



一、RAG的核心价值
通过提供额外信息,让模型从“闭卷考试”变成“开卷考试”,显著提升回答质量
1.1 解决时效性问题
-
让模型知道“今夕是何年”
-
典型场景:查询天气/新闻/最新事件
-
避免因预训练数据过时导致错误
1.2 引导模型按需回答
-
精准应答(客服场景):
-
用户问“你们产品怎么样?” → 提供品牌资料
-
输出:产品优势+购买建议(非幻觉或随机差评)
-
-
知识扩充(专业场景):
-
当问题超出预训练数据范围 → 检索文档补充深度知识
-
二、Naive RAG:四大核心问题与解决方案
2.1 什么时候搜?——避免无效搜索
问题本质
▸ 非所有query需搜索(如“你好”)
▸ 盲目搜索增加成本且干扰回答
解决方案
-
检索判别模型:
-
判断逻辑:时效性/专业性问题优先
-
数据准备:将“无资料难答好”的query作正例
-
效果:85%+准召率
-
-
阈值调节技巧:
-
推理时调低阈值(如>0.4即检索)
-
原则:宁可误搜,不可漏搜(后续可修正)
-
-
业务设计:
-
专业知识库场景默认全搜(如医学RAG)
-
优化补充(来自原文2.5)
-
嵌入模型更新 → 提升粗召效果
-
大模型改写query → 增强可解释性
记忆点:先判再搜,宁滥勿缺
2.2 搜什么?——优化搜索Query
问题本质
▸ 用户Query含糊/指代/多跳(如“后天呢?”→“后天天气?”)
解决方案
-
基础方案:改写模型转自然语言为搜索关键词
-
高级方法:
-
方法
原理
适用场景
HyDE 生成假设答案段落匹配文档
开放域搜索
Query2Doc 改写成伪文档格式
结构化数据库
强化学习优化 根据反馈学习高效query
传统搜索引擎
记忆点:优化问题,模型搜得精准
2.3 怎么搜?——分块与排序策略
问题本质
▸ 文档分块/特征提取/排序方式影响结果
分块经验
| 文档类型 | 分块策略 | 原因 |
| 知识类(维基百科) | 按段落切分 | 每段解释独立问题 |
| 论文/文献 | 较大块(≥1024token) | 保留上下文逻辑 |
| 小说 | 块间重叠设计 | 避免故事线断裂 |
排序优化
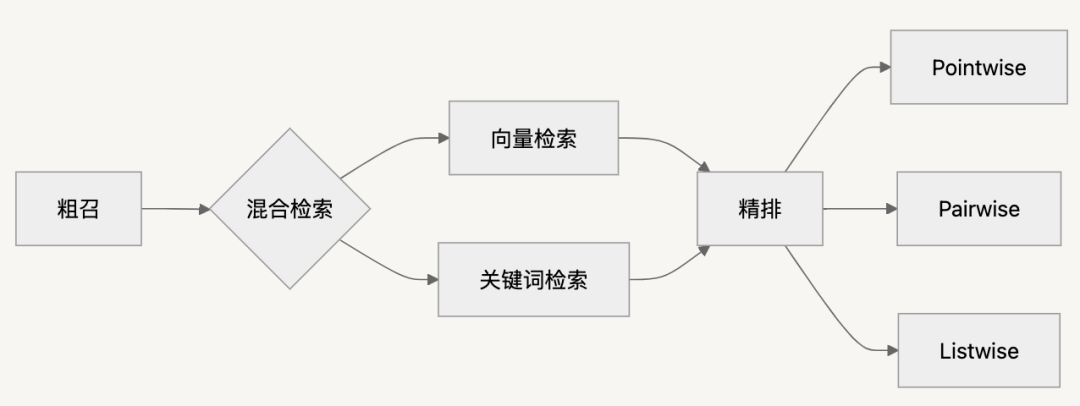
-
精排方法对比:
-
类型
原理
成本
代表工具
Pointwise
单文档绝对打分
低
BGE模型
Pairwise
两两比较排序
高
需交换位置验证
Listwise
LLM直接全排序
中
RankGPT
记忆点:小块粗召,精排定序
2.4 怎么用?——模型处理搜索结果
问题本质
▸ 长文本忽略中间内容(Lost in Middle)
▸ 无关/缺失文档导致幻觉
解决方案
-
位置优化:精排高分文档放输入首尾
-
抗幻觉训练:
-
微调模型学会忽略错误文档
-
Reasoning模型逐步分析结果(需合成训练数据)
-
-
多模态扩展:图文结合(如Caption转文本)
典型风险案例(来自原文2.4)
当要求模型回答“日本和韩国人口”,但只检索到日本数据时:
Qwen/DeepSeek-R1可能幻觉编造韩国数据
解决方案:明确提示模型“资料缺失时需声明”
记忆点:关键信息放两头,领域微调抗幻觉
三、Graph RAG vs Naive RAG
3.1 核心区别
| 维度 | Naive RAG | Graph RAG |
| 适用场景 | 答案在1-2个文档片段 | 答案需关联多个实体 |
| 工作原理 | 分块检索返回段落 | 构建知识图谱关联关系 |
| 优势 | 简单高效、成本低 | 全局视角、逻辑推理强 |
| 劣势 | 无法处理跨文档问题 | 构建成本高、更新复杂 |
3.2 典型案例对比
-
Naive RAG失败场景:
-
任务:总结小说主人公一生
问题:检索返回零散段落 → 模型“读不完”整书 → 回答支离破碎
-
Graph RAG成功场景:
-
同一任务解法:
-
入库构建人物关系图谱(主角→事件1→事件2)
-
模型直接查询图谱 → 流畅总结
-
3.3 关键结论
-
Naive RAG短板:答案分散时=“盲人摸象”
-
Graph RAG代价:构建图谱=付**“预付费”**(前期烧钱,后期高效)
-
终极方案:二者混合使用。
记忆口诀:
“答案集中用Naive,分散关联上Graph;
不差钱就Hybrid,两手抓稳不抓瞎!”
四、Agentic RAG:让RAG学会自主思考
4.1 传统RAG vs Agentic RAG
| 特性 | 传统RAG | Agentic RAG |
| 流程 | 线性:搜索→回答 | 循环 :感知→决策→行动 |
| 能力 | 单跳检索 | 多跳推理+工具协作 |
| 灵活性 | 固定流程 | 自主动态调整 |
| 输入信息 | 基础Query | Query+位置/时间/历史记录 |
| 成本控制 | 检索可能冗余 | 优化检索减少无效生成 |
4.2 三大核心类型
类型1:工具调度员(Tool Router)
▸ 作用:根据问题类型分配工具
▸ 案例:
-
医学问题 → 调用医学数据库
-
数学计算 → 调用计算器
类型2:任务拆解师(Query Planner)
▸ 作用:处理子任务依赖关系
▸ 案例(多步推理):
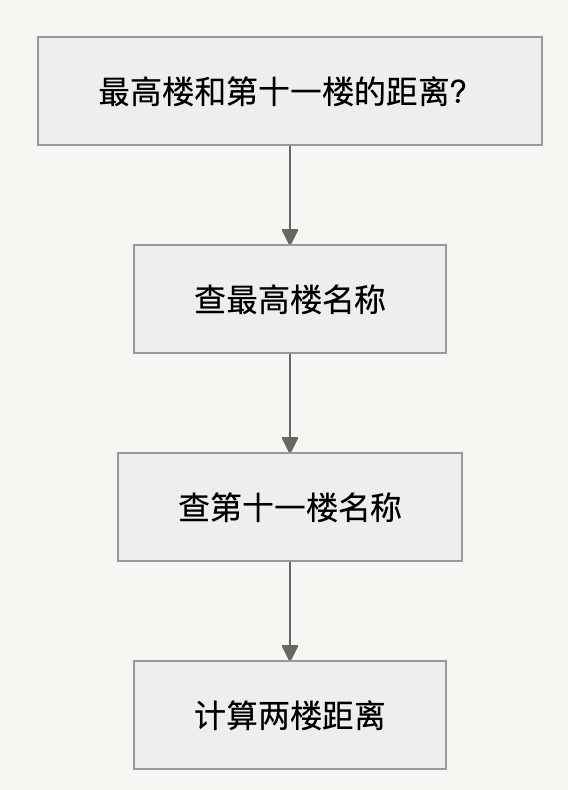
类型3:智能循环机(ReAct Agent)
▸ 作用:失败后重新规划
▸ 案例:
首次搜距离失败 → 改方案:
查A楼经纬度 → 2. 查B楼经纬度 → 3. 计算坐标距离
4.3 设计黄金法则
-
Prompt抽象化:
-
避免具体步骤指令 → 改用“请合理使用工具”
-
-
循环引擎:
-
 Plan → Act → Observe → Repeat
Plan → Act → Observe → Repeat -
成本控制:
-
结果反思模块淘汰低质检索
-
终极总结:
传统RAG是“固定流水线”,Agentic RAG是“自带大脑的瑞士军刀”——能拆解、会调度、懂变通。
五、DeepSearch全流程解析
5.1 核心框架
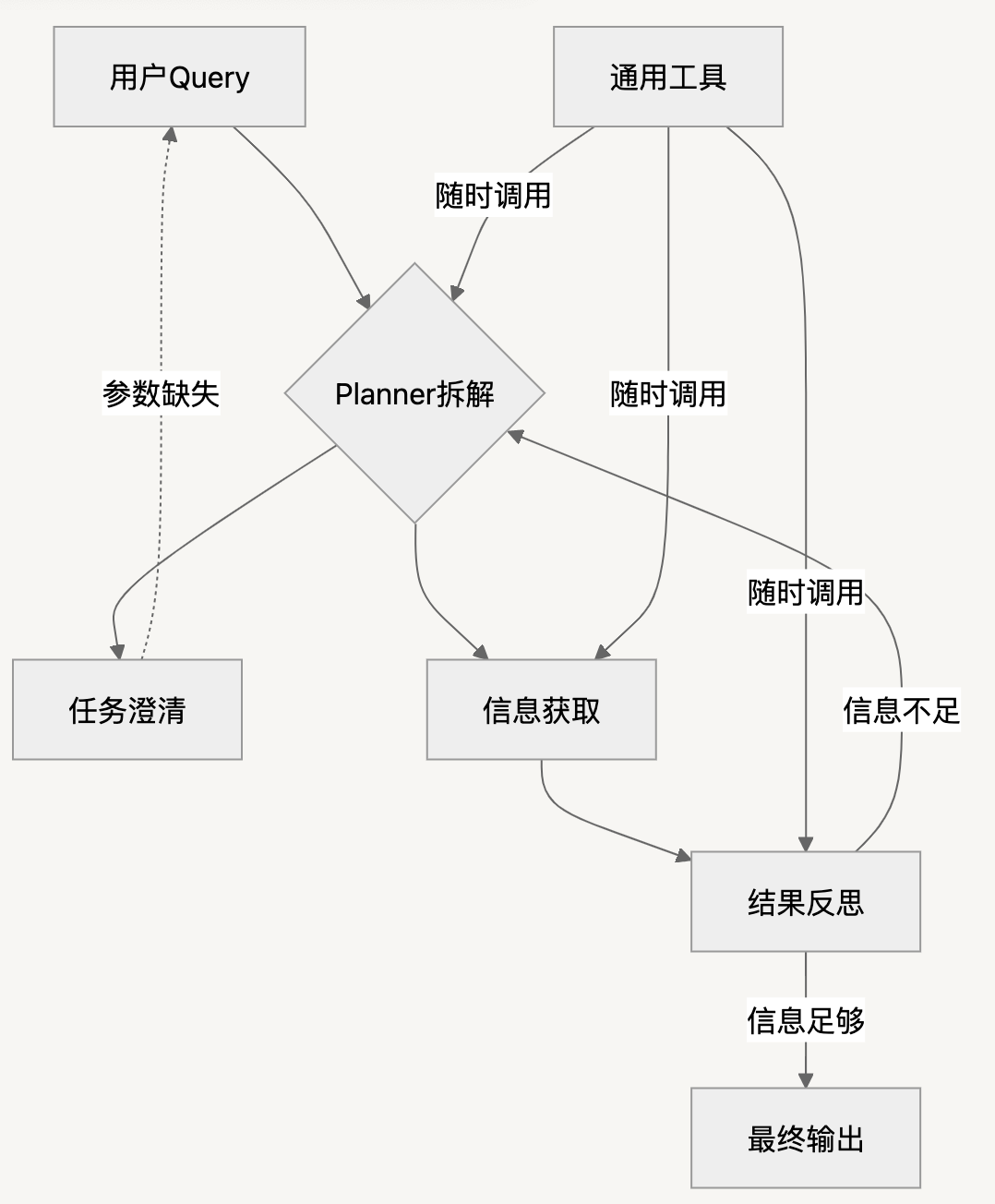
5.2 关键模块详解
模块1:Planner任务拆解
-
输入:用户Query + 历史记录 + 环境信息(位置/时间)
-
预占位规划:
-
案例:“2024中国GDP前三城市人口?”
-
查GDP Top3 → 得城市A,B,C
-
查A人口(占位符实现)
-
查B人口
-
查C人口
-
模块2:任务澄清
-
必要性:避免token浪费(如旅游攻略缺预算参数)
-
交互方案:
-
[ ] 目的地:泰国/新加坡/马来西亚... -
[ ] 预算:3000-5000/5000-7000...
-
[ ] 偏好:自然/人文/美食...
模块3:信息获取
-
双模式调用:
-
方式
优势
直接输出Function Call
减少中间误差
自然语言转工具参数
灵活性更高
-
信息过载处理:
-
精排过滤(相关性打分)
-
去重压缩(保留原文防幻觉)
-
模块4:结果反思
-
循环判断标准:
-
信息完备性 ✓
-
策略有效性 ✓
-
-
设计价值:多模型验证 → 降低单点决策风险
模块5:通用工具库
| 工具 | 典型场景 |
| 计算器 | 预算分配(例:5000×35%÷3人) |
| Python解释器 | 字数统计/数据清洗 |
| 多模态处理器 | 图文混合分析 |
六、总结:RAG技术演进全景
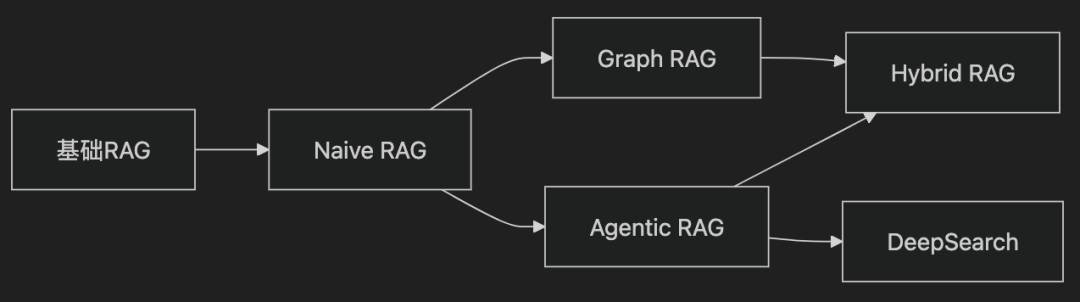
核心结论:
-
简单查询 → Naive RAG(成本优先)
-
全局分析 → Graph RAG(效果优先)
-
复杂任务 → Agentic RAG(动态规划)
-
企业级应用 → DeepSearch(循环验证)


















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









