






简介
如果我们必须用一个词来形容今天 AI 的快速发展,那可能就是类似“爆炸性”的词汇。正如《市场研究未来》报告所预测,仅北美地区的大型语言模型市场预计到 2030 年将达到 1055 亿美元。AI 工具的指数级增长与对海量文本数据的访问,为我们开启了比以往任何时候都更好、更高级的内容生成的大门。然而,这样的快速扩张也使得在众多模型中选择合适的工具变得比以往任何时候都更加困难。
本文的目标是让您,AI 爱好者和专业人士,了解该领域当前的趋势和关键创新。以下,我们突出了我们认为目前在行业中引起波澜的前 9 个LLMs,每个都具有独特的功能和专业优势,在自然语言处理、代码生成、少样本学习或可扩展性等领域表现出色。虽然我们认为没有一种适合所有用例的LLM,但我们希望这份列表能帮助您找到最符合您企业独特需求的当前最佳LLM模型。
1. GPT
 从 OpenAI 的生成式预训练变换器(GPT)模型开始,这些模型在每次新版本发布时都持续超越其之前的性能。最新发布的 GPT-4.5(2025 年 2 月发布),提供了增强的自然语言处理能力和网络搜索集成,而其前辈 GPT-4o 和 GPT-4o mini 则在文本、语音和视觉的多模态处理方面表现出色。
从 OpenAI 的生成式预训练变换器(GPT)模型开始,这些模型在每次新版本发布时都持续超越其之前的性能。最新发布的 GPT-4.5(2025 年 2 月发布),提供了增强的自然语言处理能力和网络搜索集成,而其前辈 GPT-4o 和 GPT-4o mini 则在文本、语音和视觉的多模态处理方面表现出色。
GPT-4.5 在自然语言处理、减少幻觉和更自然的交互方面表现出显著改进,而生态系统中其他模型则服务于不同的目的:较小的模型如 o3-mini 和 o3-mini-high 在数学、科学和逻辑推理方面表现出卓越的性能,GPT-4o(“全能”)及其迷你版本专注于多模态能力,而 o1 系列强调反思推理,经典的 GPT-4 则保持为一个可靠的基石。
需要注意的是,GPT 是一个专有模型,拥有保密的训练数据和参数,需要商业许可或订阅——目前通过 ChatGPT Pro 订阅的价格为每月 200 美元——这使得它非常适合寻求优秀对话和实时互动且无预算限制的企业。
对于因预算限制或对其长期集成的不确定性而犹豫是否完全承诺于某一专有模型的公司,Shakudo 提供了一种有吸引力的替代方案。我们的平台目前提供了一系列先进的LLMs,具有简化的部署和可扩展性。通过简单的订阅,您可以在进行大量投资之前访问并评估专有模型(如 GPT)的价值。
2. DeepSeek
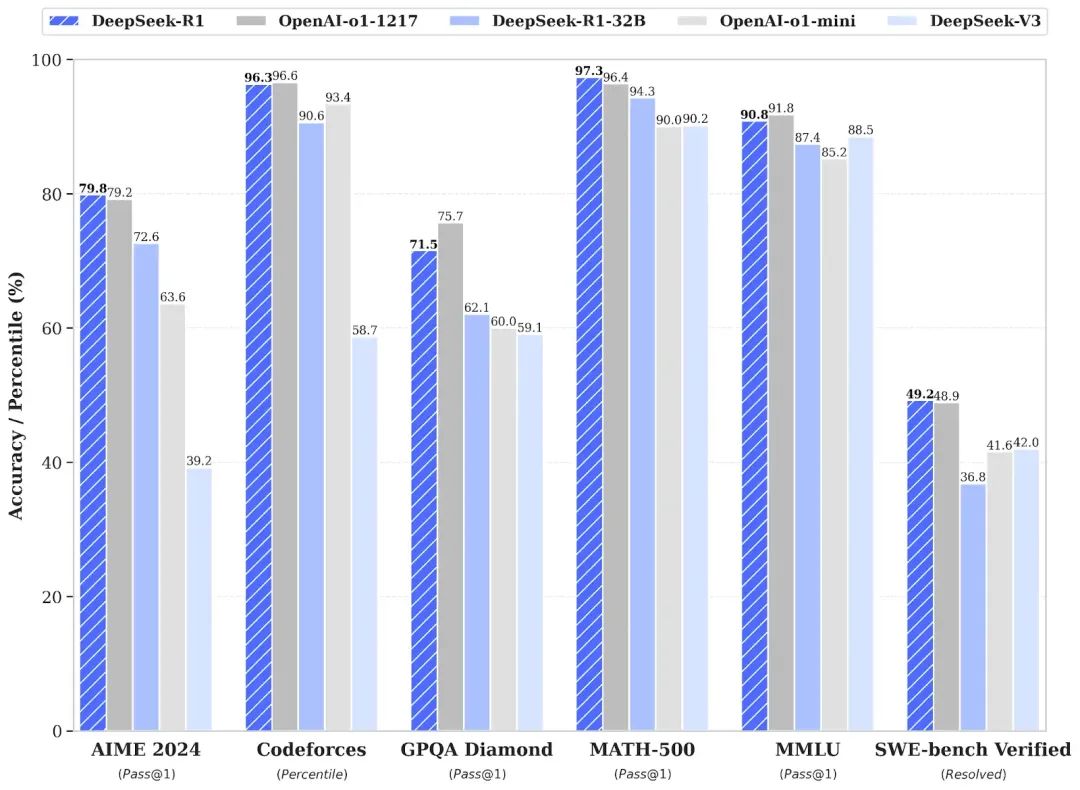
凭借其最新的 R1 模型,中国人工智能公司 DeepSeek 再次为 AI 社区的创新设定了新的基准。截至 1 月 24 日,DeepSeek-R1 模型在聊天机器人竞技场上排名第四,并位居最佳开源语言模型之首。
DeepSeek-R1 是一个 671B 参数的混合专家(MoE)模型,每个标记激活 37B 参数,通过大规模强化学习训练,重点强化推理能力。该模型擅长理解和处理长文本内容,在数学和代码生成等复杂任务中表现出卓越的性能。该模型比 OpenAI-o1 大约节省 30 倍的成本,速度快 5 倍,以极低的成本提供突破性的性能。此外,它在需要复杂模式识别的任务中表现出色,例如基因组数据分析、医学成像和大规模科学模拟。
DeepSeek-R1 的功能在集成专有企业数据,如个人身份信息(PII)和财务记录方面具有变革性。利用检索增强生成(RAG),企业可以将该模型连接到其内部数据源,以实现高度个性化的、上下文感知的交互——同时保持严格的安保和合规标准。借助 Shakudo,您可以通过自动化设置、部署和管理流程来简化高级 AI 模型如 DeepSeek 的部署和集成。这消除了企业投资和维护庞大计算基础设施的需求。通过在现有基础设施中运行,该平台确保了无缝集成、增强的安全性和最佳性能,无需大量内部资源或专业知识。
3. qwen
阿里巴巴一直在积极推动其语言模型阵容的发展,2025 年初发布了 Qwen2.5-Max,随后在 3 月份推出了具有里程碑意义的 QwQ-32B。QwQ 模型特别突出其数学推理和编码能力,在计算资源显著较少的情况下,与 DeepSeek R1 等大型模型有效竞争。
Qwen2.5-Max 在超过 2000 亿个标记上进行预训练,并采用混合专家架构以提高效率。在保持跨基准的竞争力同时,其设计注重易用性和实际部署。该模型具有 32K 个标记的上下文窗口,使其适用于各种企业应用。
对于寻求全面语言模型的企业和开发者,Qwen 系列从 18 亿到 720 亿参数不等。所有模型均在 Apache 2.0 许可下开源,并通过多个平台提供,包括阿里巴巴云 API、Hugging Face 和 ModelScope。该系列获得了显著的关注,已有超过 9 万家企业采用,涉及消费电子、游戏和其他行业。
4. Grok
Grok AI 是由 Elon Musk 的 AI 公司 xAI 开发的一款生成式人工智能聊天机器人。与社交媒体平台 X(原名 Twitter)集成,Grok 为用户提供实时信息访问和充满机智与幽默的对话体验。它旨在处理各种任务,包括回答问题、解决问题、头脑风暴和根据文本提示生成图像。
最新版本,格罗克 3,于 2025 年 2 月发布。该模型使用了比其前身格罗克 2 多十倍的计算能力,利用了 xAI 的科洛塞斯超级计算机。格罗克 3 引入了先进的推理能力,能够将复杂问题分解为可管理的步骤并验证其解决方案。它还具备“思考”和“大脑”模式,以增强问题解决能力,以及一个新的“深度搜索”功能,该功能扫描互联网和 X,针对用户查询提供详细的摘要。
由于该模型在实时数据处理、高级推理和深度互联网搜索方面表现出色,我们建议将其推荐给需要快速新闻分析、编码辅助和动态客户支持的公司。研究型实体可以从中受益于其监控趋势和分析新兴问题的实时能力。
5. LlaMA
Meta 仍然以他们最先进的 LlaMa 模型领先。该公司于 2024 年 12 月发布了最新的 LlaMa 3.3 模型,该模型具备多模态功能,可以处理文本和图像,进行深入分析和生成响应,例如解读图表、地图或翻译图像中识别出的文本。
LlaMA 3.3 在先前模型的基础上进行了改进,拥有长达 128,000 个 token 的上下文窗口和优化的 Transformer 架构。该模型参数量为 700 亿,在多语言对话、推理和编码等领域优于开源和专有替代方案。
不同于 ChatGPT 模型,LlaMA 3 是开源的,这使用户可以根据其基础设施、安全偏好或定制需求自由访问和部署到他们的云上。我们推荐此模型给那些寻求高级内容生成和语言理解的企业,例如客户服务、教育、营销和消费市场。这些模型的开源性也允许您对模型的表现、调整和集成到现有工作流程有更大的控制权。
6. Claude
Anthropic 发布了迄今为止最先进的 AI 模型,名为“Claude 3.7 Sonnet”,该模型集成了多种推理方法,为用户提供快速响应或深入、分步解决问题的灵活性。该模型的突出特点是“扩展思维模式”,利用一种称为深思熟虑推理或自我反思循环的技术,使模型能够迭代优化其思维过程,评估多种推理路径,并在最终输出前进行优化。
Claude 3.7 Sonnet 在编码和前端网页开发方面表现出特别显著的改进,使软件工程任务中的问题解决更加有效。其推理能力通过“扩展思维模式”得到增强,允许进行深入反思和精炼,从而产生更准确和可靠的输出。这些优势,结合总结、内容生成和对话式 AI 的能力,使其成为寻求可靠 AI 以用于客户支持、知识管理和业务自动化的组织的绝佳选择。
7. Mistral
Mistral 的最新模型——Mistral Small 3,一个低延迟优化的模型,已于 1 月底以 Apache 2.0 许可证发布。这个 24 亿参数的模型旨在进行低延迟、高效率的任务。它每秒处理大约 150 个标记,使其比同一硬件上的 Llama 3.3 70B 快三倍以上。
这款新模型非常适合需要快速、准确响应且延迟低的场景,如虚拟助手、实时数据处理和设备上的命令与控制。其较小的体积允许在计算资源有限的设备上部署。
Mistral Small 3 目前在 Apache 2.0 许可下开源。这意味着您可以自由访问和使用该模型来开发自己的应用程序,前提是您遵守许可条款。由于它设计得易于部署,包括在资源有限的硬件上,如单个 GPU 或甚至配备 32GB RAM 的 MacBook,我们建议早期企业使用它来实现低延迟的 AI 解决方案,而无需庞大的硬件基础设施。
8. Gemini
Gemini 是由 Google 开发的闭源 LLM 模型系列。最新模型——Gemini 2.0 Flash——运行速度是 Gemini 1.5 Pro 的两倍,在速度、推理和多模态处理能力方面提供了显著提升。
说到这里,Gemini 仍然是一个专有模型;如果您的公司经常处理敏感或机密数据,您可能担心由于安全原因将其发送到外部服务器。为了解决这个担忧,我们建议您仔细检查供应商的合规性规定,以确保满足数据隐私和安全标准,例如遵守 GDPR、HIPAA 或其他相关数据保护法律。
如果您正在寻找一个功能几乎与 Gemini 相当的开源替代品,谷歌最新的 Gemma 模型 Gemma 2 提供了三种模型,参数分别为 20 亿、90 亿和 270 亿,上下文窗口为 8200。对于寻找相对经济选项的企业来说,这是最佳选择,它能以惊人的准确性解释和理解信息。
9. Command R
由 Cohere 开发的一系列可扩展模型,旨在平衡高性能与强大准确性,就像 Claude 一样。命令 R 和命令 R+模型都提供了专门针对检索增强生成(RAG)优化的 API。这意味着这些模型可以将大规模语言生成与实时信息检索技术相结合,以实现更具情境意识的输出。
目前,Command R+模型拥有 1040 亿参数,并提供行业领先的 128,000 个 token 上下文窗口,以增强长文本处理和多轮对话能力。

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









