involvee辅助知识编码器auxiliary knowledge encoder。它的作用是serves to将知识信息转化为可被神经网络解释interpreted的知识嵌入knowledge embeddings。知识编码器的选择可能涉及involve到图神经网络graph neural network的选择(Chen et al., 2022a;Zhang et al., 2023d)或预训练BERT模型(Lin et al., 2023a)。
ARL (Chen et al., 2022a)是主体层面subject -level知识增强的代表性研究。具体来说specifically,它采用TransE (Bordes et al., 2013)算法训练图关注网络graph attention(Velic kovic et al., 2018)作为知识编码器knowledge encoder。训练集中的所有医疗报告都经过预处理pre-processed,以根据UMLS中定义的关系构建特定主题的实体关系图subject-specific entity-relation graphs(Bodenreider, 2004)。相比之下in contrast,KoBo (Zhang et al., 2023d)和FLAIR (Wang et al., 2023c)优先prioritize考虑领域级增强domain-level enhancement。KoBo从UMLS中提取包含放射医学概念radiological medical concepts的知识图谱knowledge graph,并利用CompGCN (Zhang et al., 2022c)作为知识编码器knowledge encoder。提出了知识语义增强模块a knowledge semantic enhancement module和知识语义引导模块a knowledge semantic guidance module,分别用于抑制mitigate负样本噪声negative sample noise和调adjust节语义漂移semantic shifting。同样similarly,FLAIR利用leverages ClinicalBERT (Alsentzer等人,2019)来解释interpret眼底成像领域the domain of fundus images的人类精炼知识描述human-refined knowledge descriptions,包括视觉特征visual feaures和概念inter-concept间关系的详细描述。
除了上述研究外in addition to the studies mentioned above,还有同时采用主体级subject-level 和领域级domain-level知识增强的研究。MedKLIP (Wu et al., 2023a)从每个原始文本报告raw text report中预处理并提取实体三元组entity triplets,构成学科级知识constituing subject-level knowledge。然后,识别出在实际实现中出现occurring频率frequently top-K个实体,即K=75,形成实体查询集entity qurey set,作为领域级知识图domain-level knowledge graph。ClinicalBERT (Alsentzer et al., 2019)同时simultaneously用于主体级subject-level和领域级domain-level知识增强knowledge graph。KAD也采用了这种范式paradigm(Zhang et al., 2023),显示了revealing其稳健性。MOTOR (Lin et al., 2023a)采用关于关键临床发现的符号图symbolic graph作为regrading领域级知识,并提取实体关系图用于学科级增强。采用预训练的SciBERT (Beltagy et al., 2019)作为MOTOR的知识编码器。性能的提高说明了在CLIP-style预训练中显性explicit知识增强的合理性。
3.5. Others
虽然现有的方法通常可以根据前面概述的分类taxonomy法进行分类categorized,但仍然存在例外。这些例外可能为潜在的研究提供见解insight。M-FLAG (Liu et al., 2023b)关注的是崩溃解cokkapse solution问题(Grill et al., 2020;Chen and He, 2021),这意味着图像和文本信息被错误地编码为恒定的特征嵌入,以确保潜在空间latent space中接近零的距离near-zero distance。为了解决这个问题,他们建议在预训练期间保持文本编码器冻结frozen,并采用正交性损失orthogonality loss来鼓励视觉表征的正交性orthogonality of visual representations。Liu等人(2023c)报道首次尝试基于合成synthetic胸部x光片和配对真实放射学报告实现CLIP预训练。他们的实验结果揭示reveal了特定领域生成模型domain-specific generative models在医学成像领域的潜在价值(Chambon et al., 2022)。CMTA (Zhou and Chen, 2023)和PathOmics (Ding et al., 2023)研究investigate组学表格数据omics tabular data和病理图像pathologt images之间的对齐,这可能会激发potentially inspire对其他形式other forms of 的数据与诊断报告diagnostic reports以外的图像进行对齐的探索exploration。值得注意is worth noting的是,Turgut等人(2025)引入了一种创新方法innovative approach,通过应用clip式预训练来校准两种不同的成像模式:心电图electrocar-diograms 和心脏 cardiac MRI。虽然心电图electrocardiograms价格低廉low-price,但诊断能力diagnostic capabilities有限limited。虽然心脏核磁共振成像cardiac MRIs可以提供更明确的definitive诊断信息diagnostic capabilities,但它们要贵得多。该方法成功地发挥了unlocks心电图electrocardiograms诊断diagnostic心血管疾病cardiovascular diseases的潜力,为患者提供了一种低成本、有效的选择。我们相信最近的这项工作可以提供有价值的见解insights,并使更广泛的研究界research community受益。
3.6. Summary
在本节中,我们提供了适应医学成像CLIP预训练的概述overview,分taxonmized为三类categories。尽管despite它们是分类categorization的,但这些方法本质inherently上是相同的——它们都试图探索explore和利用utilize成对图像和文本之间固有的一致性关系inherently consistency relationships。多尺度对比方法muilti-scale contrast approach侧重于局部图像特征和文本特征之间的一致性consistency,从而实现更详细的解释interpretation。同时simultaneously,数据高效对比方法data-efficient contrast approach强调emphasizes数据的有效使用,通过利用leveraging样本间inter-sample相关性来保持maintaining不同样本之间的一致性consistency。最后,知识增强方法利用专家级知识expert-level knowledge明确explicitly解释interpret医学实体medical entities之间的内在关系inherent relationships,超越going beyond基本的图像文本匹配,以确保学习的图像和文本表示符合医学专家medical experts细微nuanced而复杂complex的知识。每一种方法都为医学成像领域做出了独特的贡献,展示showcasing了CLIP预训练的适应性adaptability和潜力potential,不仅not only可以增强传统的图像-文本关系,还可以为医学图像分析带来新的深度和精度。
4. CLIP-driven applications
利用leverageing大规模的文本监督,预训练的CLIP模型有效地将视觉特征与人类语言对齐,这种能力可以扩展到医学图像(参见图4)。这种能力在可解释性interpretability很重要的临床环境中尤为重要particularly significant(Lauritsen等人,2020;Tjoa and Guan, 2020)。同时,CLIP中嵌入的丰富的人类知识也可以作为需要标注annotation-demanding的任务的外部监督,例如肿瘤分割(Liu et al., 2023g)。CLIP的这些优势解释了在各种临床应用中越来越多地采用CLIP。
4.1. Classification
CLIP的预训练涉及involves图像-文本对齐,使其自然适合医学图像分类(Xian et al., 2016;Radford et al., 2021)。该任务通常需要对图像进行全局评估global assessment(例如,确定图像是良性benign还是恶性malignant,或识别identifying特定疾病)。在表3中,我们列出了present利用employ CLIP进行图像分类的现有研究,一般可以分为两种方法:零样本分类zero-shot classification和上下文优化context optimization。零样本分类zero-shot classification侧重于通过提示工程prompt engineering利用leveraging特定领域CLIP模型的诊断潜力。另一方面,上下文优化context optimization旨在以参数和数据都有效both parameter- and data-efficient的方式manner将非特定领域non-domain-specific的CLIP模型微调fine-tune到医疗领域。
4.1.1. Zero-shot classification
该研究渠道avenue试图充分利用fully leverage预训练CLIP模型的潜力,而无需对下游数据集进行微调。因此,诊断diagnostic性能在很大程度上取决于内置知识built-in knowledge,这影响了特定领域CLIP的选择。在现有existing研究中,通常通过对目标医学成像域上的原始CLIP进行微调fine-tuning来获得特定域的CLIP (Tiu et al., 2022;Seibold et al., 2022;Mishra et al., 2023;Kumar等人,2022)或采用开源专用CLIP模型(Boecking等人,2022;Pham et al., 2024)。对于像心电图(electro-cardiogram, ECG)这样的特殊情况unique cases(Liu et al., 2024a),数据以一维多通道信号的形式存在,研究人员经常从头scratch开始训练ECG-specific的CLIP模型。
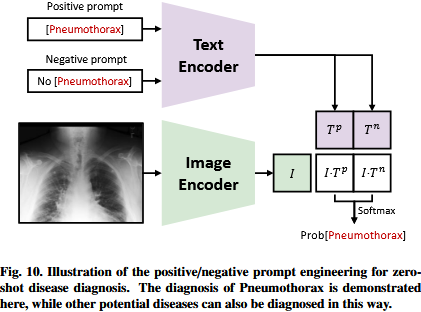
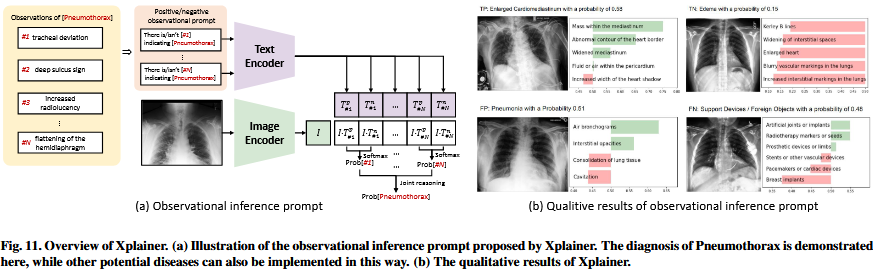
除了besides预训练CLIP的选择,零样本分类zero-shot calssification的另一个关键点在于lies in提示工程prompt engineering(Wei et al., 2022;Wang et al., 2023a;Gu et al., 2023)。虽然第2.1节中描述的标准零样本提示standard zero-shot prompt对于BI-RADS评分grading(Liberman and Menell, 2002)或OA评估assessment(Kellgren and Lawrence, 1957)等任务是有效的,但它在疾病诊断disease diagnosis方面存在不足falls short in(Tiu et al., 2022)。这种不足shortfall归因于attributed to 概率计算probability calculations中的softmax操作(参见Eq. 4),它将每个类视为treat互斥的mutually exclusive。这与疾病诊断disease diagnosis的现实不符not align with,因为患者可能同时simultaneously患有suffer from多种疾病。为了解决to address这个问题,CheXzero (Tiu et al., 2022)定义了阳性和阴性提示positive and negative prompts(如“气胸”与“无气胸”),以兼容的方式对不同的潜在疾病实施零样本zero-shot疾病诊断disease dagnosis(见图10)。
然而,CheXzero提供的诊断缺乏可解释性lacks explainability。为了缓解alleviate这个问题issue,有几种方法尝试在提示设计prompt design中包含incorporate图像的详细描述,包括纹理texture、形状shape和位置location。(Byra et al., 2023;Kim et al., 2023;Yan等,2023;Liu et al., 2010;Pellegrini et al., 2023)。其中,Pellegrini et al.(2023)引入了解释性零样本explainable zero-shot诊断的diagnosis代表性方法representative method Xplainer。具体来说specifically,它们不是直接预测诊断,而是提示模型prompt the model对存在的描述性观察descirptive observations进行分类,放射科医生radiologist会在x射线扫描中寻找描述性观察,并使用所有观察的联合概率joint probabilities来估计总体概率estimate the overall probabilities。这些描述性提示descriptive prompts最初是由ChatGPT通过查询胸部x射线上可能指示特定疾病的观察结果生成的。为了提高这些提示prompts的可靠性reliability,放射科医生radiologists被要求are asked to 根据他们的经验进一步改进它们。在特定疾病(如气胸Pneumothorax)的诊断diagnosis过程中,所有相关观察结果将以阳性/阴性提示positive/negative prompt的形式输入be fed into CLIP文本编码器text encoder,如图11(a)所示。根据每个观测值(从Prob[#1]到Prob[#N])的概率probability,可以估计出一个联合概率joint probability作为be estimated最终结果。图11(b)给出了Xplainer's可解释诊断的定性演示a qualitative demonstration。可以观察到,Xplainer可以正确地检测真阳性和真阴性true positive and true negative情况。虽然它在假阳性和假阴性病例中不能总是做出正确的决定,但两者都显示出相互矛盾的结果contradictory findings(例如,支气管造影bronchogram往往与实变consolidation同时发生co-occur with),这意味着它们很容易被放射科医生radiologists发现detected和纠正corrected。在Xplainer中对潜在原因的说明illustration无疑将提高零样本诊断zero-shot diagnosis的可解释性explainability。
4.1.2. Context optimization
虽然零样本疾病诊断的概念the concept of zero-shot disease diagnosis看起来令人印象深刻impressvie 且有希望promissing,但不幸的是,其在医学影像学领域的广泛应用受到特定领域CLIP模型可用性有限的限制(Zhang等人,2025)。因此consequently,这条研究路线the line of studies 已经转向turned to 非特定领域的CLIP模型,旨在有效地使这些模型适应医学成像领域的背景,并最佳地使用可训练的参数。
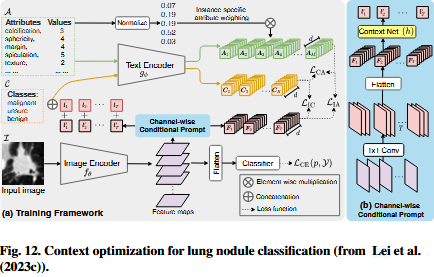
尽管使CLIP适应非分布out-of-distriution的自然图像数据集参数高效调谐parameter-effecient tuning研究(Zhou et al., 2022c,b;Khattak等人,2023)已经被提出,它们都没有none of 考虑医学影像领域。缺乏对领域特征domain characteristics的考虑可能导致性能不理想suboptimal performance。为了解决这个问题to tackle this issue,一些关注上下文优化context optimization的研究(Cao et al., 2024;郑等,2024;Baliah et al., 2023;Lei et al., 2023c)已经提出。CLIP-Lung (Lei等,2023c)提出了基于通道的条件提示(channel-wise conditional prompt, CCP)预测肺结节恶性肿瘤malignancy的方法,如图12所示。与coop (Zhou et al., 2022b)不同的是,它基于特征映射的通道级信息channle-level information构建可学习提示。这种可自适应学习的提示learnable prompt成功地改善了结果。
4.2. Dense prediction
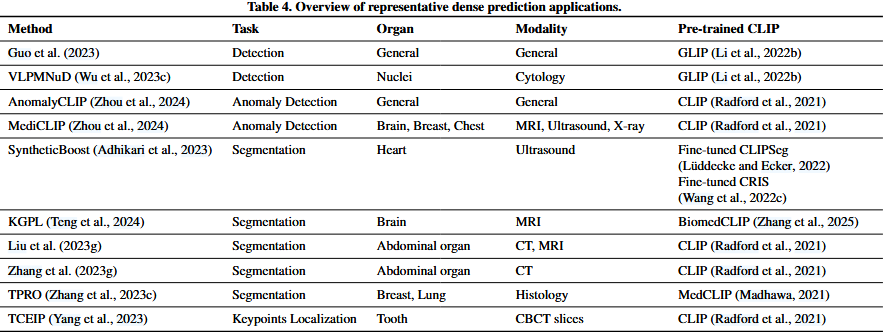
稠密预测(Zuo et al., 2022;Rao et al., 2022;Wang et al., 2021b)涉及为involves图像中的每个像素或像素子集生成输出(见表4)。该任务与分类相反contrasts with,分类为整个图像entire image分配is assigned to单个标签single label。由于owing to 其与人类认知cognition一致的能力,CLIP及其变体variants已被应用于医学成像中的各种vraiety密集预测任务。这方面的研究方法通常作为辅助工具auxiliary tool,为临床医生clinicians提供有价值valuable的信息(例如,目标器官的区域,潜在的病变区域potential lesion regions),以支持他们的决策。
4.2.1. Detection
检测是许多临床场景clinical scenarios的关键先决条件crucial prerequisite,例如手术计划surgical planning(Bouget et al., 2017)、病理诊断pathological diagnosis(Wang et al., 2020;Ribli et al., 2018)和术后评估post-operative assessment(Lo lopez - linares et al., 2018)。以前的方法(Baumgartner et al., 2021;Ickler et al., 2023;Wittmann et al., 2022;Y ø uksel等人,2021)在医学图像检测中通常侧重于利用leveraging通过各种卷积神经网络或基于变压器的架构提取的基于图像的特征。这些方法虽然在一定程度上有效a certain extent,但往往难以struggle with处理医学图像的微妙nuanced和复杂complex性质,特别是在视觉visual线索cues微妙subtle或缺乏absent的病理病例pathology case中(Wittmann et al., 2022)。医学图像中检测任务的流水线pipeline受到视觉语言模型的进步和集成的显著影响,例如such as 直接使用CLIP (Muller等人,2022c)或其扩展GLIP (Li等人,2022b)。Guo等人(2023)提出了一种融合多种文本描述amalgamation of diverse textual descriptions的提示集合技术prompt-ensemble technique,充分利用leverages了GLIP在解释interpreting复杂医疗场景scenarios方面的熟练proficiency程度。此外,VLPMNuD (Wu et al., 2023c)在H&E染色stained图像中引入了GLIP用于零样本核检测zero-shot nuclei detection。提出了一种自动提示automated prompt设计方法,并采用自训练框架对预测框进行迭代iteratively润色polish。
虽然目标检测的重点是识别identifying和定位localizing特定的和预定义的项目,如肿瘤或骨折fractures,但在医学影像异常检测anomaly detection也是一个关键crucial的应用(Fernando等人)。2021年;Tschuchnig和Gadermayr, 2022),其目的是确定identify偏离deviation from规范the norm。AnomalyCLIP (Zhou et al., 2024)展示了showcases CLIP在跨医学领域的零差样嫩异常检测方面zero-shot anomaly detections的能力。AnomalyCLIP使用对象不可知object-agnostic的文本提示text prompts来捕捉各种various图像中正常和异常abnormal的本质essence of。这迫使force CLIP to更多地关注异常abnormal区域,而不是rather than图像中显示的主要对象,从而thereby与以前的方法相比,有助于facilitating更广泛地generalized识别异常anomalies.(Zhou et al., 2022b; Sun et al., 2022; Chen et al., 2023a).
4.2.2. 2D medical image segmentation
CLIP最初是通过文本监督在二维图像域上进行预训练的。因此,它可以很容易地集成到intergrated to二维医学图像的微调fine-tuning分割中。遵循这一思路,Muller等人(2022c);Anand等人(2023)将CLIP预训练图像编码器应用于各种医学成像模式,包括x射线、超声ultrasound和CT/MR(通过将3D数据作为2D切片)。他们的工作表明,CLIP的图像编码器最初是在自然图像上训练的,也可以在医学图像分割任务中提供deliver令人印象深刻的impressive性能performance。此外,Poudel等人(2024)和Adhikari等人(2023)使用employ预训练的CLIP图像和文本编码器构建construct视觉语言分割模型,并对其进行微调finetune,以服务于serve二维医学图像分割任务。
4.2.3. 3D medical image segmentation
越来越多growing number of的公开数据集(Simpson et al., 2019;Heller等人,2019;Liu et al., 2020;Bilic等人,2023)已经允许研究人员训练3D分割模型,以便从体积成像数据中分割解剖结构和病变。然而,这些数据集通常只关注某些器官或解剖结构,而所有与任务无关task-irrelevant的器官和肿瘤都被视为背景,导致部分标签问题(Yan et al., 2020;Lyu等人,2021)。因此,如何打破单个数据集的障碍the barrier of,充分利用fully leverage现有的数据队列cohorts来扩展分割模型的能力仍然是一个制约因素contraint on。
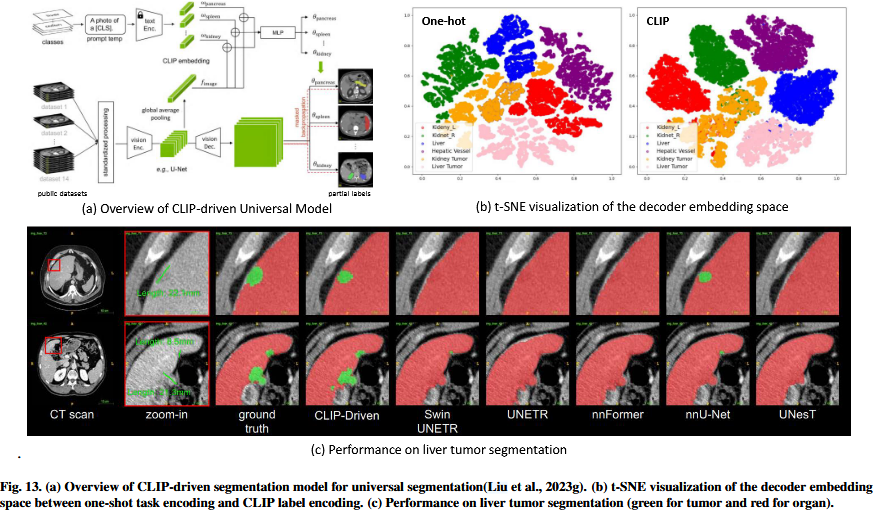
DoDNet (Zhang et al., 2021)是第一个解决tackle医学图像中这种部分标记such partially-labeled问题的分割模型,它不仅提供了比以前的多头网络更优越superior的性能performance(Chen et al., 2019;Fang and Yan,2020;Shi et al., 2021),也是一种灵活flexible的解决方案,可以扩展到新标记的任务。DoDNet引入了针对tailored to 特定任务的动态分割头dynamic segmentation(Tian et al., 2020),将任务表示为单热嵌入one-hot embedding。然而,这种标签正交性orthogonality编码忽略了器官和肿瘤之间的自然语义关系。在DoDNet中,肝脏分割和肝脏肿瘤分割等任务被视为正交orthogonal任务,尽管它们明显表现出exhibit很强的相关性。随着不同distinct的分割任务数量的增加,这种限制会加剧exacerbated。因此,当任务的多样性diversity变得更复杂时,标签正交性orthogonality编码不能有效地泛化generalize。为了解决tackle 上述aforementioned挑战和局限性,Liu等人(2023g)提出了一个CLIP驱动的通用分割模型CLIP-Driven Universal Segmentation Model(见图13(a))从CLIP中学习文本嵌入text emnbedding learned,以取代DoDNet中使用的单热编码one-hot encoding(Zhang et al., 2021)。具体来说Specifically,他们利用预训练的CLIP文本编码器对“肝脏”、“肝肿瘤”、“左肾”、“右肾”、“肝血管hepatic vessel ”、“肾肿瘤”等任务提示prompts进行编码。然后将这些嵌入embeddings与合并后concatenated的图像特征相连接,生成动态分割头generate the dynamic segmentation head,用于在视觉解码器之后对分割结果进行细化。CLIP文本编码器相对于DoDNet单热标签编码one-hot label的优势如图13(b)所示。固定的CLIP标签嵌入embedding能更好地建立established with器官与肿瘤的相关性correlations,即肝脏与肝脏肿瘤的关系、肾脏与肾脏肿瘤的关系。该方法不仅在器官分割方面表现优异superior performance,而且在更具挑战性的肿瘤分割任务中也表现优异,优于suprassing其他纯图像分割模型,如图13(c)所示。将CLIP-Driven Uniserval Model与5种视觉SOTA分割方法进行了比较。通过对肿瘤分割的回顾,CLIP-Driven的分割模型成功地检测出了小肿瘤,即使是在有多个微小tiny肿瘤的情况下,这是大多数仅图像的方法所忽略的。
继Following Liu等人(2023g)之后,Zhang等人(2023g)通过利用leveraging额外的头部和文本提示prompts来处理tackle新任务,将该框架扩展到持续学习中continual learning。正如之前的研究(Ozdemir et al., 2018;Ozdemir and Goksel, 2019;Liu等人,2022a)专注于开发新的损失函数作为额外的约束,或者记忆模块来保存preserve原始数据中的模式patterns,Zhang等人(2023g)利用leverage文本提示text prompts来表示当前任务和先前学习的任务之间的相关性。文本提示text prompts中包含的语义相关性semantic correlation使所建议的模型能够过滤和保留reserve具有优越superior性能的特定于任务的信息。
4.2.4. Others
与完全监督分割不同,弱监督分割weakly supervised segmentation旨在利用弱标注utilize weak annotations,例如点(Bearman et al., 2016),涂鸦scribbles(Lin et al., 2016;Vernaza and Chandraker, 2017),边界框(Dai et al., 2015;Khoreva等人,2017),以及图像级标签的文本或描述(Kolesnikov和Lampert, 2016;Ahn and Kwak, 2018),作为监督训练。类激活图(Class activation map, CAM)是该任务常用commonly-used的解决方案(Zhou et al., 2016),它为卷积神经网络(CNN)提供equipped了注意力定位和伪标签生成pseudo-label generation的能力。然而,CAM只关注对象最具特征distinctive的部分,由于边界忽略boundary neglection,往往会导致低质量的伪标签low-quality pseudo labels,特别是在目标前景和背景之间边界模糊ambiguous的医疗案例中(Chen et al., 2022b)。尽管最近试图扩大broaden CAM的覆盖范围coverage (Lee et al., 2021;Han et al., 2022;Li et al., 2022c;Zhang et al., 2022a),这个基本fundamental问题仍然存在persists。值得注意的是notably,Zhang等人(2023c)提出将语言先验知识language prior knowledge整合intergrate到弱监督学习中,为寻找对象结构提供可靠reliable的帮助assistance。具体来说,他们引入了一种基于文本提示的弱监督分割方法(text-prompting-based weakly supervised segmentation method, TPRO),通过使用预训练的MedCLIP (Madhawa, 2021)将语义semantic标签转换为类级class-level嵌入embedding。另外还采用了一个BioBERT (Lee et al., 2020)来提取标签相应文本描述的详细信息。然后将这些附加的文本监督与图像特征融合fused with,有效地提高了伪标签pseudo labels的质量,从而提供了比其他基于cam的方法更好的性能superior peformance。
考虑到关键点定位keypoint localization,各种方法(O 'Neil et al., 2018;Payer等人,2020;Wu等人,2023b)已经为医学影像领域的挑战而开发。虽然这些方法在许多情况下表现出良好的性能solid performance,但它们仍然难以struggle to 处理复杂的定位环境,即结构不完整incomplete的环境(Lessmann et al., 2019)。TCEIP (Yang et al., 2023)将目标区域的指导性insturtional文本嵌入text embedding of到一个回归网络regression network中,以指导植入物implant位置的预测。通过利用leveraging CLIP, TCEIP能够解释interpret和处理诸如“左”、“中”和“右”等指令instructions以及alongside视觉数据,确保更精确和上下文感知context-aware的结果。它的性能已经超越surpassed了以往的纯图像方法的能力,特别是在具有多个缺牙或稀疏牙齿的挑战性情况下。
4.3. Cross-modal tasks
除了in addition 前面提到的纯视觉任务,CLIP还推动了propelled跨模式任务的发展。这里的跨模态任务是指refers to 图像和文本模态之间的交互作用interaction。代表性representative研究如表5所示。
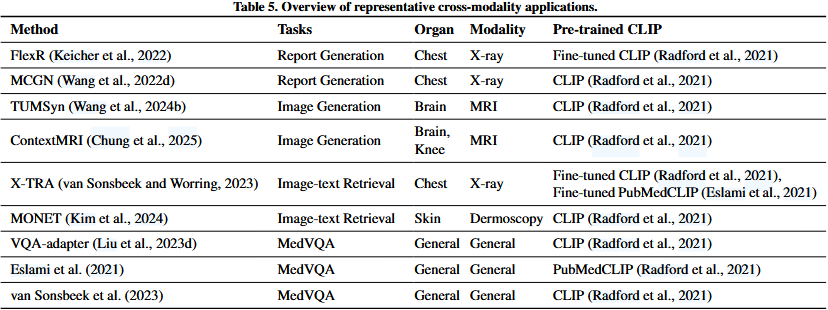 4.3.1. Generation
4.3.1. Generation
CLIP在生成中的应用可分为categorized into报表生成和图像生成。
Report generation.考虑到在临床环境中clinical settings手动manually转录报告transcribing reports的时间密集型过程time-intensive process,越来越倾向于inclination自动化automating生成医疗报告(Liu et al., 2019;Yu et al., 2023)。由于医学报告的有效生成需要识别关键的调查crucial findings、属性和调查间inter-finding的语义关系semantic relations,CLIP天生inherently就适合suitable这项任务,因为它与人类的认知cognition和语义意识semantic awareness保持一致alignment。例如,Wang等人(2022d)采用CLIP的视觉编码器从胸部x射线中提取语义感知semantic-aware的图像表示,然后与可学习的概念嵌入concept embeddings交互interacts,从而hence有利于报告生成的性能。Keicher等人(2022)充分利用fully leverages CLIP的优势,将报告生成任务重新制定为多标签分类任务,标签表明是否存在presence or absence特定的发现。他们将临床发现和训练集中相应位置的所有可能组合combinations汇编comnplie成提示集prompt set。他们利用utiliuze CLIP的零样本zero-shot能力来计算每个提示prompt出现在图像中的可能性likelihood。
Image generation.鉴于CLIP可以弥合bridge图像和语言之间的鸿沟,将该技术应用于文本引导的图像生成text-guided image generation也是直观的intuitive。在这种情况下in this context,Wang等人(2024b)首次尝试基于文本提示从常规获取的扫描中routinely acquired scans生成定制的MRI序列。他们提出proposed的方法,文本引导通用磁共振图像合成(Text-guided Universal MR Image Synthesis, TUMSyn),能够生成适合taiored to 特定文本指令instruction的MRI序列。这些提示prompts包括受试者信息,如年龄和性别,以及MRI参数,如扫描场强scanning field strength、扫描仪类型scanner type 、体素大小voxel size 、反演时间inversion time 等。他们的预训练CLIP文本编码器负责将这些文本提示转换为可由LIFF模型解释的特征嵌入feature embedding(Chen等人,2021),从而在多个评估数据集上实现卓越的superior生成性能。同样likewise,Chung等人(2025)解决address了一个特定的逆向inverse问题,压缩感知compressed sensing MRI。他们认为,在这些元数据such metadata上设置suggest扩散模型conditioning diffusion models可以显著提高该应用程序的性能。
4.3.2. Medical visual question answering
医学视觉问答(Medical visual question answering, MedVQA)是一项需要demand深入理解基于文本的问题和医学图像的视觉内容的任务(Lin et al., 2023c)。它引起了社会的关注drawn attention from the community,因为它将导致更有效efficient和准确的诊断和治疗决策。由于CLIP长期以来因其对齐align视觉和文本内容content的能力而受到青睐been favored,因此recent最近已经做出了在MedVQA中应用CLIP的努力efforts。
之前的工作previous efforts已经将CLIP整合incorpotated到封闭式 closed-ended MedVQA任务中。这些研究(Eslami et al., 2023;刘等人;2023d)通常只将CLIP的图像编码器集成integrate到原有的MedVQA框架中framework,旨在通过语义semantic理解增强图像表示。然而,他们往往tend to 忽视了overlook图像-文本对齐的综合利用comprehensive。此外moreover,封闭式closed-ended MedVQA通常为每个问题提供所有可能的答案选项,这基本上essentially 将任务转换为分类问题。因此,由于这些限制,这些方法的实际practical应用utility似乎受到了限制appears constrained。
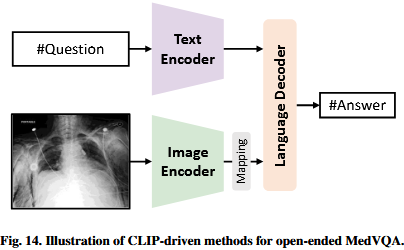
相反conversely,由于CLIP的发展,开放式open-ended MedVQA显示出了希望promise。它没有为每个问题预先定义选项,从而扩大了其对各种场景various scenarios的适用性,并且需要提高heightened capacity图像-文本理解能力image-text comprehension(Lin等人,2023c)。因此,Zhang等人(2023e)分别利用leveraged CLIP的图像编码器和文本编码器进行问题和图像理解,随后with a subsequent使用语言解码器进行答案生成。在图14中说明了illustrate clip-driven的开放式open-ended MedVQA。为了缓解mitigate CLIP预训练数据集与当前MedVQA数据集之间的域差距,通常使用commonly employed映射层。将问题嵌入embedding和变换后的图像嵌入embedding串联起来concatenated,直接输入到语言解码器中,语言解码器可以采用多层转换器multi-layer transformer或语言模型的形式form of ,便于facilitating答案的生成。
4.3.3. Image-text retrieval
检索增强retrieval augmentation(Komeili et al., 2022)涉及involves通过检索相关信息relevant information来补充数据supplementing data,允许利用utilization来自可信知识来源的最新up-to-time信息,本质上提供非参数内存扩展memory expansion(Ramos et al., 2023)。该方法因其通用性versatility而受到gained关注,特别是在检索增强的大型语言模型领域retrieval-augmented large language model(Zhao et al., 2024a;Asai et al., 2023)。然而,现有的检索方法existing retrieval method 往往侧重于全局图像特征(Ionescu等人,2023),这可能导致医学成像的次优结果sub-optimal results。与可能在患者之间相似resemble across的全局特征不同,细微subtle的图像细节对疾病诊断diagnosis有影响,具有重要意义significance。
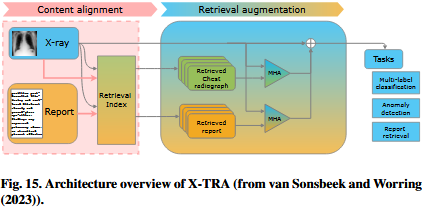
为了解决to address 医学和自然图像之间的域转换问题domain shift ,van sonsheek和Worring(2023)提出了一个基于clip的多模态检索框架 CLIP-based multi-modal retrieval framework。该方法包括如图15所示illustrated的两个主要部分。第一部分涉及involves对原始CLIP模型进行微调finetuning以构建检索模型retrieval model。鉴于医学图像的视觉相似性和小的、局部标记localized markers作为疾病指标indicators的重要性significance,他们提出了一个内容分类器来实现监督的基于内容的对齐。第二部分利用utilizes检索器retriever在跨模态检索增强retrieval augmentation中的输出,通过多头注意(multi-head attention, MHA)增强下游downstream任务。van sonsheek和Worring(2023)在评估其检索方法与以前的疾病分类和报告检索方法的性能时,展示了显著的性能改进,显著优于margin所有现有的检索方法。观察到的性能差异强调underscores了CLIP在构建鲁棒检索方法方面的潜力。
4.4. Summary
在本节中,我们将演示一些典型的CLIP-driven应用程序,以展示在CLIP帮助assistance下的性能改进。虽然这些研究侧重于各种various任务,但它们通常表明,预训练CLIP模型的优势strength of在于lying in其解释和传达人类知识的能力interpret and covery human knowledge。正如Pellegrini et al.(2023)中最好的说明illustrated;Zhang et al. (2023c);Yang等人(2023)将描述性文本提示descriptive text prompts输入到fed to CLIP中,实验结果显示showcase CLIP能够熟练地adeptness理解comprehending嵌入在embedded within提示prompt中的语义semantics,并有效地将语义传递conveying给框架内的其他组件components。这意味着implies CLIP-driven的应用程序可以通过简单修改输入提示的特定内容specific content of the input prompt来适应不同的患者群体,这有利于具有区域或年龄相关差异的疾病的诊断diagnosis或预后prognois。例如,败血症sepsis等疾病在不同种族racial群体中往往表现出exhibit不同的进展模式distinct progressoin patterns(Khoshnevisan和Chi, 2021;Tintinalli et al., 2016),而社区获得性肺炎Community-Acquired Pneumonia的生存率surival rate与患者的年龄相关(Stupka et al., 2009;Ravioli et al., 2022)。通过调整描述性提示descirptive prompt中的内容,开发clip-driven的应用程序可以在不同的组之间无缝地转换seamlessly transition,而不需要重新培训或微调。
5. Comparative analysis
虽然我们在上面调查了investigated两个研究方向research lines的进展advancement of,但本节旨在通过进行conducting比较分析,为社区community提供更实用的指导practival guidance。首先将医学影像领域的CLIP与其他视觉语言模型进行比较,以合理地利用rationalize the utilization of CLIP,然后定量评价quantitatively evaluate不同CLIP模型的有效性effectiveness。
Strengths of CLIP over other vision-language models.正如一项调查surveying医学基础foundation模型的同期研究a concurrent study(Azad et al., 2023)所提到的,自2021年以来出现了各种variety of 视觉语言基础foundation模型,包括Flamingo (Alayrac et al., 2022)、BLIP-2 (Li et al., 2023a)和LLaVA (Liu et al., 2024b)。这些非clip基础foundation模型通常利用leverage图像编码器和预训练的大型语言模型,通过投影技术将图像编码器的潜在空间映射到语言潜在空间,例如门控制xattn密集层gated xatten-dense layers(在Flamingo中),Q-Former(在BLIP-2中)或mlp(在LLaVA中)。为简单起见simplicity,我们将这些视觉语言模型分类为多模态大型语言模型(Multi-modality Large Language Models,MLLMs)。MLLMs受到了社区的极大关注,并专门针对specifically医疗保健应用healthcare applications进行了定制taitored(Moor等人,2023;Van et al., 2024;李等人,2024)。然而,作者认为argue that,至少目前at least currently,CLIP为医学成像领域提供了比其竞争对手competitors更多的好处。MLLM和CLIP的比较comparison见demostrated表6。

首先,由于due tu存在the presence of大型语言模型,MLLMs具有极高的参数计数,使得它们难以部署在边缘计算设备上。这阻碍了hinders它们在医院的广泛应用widespread application,特别是在不发达地区under-developed regions。相比之下in contrast,CLIP仅由一个图像编码器和一个文本编码器组成consists of,需要较少的计算资源。其次,CLIP可以适应adapt to更广泛的任务a wider wariety of tasks,提供更大的灵活性。由于图像编码器和文本编码器是独立的组件,CLIP可以处理单模态任务或涉及involving多模态的任务。然而,在MLLMs中,图像编码器和语言解码器紧密tightly相连,不适合单模态任务,无法preventing it from为下游任务提供 providing高质量的特征嵌入,从而限制了其适用性。另一方面,我们必须承认acknowledge MLLMs在交互性interactivity方面表现出色,提供对指令instructions的直接响应,并提供更好的用户体验offering a better user experience,这是CLIP所缺乏lacks的功能。
综上所述in summary,尽管CLIP缺乏直接的用户交互能力direct user interaction capabilities,但由于其较低的计算资源需求和更广泛的应用场景broader range of allication scenarios,目前currently在医疗人工智能方面,它比MLLMs有明显的优势。
Comparison between different pre-trained CLIP models.所选择的预训练CLIP模型的质量对于CLIP驱动的应用程序至关重要crucial,这促使motivating我们进行conduct定量分析。具体来说Specifically,我们在Zhao等人(2024a)收集的数据集上评估了各种various CLIP模型的性能,该数据集包括来自九个不同领域的图像,如图16右面板所示。我们遵循adhered Zhao等人(2024a)提出的proposed by评价方案evaluation protocol。选择四个预训练模型进行比较:BiomedCLIP (Zhang et al., 2025)、PubMedCLIP (Eslami et al., 2023)、CLIP (Radford et al., 2021)和PMC-CLIP (Lin et al., 2023b)。
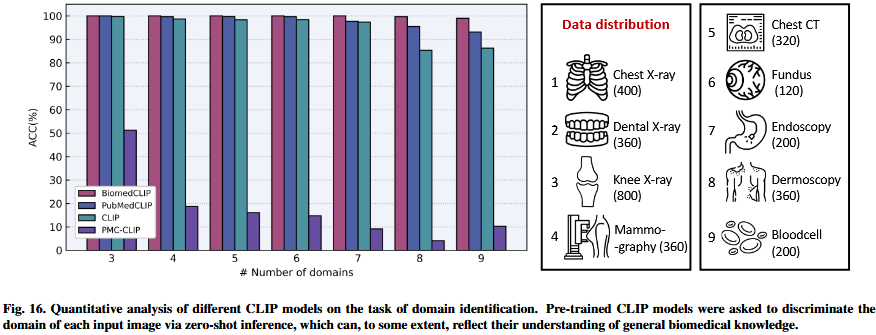
在评估过程中,我们按照图16所示illustrated的顺序逐步progressively增加域的数量,并报告每一步的精度(accuracy,ACC),得出了几个值得注意的观察结果several noteworthy observations:
• BiomedCLIP (Zhang et al., 2025),在内部inhouse 15-scale规模的数据集上进行预训练,毫无疑问取得了unsurprisingly achieved最佳性能。它展示了令人印象深刻impressive的结果,当域的数量从3个增加到increased from to7个时,仍然保持maintaining 100%的准确率。即使涉及到involved所有九个领域,它也达到了98.9%的准确率,显著优于第二名(PubMedCLIP的93.11%)。相比之下in contrast,原始CLIP模型仅使用网络抓取web-crawled数据进行预训练,不幸的是,当处理来自9个域的图像时,其性能下降到degraded86.3%。这些发现表明illustrate,与其他候选candidates相比,BiomedCLIP对posesses专业医学知识的理解更深。
• While PMC-CLIP (Lin et al., 2023b) 在对下游任务进行微调后显示出有希望的结果(Lin et al., 2023b;Zhang等人,2023e),它在域识别上domain identification的表现很差poorly,甚至比在自然图像上训练的CLIP还要差worse。这表明它缺乏零样本能力zero-shot capability。
综上所述in summary ,对于CLIP-driven的应用,BiomedCLIP通常是最推荐的most recommended,这与Van等人(2024)的结论一致。它将视觉特征与特定成像域联系起来的能力突出highlights了它在涉及involving多器官或影像方式的任务中的应用潜力potential。上述aforementioned实验的实现可以在我们的Github项目页面上找到。
6. Discussions and future directions
上述aforementioned部分已经深入delved into研究,要么either利用leverage一个精致refine的CLIP预训练范式paradigm或展示showcase CLIP-driven的临床应用在医学成像领域。尽管despite取得了重大进展significant strides,但仍存在一些挑战和悬而未决的问题open questions。在本节中,我们总结summarize了主要key挑战,并就潜在potential的未来方向进行了讨论。
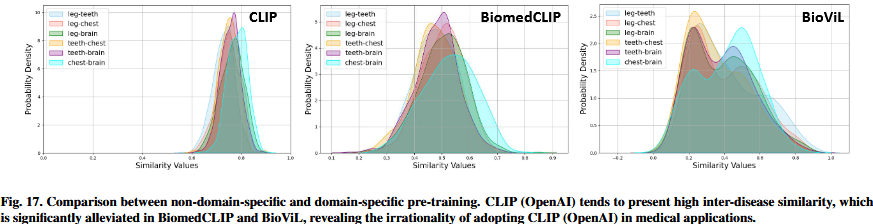
Inconsistency between pre-training and application.一些读者可能会注意到,这两个部分——精细的CLIP预训练和CLIP驱动的应用refined CLIP pre-training and CLIP-driven application——目前是不协调的uncoordinated。理想情况下Ideally,精细refined的CLIP预训练负责为CLIP驱动的应用程序提供特定于领域的CLIP。遗憾的是,本次调查涵盖的CLIP驱动应用程序仍然主要依赖于OpenAI的预训练CLIP(在自然图像-文本数据集上训练),占76.67%的比例proportion很高。这将极大地限制他们在临床实践中practice的表现。在图17中,我们为每个器官选择前20到30个最常见most frequnently occurring的疾病,计算文本疾病嵌入的器官间相似度分布。尽管所选疾病之间存在固有inherent的语义semantic差异,但由此产生的相似性分布揭示了reveals CLIP在有效区分discriminating它们方面面临的挑战,因为在图17的左面板中分布曲线明显重叠。值得注意的是notably,这一问题在生物医学CLIP中得到了显著缓解markedly mitigated,强调underscoring了特定领域CLIP预训练的重要性。同时Simultaneously,为胸部x射线分析量身定制tailored for的模型BioViL显示出最佳性能。这一观察结果强调了underscore专门的预训练CLIP模型的有效性efficacy,强调了emphasizing它们优于广义模型的能力outperform generalized counterparts,特别是在疾病之间的细粒度fine-gained区分discrimination至关重要crucial的情况下。因此,我们认为aruge未来专注于CLIP驱动应用的工作应该采用针对其目标器官的预训练CLIP。即使是专注于上下文优化的研究(见4.1.2节),其目的是有效地微调非领域特异性CLIP以适应特定的医学影像场景scenarios,我们仍然建议使用BiomedCLIP (Zhang et al., 2025)而不是OpenAI的通用 general-purpose CLIP。
Incomprehensive evaluation of refined pre-training.如前面as previously 3.5节所述illustrated,专注于精细化CLIP预训练的研究通常通过各种various评估任务来评估assess预训练的质量。这些评估任务包括那些主要旨在评估视觉编码器的任务,如CLS/ZSC/SEG/DET,以及同时评估simultaneously assess图像和文本编码器的任务,如RET/VQA/PG。然而,问题在于lies in现有的研究往往倾向于favor视觉偏差的评价任务,在一定程度上somewhat忽略了overlooking对文本编码器的评价,这在表2中得到了明显的证明evidently demostrated。CLIP的本质在于lies in图像和文本之间的对齐。只有当视觉编码器和文本编码器都显示出高质量时,它们才能在特定领域的clip驱动应用程序中作为基础组件有效地发挥作用。BioViL (Boecking等人,2022)和BioViLT (Bannur等人,2023)值得认可deserve reacongnition,因为它们对预训练的视觉和文本编码器进行了相对全面comprehensive的评估,并且由于其强大的性能,BioViL已被一些clip驱动的应用所采用(见表3)。对于今后的工作,我们鼓励研究encourage人员进行conduct更全面的评价。这些评估可以包括encompass它们在报告生成(IU-Xray射线(Pavlopoulos等人,2019))、短语基础phrase grounding(MS-CXR (Boecking等人,2022))和VQA (EHRXQA (Bae等人,2023))等任务中的表现。
Challenges of volumetric imaging.虽然许多numerous研究都集中在x射线和组织病理学histopathology图像上,但体积成像方式(如CT和MRI)尽管具有重要的临床应用utility价值,但却受到较少的关注。有几个因素造成这种差异的原因是:(1)处理体积数据的高计算需求。CT和MRI扫描是高维数据,通常需要超过40GB VRAM的gpu。例如,Hamamci等人(2024)使用了四个A100 gpu,每个gpu都有80GB的VRAM,用于他们提出的CT-CLIP模型的预训练。(2)用于训练和评估的大规模带注释的体积数据集的可用性有限。例如,CT- rate (Hamamci et al., 2024)是目前最大的CT扫描和报告配对的公共数据集,仅包含50,000个CT扫描(表1)。(3)缺乏语义对应semantic correspondence。与二维成像相比,体积成像包含encompasses更丰富的信息。然而,这加剧exacerbates了多尺度特征的问题(见3.2节),因为诊断报告中的句子级特征更难以自适应地在数据量中找到它们的视觉对应关系,这将对图像文本对齐的有效性产生不利adversely影响。
虽然计算资源的挑战很难通过技术解决方案来解决,但我们想建议解决其余两个挑战的潜在方向。由于缺乏大规模的体积数据集,合成数据synthetic在医学成像领域显示出有希望promising的结果,可能是一个可行viable的解决方案。合成synthetic数据生成,如Gao等人(2023)所强调的;Shen等人(2023);Hu et al.(2023),可以有效缓解mitigrate疾病类别分布category distributions的不平衡imbalance(Hu et al., 2023;Holste等人,2024),从而thereby增强了深度学习模型的可泛化性generalize。目前currently,已经有一些研究致力于devoted to体积图像数据的合成synthesis(Hamamci et al., 2023;Dayarathna et al., 2023;徐等人,2024;Ou等人,2024)。这一领域的进展有望促进facilitate CLIP的应用。针对语义对应的挑战,眼动追踪eye-tracking数据提出了一种创新innovative 的解决方案。Wang等人(2022b)等研究;Zhao等人(2024b);Kong et al. (2024);Kumar和Marttinen(2024)展示了眼动追踪如何揭示reveal语义相关semantic-correlated的视觉和文本特征。在医学成像解释interpretation过程中,放射科radiologists医生在探索dicatating findings图像的同时simultaneously口述结果(Bigolin Lanfredi等人,2022)。这种并发过程concurrent process可以使用注视数据gaze data将放射科医生口述报告radiologist's dictated report中的每个句子与其相应的视觉区域直接关联起来straightforward association,从而促进了facilitating体积影像的有效多尺度对齐。
Limited scope of refined CLIP pre-training.目前presently,特定领域的CLIP模型是专门为医学成像中的Chest X-rays量身定制的tailored,而其他流行的prevalent图像类型,如乳房x光检查mammorgraphy、膝关节knee MRI和组织学histology,没有充分的研究whithout adequate reasearch。这种限制主要归因于公开可用的医疗数据集的稀缺性scarcity。以前Previously,MIMIC-CXR是医学图像中图像-文本对齐的主要predominant大规模数据集。然而,随着最近发布的FFA-IR(2021年)和两个额外的组织学数据集(2023年),迫切pressing需要进一步推进advancements CLIP预训练,优先prioritize考虑这两个领域,而不是仅仅solely 关注胸部x射线。这两个领域也有其特定的挑战,这使得它们与Chest x-rays不同。FFA-IR数据集具有多视图multi-view诊断diagnosis的特点。眼底荧光素血管造影(a fundus fluorescein angiography,FFA)检查可能包括数十张甚至更多的图像,以全面评估comprehensively assess眼睛血管vascular系统的状况,这比Chest X-ray检查(只有1或2张)要大得多。同时,组织学histology图像具有千兆像素giga-pixel分辨率的特点,通常在块级patch-level进行处理,这鼓励encourage了对patch-level对齐和slide-level对齐的研究。我们期望未来的工作可以开发出更复杂sophisticated的clip式预训练方法,以解决Chest X-ray以外领域的这些问题.
Debiasing in CLIP Models.基于clip的模型的快速发展rapid advancement of 已经揭示了brought to light它们在各种various任务中的令人印象深刻impressive的能力。然而,它也揭示了revealed可能影响这些模型的公平性fairness和准确性accuracy的固有偏见inherent biases。最近的研究表明,基于clip的模型可能会表现出exhibit 明显的偏差significant biases。这些偏差通常来自训练模型的数据和模型本身的设计。例如,Luo等人(2024)和Zhang和Re’s(2022)的研究强调了highlighted CLIP模型如何反映甚至放大amplify训练数据中存在的社会偏见。这些偏见可以以各种方式表现出来,例如:
• Gender and racial biases:CLIP模型可能会表现出exhibit基于base on性别gender、种族race或其他人口统计学因素demographic factors的优惠待遇preferential treatment或刻板印象sterotyping,从而影响模型预测的公平性fairness。
• Domain-Specific biases:在医学影像中,由于不同疾病或群体groups的表现不平衡,可能会产生arise偏差imbalances,从而导致偏差的表现skewed performance。
在医学影像的背景下,CLIP模型的偏差可能会产生严重serious的后果consequence,包括误诊misdiagnosis或护理质量不平等unequal qulity of care。确保ensuring CLIP模型的公平性fair和无偏倚性unbiased对于在医疗保健healthcare应用程序中部署它们至关重要critical。解决addressing这些偏见biases不仅可以提高模型的准确性和可靠性reliability,还有助于建立信任并确保公平equitable的医疗保健服务healthcare delivery。未来的研究应侧重于改进refining去偏技术debiasing techniques并将其应用于医学成像领域。这包括探索exploring如何调整减轻mitigation偏见bias的方法,以应对address医疗应用的具体挑战和要求。
Enhancing adversarial robustness of CLIP.CLIP显著的notable零样本zero-shot学习能力capability使其成为跨各个领域的强大工具。然而,最近的研究表明indicates,它很容易is vulnerable to受到对抗性扰动adversarial perturbations的影响,这可能会显著破坏undermine其性能(Mao等人,2023;Wang et al., 2010;Schlarmann et al., 2024)。例如,Thota等人(2024)证明了demonstrated PLIP (Huang等人,2023b)是一个预先训练过组织学histology图像的基础模型,容易受到susceptible对抗性噪声adversarial noise的影响。这个漏洞vulnerability导致了严重的evere错误分类,强调emphasizing即使是在特定领域数据上训练的模型也不能免受immune对抗性攻击adversarial attacks。同样,Wang等人(2024a)强调highlighted,对抗性扰动adversarial perturbations会降低degrade CLIP在各种任务中的性能,从而thereby对其在关键critical应用中的部署构成posing重大挑战。增强CLIP的对抗adversarial稳健性不仅对于保持maintaining其准确性accuracy和可靠性reliability至关重要essential,而且对于确保ensuring其在医疗保健等敏感sensitive领域的安全有效应用也至关重要。应对addressing这些挑战有望promises取得进步advance CLIP的功能capabilities,并扩展其在鲁棒性至关重要的paramount关键critical领域的适用性。
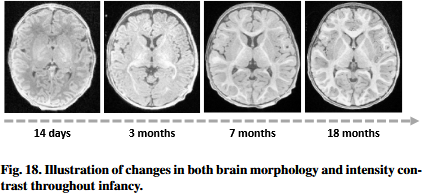
Exploring the potential of metadata.元数据metadata的潜力在很大程度上没有得到充分的开发underexplored。这种类型的数据通常包括一系列患者属性,其中许多可能与视觉形态学morphology表现出exhibit很强的相关性。例如,随着年龄的增长,大脑发育是动态的(Stiles and Jernigan, 2010;Wang et al., 2011;Li et al., 2014, 2019),尤其especially是在婴儿期infancy。图18显示了illustrate整个婴儿期infancy观察到的不同形态varied morphology和组织tissue对比contrast,突出了higlighting年龄信息在大脑相关任务中的潜在重要性。因此,将元数据集成integrating到提示prompt中可以提高深度学习模型在大脑发育研究中的性能。与之前使用多层感知器multi-layer percepton直接编码元数据的方法不同(Cetin et al., 2023;Zhao等人,2021),由于大规模的预训练,CLIP可以为文本嵌入提供语义semantically更丰富的方法。这为未来的研究和探索提供了一条很有前景的途径avenue,在AD诊断diagnosis和脑MRI分割(Teng等,2024)以及阿尔茨海默病(Alzheimer's Disease , AD)诊断(Liu等,2024c)领域进行了conducted多项研究。
Incorporation of high-order correlations.医学影像领域现有的CLIP-style预训练方法仍然主要predominantly坚持adhere图像与文本的正交对齐orthogonal alignment,缺乏对样本间相关性的明确explicit考虑。这种传统做法包括involves将每个图像与其相应的地面真相报告ground-truth report正交对齐orthogonal alignment。如3.3节所述elucidated,由于医学样本之间存在大量substantial的语义semantic重叠,这种方法可能会导致性能下降degradation。尽管已经尝试通过报告间语义相似性来缓解mitigate这个问题,但它们的成功主要primarily依赖于relied on手工制定的handcrafted规则rules和低阶报告间相关性。因此Consequently,高阶相关性的集成integration of是emerges as一种很有前途的解决方案promising solution。
高阶相关性hight-order correlations的有效性effectiveness已经在涉及involving多个信息源或需要解释interpretations复杂关系的任务中得到了很好的证实well-established,包括脑网络分析(Ohiorhenuan等人,2010;Chen et al., 2016;Zhang et al., 2017;Owen et al., 2021;Liu et al., 2023h),多标签分类(Zhang et al., 2014;Nazmi et al., 2020;Si et al., 2023)和多视图聚类multi-view clustering(Li et al., 2022d)。同样,医学图像-文本预训练涉及两种信息(即图像和文本),其语义相关性semantic correlations需要进一步探索explored。因此hence,我们期望未来的研究将devote更多地关注理解comprehending医学图像文本样本之间复杂intricate的语义相关性semnatic correlations,通过高阶相关方法解决图像文本正交对齐orthogonal的挑战。
Beyond image-text alignment.CLIP的理念philosophy围绕着revolves around实现不同模式之间的对齐,特别是图像和文本。在此上下文中,对齐指的是模型理解和建立establish视觉和文本内容content之间有意义的联系的能力。通过理解comprehending视觉和文本信息之间的内在intrinsic联系,CLIP可以在各种跨模式应用中表现出色exceptionally well,反映reflecting了更广泛的趋势broader trend。将CLIP的对齐理念philosophy扩展到其他多模态医学成像是一个很有前途的方向promising direction。医学成像通常包括involves各种various形式,如x射线、核磁共振成像和CT扫描,每种都能提供对同一患者病情condition不同方面different aspects的独特见解insights into。与CLIP的方法类似analogous,在统一的嵌入空间unified embedding space内对齐这些不同的成像模式可能会彻底改变revolutionize医疗数据分析,为医学研究和诊断提供一个进步的方向。这种技术也可以用于对齐来自不同主体的同模态图像,此前各种图像配准技术已经广泛研究investigated过(Jia et al., 2012;Fan等人,2018)。
7. Conclusion
总之in conclusion,我们首次回顾review了CLIP在医学成像中的应用。从介绍支撑underpin CLIP成功的基本概念fundational concepts开始,我们从两个方面深入研究了delve into广泛的文献综述extensive literature review:精炼refine的CLIP预训练方法和多种diverse CLIP驱动的应用。对于改进的CLIP预训练方法,我们的调查survey提供了一个基于CLIP预训练在医学影像领域所面临的独特挑战的结构化分taxonomy类,旨在为研究人员逐步推进该领域的发展filed progressively提供明确的途径chart a clear pathway。在探索exploring不同diverse的CLIP驱动应用时,我们比较了与CLIP相关的方法与那些单独solely的视觉驱动方法,强调emphasizing预训练的CLIP模型可以带来的附加价值added value。值得注意的是,经过深思熟虑thoughtful的设计,它们可以作为serve as 有价值的补充监督信号valuable supplementary supervision signals,显著significantly提高各种任务的性能。除了beyond简单回顾这两部分的现有研究外,我们还讨论了常见问题,为未来的方向奠定了基础laying the froundwork for future directions。通过阐明illuminating在医学成像中使用employing CLIP的潜力和挑战,我们的目标是推动该领域的发展push the field forward,鼓励创新encouraging innovation,为与人类一致的医疗人工智能铺平道路paving the way for human-aligned medical AI。
Acknowledgments
国家自然科学基金项目(资助号grant numbers:U23A20295, 82441023, 62131015, 82394432),国家科学技术部项目(S20240085, sti2030 -重大项目- 2022zd0209000, sti2030 -重大项目- 2022zd0213100),上海市中央引导地方科技发展基金项目(No. 213100);YDZX20233100001001)和上海科技大学高性能计算平台。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









