







 化学空间对接是应对超大规模化合物库(如 BioSolveIT 的 Real Space)的解决方案,它通过构建块对接和组合生成潜在活性分子,节省计算资源。这种方法起源于 FlexX 的片段生长算法,现在通过化学反应规则在不遍历每个分子的情况下筛选化学空间。该技术有望引领虚拟筛选领域的革新,提高药物研发效率。
化学空间对接是应对超大规模化合物库(如 BioSolveIT 的 Real Space)的解决方案,它通过构建块对接和组合生成潜在活性分子,节省计算资源。这种方法起源于 FlexX 的片段生长算法,现在通过化学反应规则在不遍历每个分子的情况下筛选化学空间。该技术有望引领虚拟筛选领域的革新,提高药物研发效率。
传统基于结构的虚拟筛选会遍历化合物库中的所有分子,当化合物库较少时,自然是没有问题。但是,随着化合物库越来越大,发展到了化学空间(即超大规模化合物库),如 BioSolveIT 和 Enamine 联合打造的 Real Space 目前就达到了 230 亿的级别[3],那现有的计算资源就彻底无法满足需求了。
为了适应化学空间的发展,化学空间对接应运而生。要理解这个概念,我们先回到九十年代初期,那是一个知识迸发的时代,前后诞生了多种对接算法,其中就有一种基于片段生长的对接算法 - FlexX。
FlexX 的基本原理是将化合物切割成不同的片段,将不同的片段放置在结合口袋中,最后将片段连接起来形成完整的分子。后来,FlexX 也成为高通量虚拟筛选的首要选择。
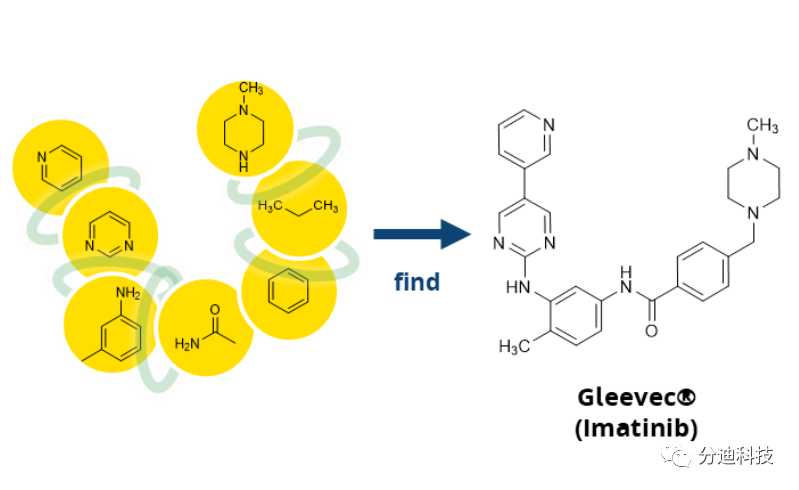
可随着化合物库的逐渐增大,从早期辉瑞的10的12次方到目前葛兰素史克的10的26次方,基于 FlexX 的筛选方法已经无法满足。因为归根到底 FlexX 会将每一个化合物切割成片段,然后在口袋进行片段生长构建完整的化合物,最后遍历化合物库的每一个分子。
但是,当化合物库进化成化学空间时,一切就不同了。因为基于组合化学方式构建的化合空间,都是由一些基本的构建块通过化学规则连接而成。高达两百多亿的化合空间,其实际的构建块可能就仅仅只有十万多个(如 Real Space)。
我们可以简单的将化学空间对接中的构建块理解成 FlexX 中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











