







手写数字的识别问题
- 数据预处理
- 获取数据
- 数据装载
- 数据预览
- 模型搭建
- 0、容器
- 1、卷积
- 2、激活
- 3、最大池化
- 4、全连接层
- 5、Dropout层
- 6、softmax层
- 7、前向传播
- 参数优化
- 模型训练与参数优化
pytorch中核心包,torch和torchvision
torchvision.datasets 数据的导入——datasets.MNIST(手写数据集)
torchvision.transforms 数据的变换
torch.autograd 自动梯度——autograd.Variable
import torch
from torchvision import datasets, transforms
from torch.autograd import Variable
数据预处理
pytorch实际计算的是Tensor数据类型的变量,首先处理数据类型转换问题
pytorch中的图像预处理包:torchvision.transforms中有大量的数据变换类(数据增强——缩小,放大,水平/垂直翻转)
transform=transforms.Compose([transforms.ToTensor()
transforms.Normalize(mean=[0.5],std=[0.5])])
torchvision.transform.Compose(组成)看做一个容器,可以同多种数据变换进行组合。传入参数是个列表,列表元素就是对载入数据进行各种变换
transforms.ToTensor——将PIL图片转化为张量(transforms.ToTensor([mean],[std]))具体地说,对每个通道而言,Normalize执行以下操作:image=(image-mean)/std
Python图像库PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了。
transforms.ToPILImage——将变量数据转化为PIL图片(方便图片展示)
transforms.Normalize——标准化变换
transforms.Resize——缩放
transforms.Scale——缩放
transforms.CenterCrop——按自己所需大小,图片中心为参考点,进行裁剪
transforms.RandomCrop(裁剪)——按自己所需大小,对图片随机裁剪
transforms.RandomHorizontaiFilp(水平翻转)——按随机概率进行水平翻转,无定义,则按默认0.5
transforms.RandomVerticalFilp——按随机概率垂直翻转
获取数据
选择本身有的数据库MNIST(手写数字数据集)
data_train=datasets.MNIST(root=r"C:\Users\乔彬\Desktop\fuse\代码\练习数据",transform=transform,train=True,download=True)
data_test=datasets.MNIST(root=r"C:\Users\乔彬\Desktop\fuse\代码\练习数据",transform=transform,train=False)
数据装载
数据下载完成并且载入后,我们还需要对数据进行装载——打包的过程(对图片的处理后,需要将图片打包好,送给我们的模型进行训练。)
装载时通过batch_size的值来确认每个包的大小,通过shuffle(重新洗牌)的值确认是否在装载的过程中打乱图片的顺序(utils(常用工具))
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,batch_size=64,shuffle=True) # 可迭代对象
data_loader_test=torch.utils.data.DataLoader(dataset=data_set,batch_size=64,shuffle=True) # 每个批次的装载数据都是4维的,维度构成batch_size,channel,height,weight(N,C,H,W)
对数据装载使用的是torch.utils.data.DataLoader类,batch_size:设置每个包中的图片数据的个数,每个包中包含64个数据
数据预览
代码使用next(iter())来获取一个批次的图片数据和对应图片标签,iter通路
利用torchvision.utils中的make_grid类方法将一个批次的图片构造成网络模式,参数为(一个批次的装载数据,每个批次的装载数据都是4维的,对应batch_size,channel,height,weight)
images,labels=next(iter(data_loader_train))
img=torchvision.utils.make_grid(images) # 将一个批次的图片构造成网络模式,从(n,c,h,w)变成了(c,h,w),这个批次的图片全部整合到一块
img=img.numpy().transpose(1,2,0) # 将torch.FloatTensor 转换为numpy,transpose将x(0),y(1),z(2)位置调换
std=[0.5]
mean=[0.5]
img=img*std+mean # 变为原始图像,之前标准化img=(img-mean)/std
plt.imshow(img)
1、我们首先要知道什么是可迭代的对象(可以用for循环的对象)Iterable:
dataloader本质上是一个可迭代对象,可以使用iter()进行访问,采用iter(dataloader)返回的是一个迭代器,然后可以使用next()访问。
next()用法:
next(iterator[, default])
- iterator – 可迭代对象
- default – 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。
np.transpose函数,即np.transpose(npimg,(1,2,0)),将npimg的数据格式由(channels,imagesize,imagesize)转化为(imagesize,imagesize,channels),进行格式的转换后方可进行显示。
模型搭建
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__( )
self.conv1=torch.nn.Sequential(
torch.nn.Conv2d(1,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2,kernel_size=2))
self.dense=torch.Sequential(
torch.nn.Linear(14*14*128,1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5)
torch.nn.Linear(1024,10))
def forward(self,x):
out=self.conv1(x)
out=out.view(-1,14*14*128)
out=self.dense(out)
return out
卷积后输出图片大小:N = (W-F+2P)/ S +1
W:输入图片,F:卷积核尺寸,S:步长, P: 填充
0、容器
torch.nn.Sequential(
torch.nn.Conv2d(1,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2,kernel_size=2)
)
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
1、卷积
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
bias(bool, optional) - 如果bias=True,添加偏置
2、激活
torch.nn.ReLU(inplace=False)
-
inplace = False 时,不会修改输入对象的值,而是返回一个新创建的对象,所以打印出对象存储地址不同,类似于C语言的值传递
-
inplace = True 时,会修改输入对象的值,所以打印出对象存储地址相同,类似于C语言的址传递
3、最大池化
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
kernel_size(int or tuple) - max pooling的窗口大小,
stride(int or tuple, optional) - max pooling的窗口移动的步长。默认值是kernel_size
padding(int or tuple, optional) - 输入的每一条边补充0的层数
ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
4、全连接层
torch.nn.Linear(in_features,out_features,bias=True)
in_features–池化后的张量大小(c * h * w相乘)
out_features–全连接层的神经元个数
5、Dropout层
torch.nn.Dropout(input, p=0.5, training=True, inplace=False)
其作用是,在 training 模式下,基于伯努利分布抽样,以概率 p 对张量 input 的值随机置0
**input:**输入张量
**p:**默认 0.5,张量元素被置0的概率;
**training:**默认 True,为 Ture 时执行dropout,为 False 时不执行,与模块模式设置相关;
**inplace:**默认 False,是否原地执行;
6、softmax层
torch.nn.Softmax(dim=1)
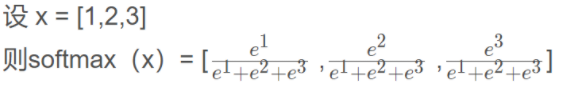
7、前向传播
类内调用——self.xx
self.conv1(x),进行卷积处理;
x.view(-1,14 * 14 * 28)扁平化
self.dense(x),全连接层
return 分类
参数优化
model=Model()
cost=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters())
1、类是你定义的这个新类型,这个类型可以有很多个实例。
比如 a = A(),A是个类,a就是A的一个实例,同样可以b=A(),b也是A的一个实例。
初始化函数__init__在实例刚创建完成的时候调用,这里可以对这个实例的属性进行初始化
class A:
def__init__(self,num):
self.data =num
a =A(1)
在构建类的时候,首先要做的就是对这种类型进行初始化
self 这个关键字相当于实例化对象本身(self相当于d),在实例化过程中,把自己传进去了
super(Model,self).init( )来通过初始化父类属性以初始化自身继承了父类的那部分属性;这样一来,作为nn.Module的子类(LinearNet)就无需再初始化那一部分属性了,只需初始化新加的元素;
2、定义损失函数与优化器
optimizer=torch.optim.Adam(model.parameters())
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
模型训练与参数优化
n_epochs=5
for epoch in range(n_epochs):
running_loss=0.0
running_correct=0 # 初始化损失和准确率
print(f'epoch{epoch}/{n_epochs}')
print('_'*10) # 便于区分5次迭代
for data in data_loader_train:
x_train,y_train=data # 从每个批次中取数据
x_train,y_train=Variable(x_train),Variable(y_train) # 张量变变量
outputs=model(x_train) # 给模型输入训练数据
_,pred=torch.max(outputs.data,1) #dim=1表示输出所在行的最大值
optimizer.zero_grad() # 清空上一次梯度
loss=cost(outputs,y_train) # 获取损失
loss.backward() # 误差反向传播,求梯度
optimizer.step() # 优化器参数更新,即向梯度方向走了一步
running_loss +=loss.item() # 用于将一个零维张量转换成浮点数
running_correct+=torch.sum(pred==y_train.data) # 预测值是否与训练值相等
testing_correct=0
for data in data_loader_test:
x_test,y_test=data
x_test,y_test=Variable(x_test),Variable(y_test)
outputs=model(x_test)
_,pred=torch.max(outputs.data,1)
testing_correct+=torch.sum(pred==y_test.data)
pytorch两个基本对象:Tensor(张量)和Variable(变量),Tensor不可以反向传播,Variable可以反向传播















 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









