







1.简介
LSS(Lift, Splat, Shoot) 是一个比较经典的自下而上的构建BEV特征的3D目标检测算法,通过将图像特征反投影到3D空间生成伪视锥点云,通过Efficientnet算法提取云点的深度特征和图像特征并对深度信息进行估计,最终将点云特征转换到BEV空间下进行特征融合和后续的语义分割任务。
本篇按照LSS代码的运行逻辑,结合论文对LSS算法进行解析。
参考链接:
LSS (Lift, Splat, Shoot) 论文+源码万字长文解析
LSS(Lift,Splat,Shoot)-实现BEV感知的最佳利器
LSS解读
LSS: Lift, Splat, Shoot】代码的复现与详细解读
一文读懂BEV自底向上方法:LSS 和 BEVDepth
自动驾驶BEV-LSS系列文章算法代码解析
BEV经典之作Lift, Splat, Shoot解析
2.算法流程

图像来自https://zhuanlan.zhihu.com/p/675034283
-
初始化视锥点云,并根据相机内外参将视锥中的点投影到ego坐标系;
-
对环视图像完成深度特征和图像特征的提取,并构建图像特征点云;
-
基于Voxel Pooling构建BEV特征;
-
对生成的BEV特征利用BEV Encoder做进一步的特征融合;
-
利用特征融合后的BEV特征完成语义分割任务;
2.1 初始化视锥点云
输出:shape为[B, N, 41, 8, 22, 3]的初始视锥点云
B:`batch_size`
N:相机数量
41:为每个像素生成离散的41个深度值
8*22:后面图像经backbone下采样后的特征图大小
3:XYZ三个通道的坐标值
2.1.1 初始化视锥点云的shape
1.相机投影几何:
根据之前的相机投影知识可以了解到,2D图像像素点
p
2
d
p_{2d}
p2d是3D空间下某个点
P
3
d
P_{3d}
P3d的投影,二者一一对应,从相机光心出发连接图像中的像素点可以得到一条射线,
P
3
d
P_{3d}
P3d一定在这条射线上。
但实际上对于单目相机中的某个像素点是无法得到具体的深度信息的,因此需要对深度进行估计,LSS采取的办法是对于图像中的每一个像素,在对应射线上每隔1m进行采样(算法中是41个),这样每个2D像素点都有41个3D点和他对应,这样就得到一组视锥点云(伪),然后通过提取深度特征并离散为深度概率信息估计像素深度
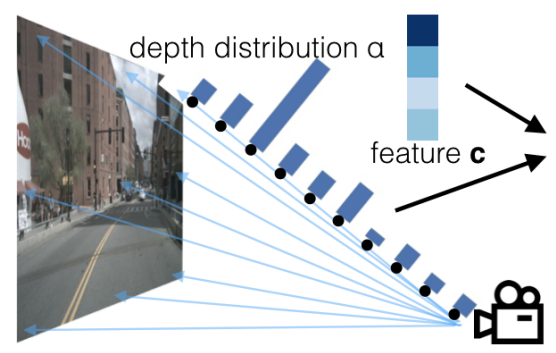
2.视锥点云的初始化过程:
定义距离图像特征平面4m到44m、间隔1m的多个平面,这样每个图像特征点有D=41个可能的离散深度值。每个点相对相机的描述的位置是[h, w, d],最终得到一个在图像坐标系下的数量为D*H*W的一组伪点云数据,H和W表示图像的高和宽,D表示离散深度的维度。
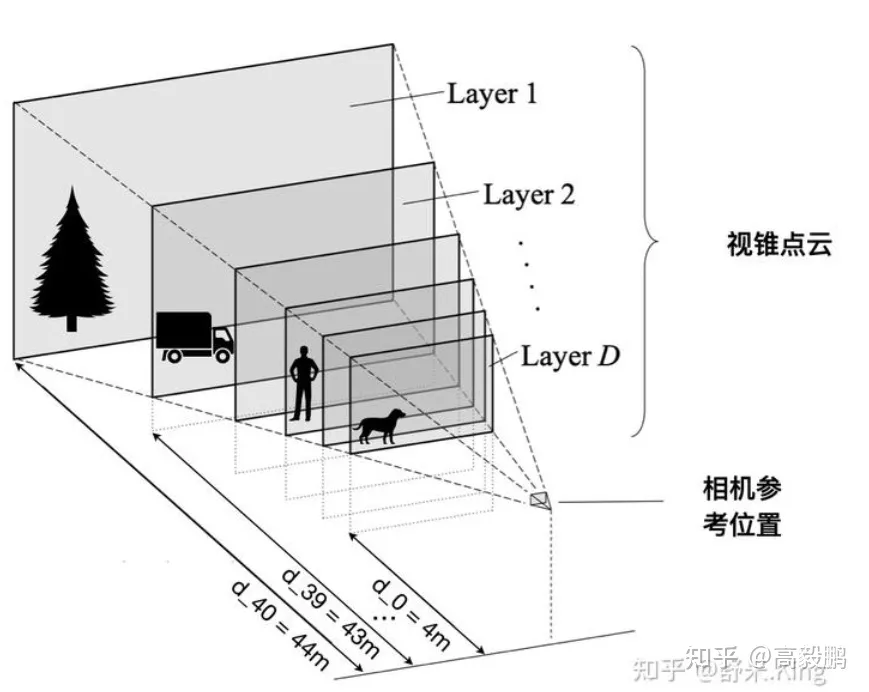
2.1.2 将视锥点云变换到自车坐标系(ego坐标系)
注意,这里转换的是上一步初始化的原始视锥点云,不包含深度特征和图像特征,只是一组云点。
整体的过程: 图像坐标系 -> 归一化相机坐标系 -> 相机坐标系 -> 车身坐标系
整个转换过程比较清晰简单,就是3D点投影到图像平面的逆过程
- 生成的视锥点云每个点用
(u,v,d)进行描述,即图像坐标系下的坐标和对应的深度值 - 首先将图像坐标系下的坐标
(u,v,d)通过内参K转换到归一化坐标(x,y,1),公式如下:
[ x y 1 ] = 1 d K − 1 [ u v 1 ] \begin{bmatrix} x\\ y\\1\end{bmatrix}=\frac{1}{d} K^{-1} \begin{bmatrix} u\\ v\\1\end{bmatrix} xy1 =d1K−1 uv1 - 将归一化平面坐标转换为相机坐标系下的3D坐标:
[ X c a m Y c a m Z c a m ] = d [ x y 1 ] \begin{bmatrix} X_{cam}\\ Y_{cam}\\Z_{cam}\end{bmatrix}=d\begin{bmatrix} x\\ y\\1\end{bmatrix} XcamYcamZcam =d xy1 - 将3D点通过外参
[R, t]由相机坐标系转换到自车坐标系;
[ X e g o Y e g o Z e g o ] = R [ X c a m Y c a m Z c a m ] + t \begin{bmatrix} X_{ego}\\ Y_{ego}\\Z_{ego}\end{bmatrix}=R\begin{bmatrix} X_{cam}\\ Y_{cam}\\Z_{cam}\end{bmatrix}+t XegoYegoZego =R XcamYcamZcam +t
2.2 提取环视相机的深度特征和图像特征
输入:原始环视图像
shape=[bs, N, H, W, 3],bs表示batch_size,表示环视相机的数量,
在特征提取时将这两个维度合并一起进行特征提取
输出:深度和图像语义特征
shape=[bs * N, C, D, H, W]
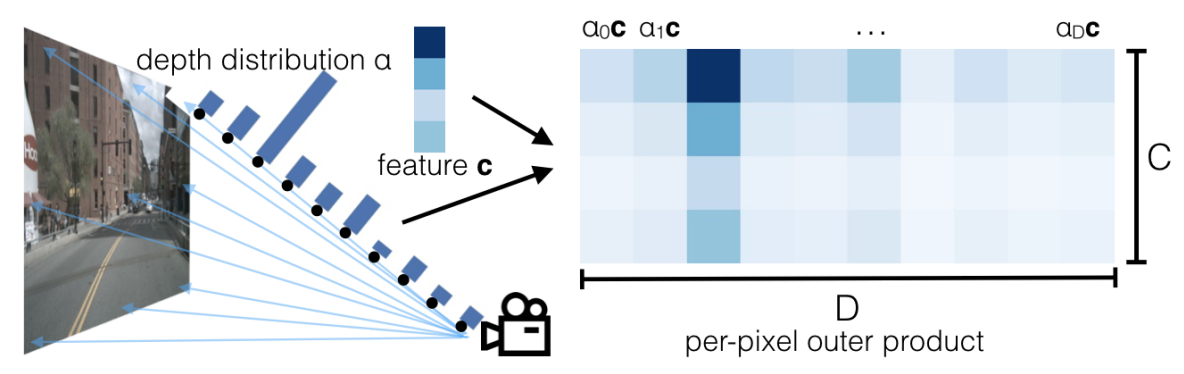
图像在输入到LSS的图像特征编码器后,会使用Efficientnet网络对图像提取 D=41维的深度特征 和 C=64维的语义特征,将深度特征和语义特征进行外积操作会进一步得到关于每个3D对应点更加准确的深度概率分布。
1.特征提取:
每一条射线表示某个像素点对应的一组3D点(共D=41维),在提取深度特征后会通过softmax函数将其转换为对应的概率信息,每个α表示对应点的深度概率。
每个feature c表示了每个像素点对应的特征向量(共C=64维)。
这样每个像素点会有一个D=41维的深度特征和C=64维的图像特征和其对应。
2.外积处理
对像素点的深度概率和图像特征进行外积,于是就为特征图的每一个点赋予了一个depth 概率,然后广播所有的 αc,就得到了不同的channel的语义特征在不同深度(channel)的特征图,经过训练,重要的特征颜色会越来越深(由于softmax概率高),反之就会越来越暗淡,趋近于0。
2.3 基于Voxel Pooling构建BEV特征
输入:视锥点云+特征点云
视锥点云:shape为(B, N, 41, 8, 22, 3),包含了每个点在自车坐标系中的位置
特征点云:shape为(B, N, 41, 8, 22, 64),包含了每个点的context特征(深度+语义)
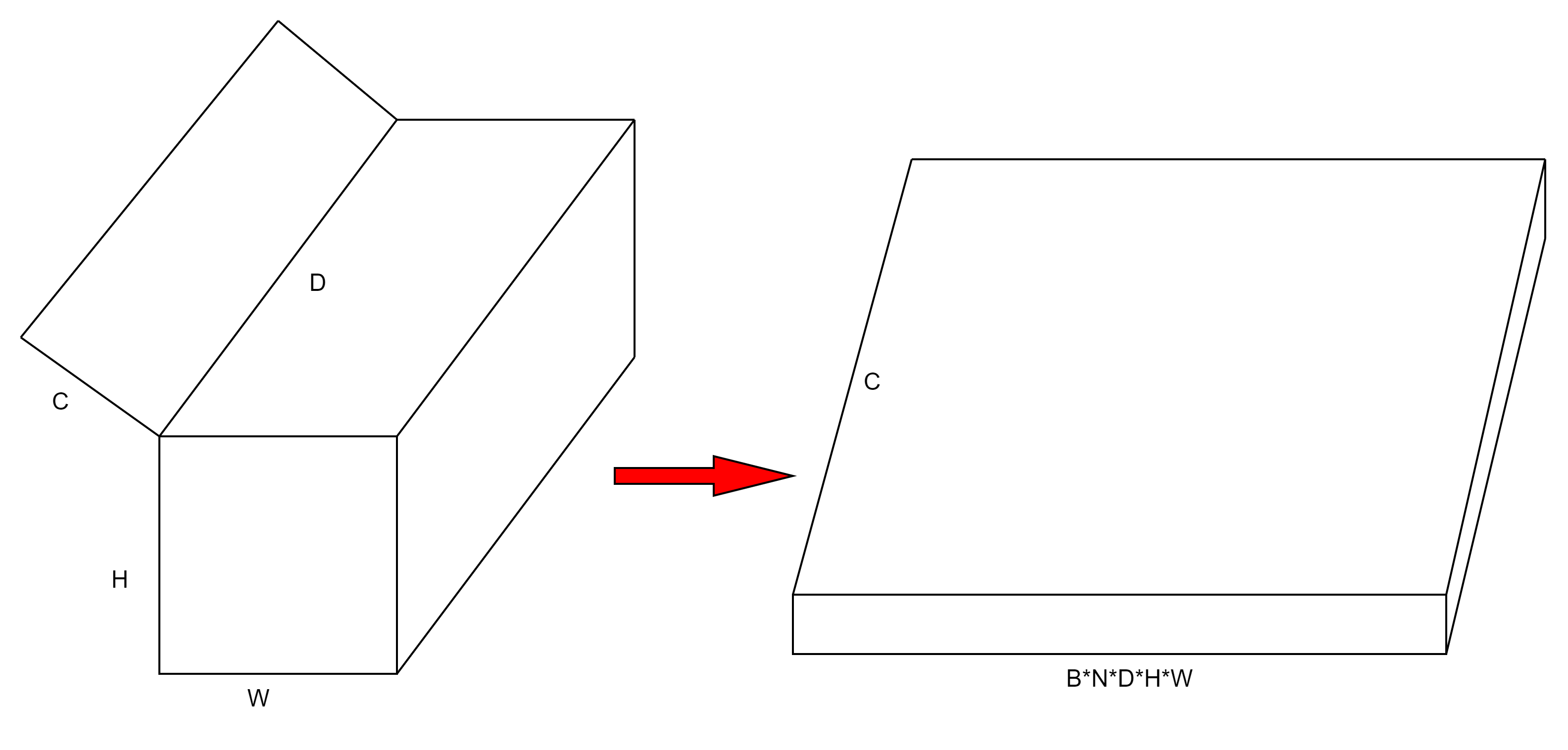
- 将特征点云展平(
flatten)。上一步将深度特征和图像语义特征作外积后得到一个B*N*D*H*W*C的张量,B表示batch的数量,N表示相机的个数,D表示深度通道,H*W表示高和宽,C表示语义通道,flatten后得到一个C个通道的一维张量,这个一维张量包含B*N*D*H*W个点
- 将ego下的空间坐标转换到BEV网格坐标,排除掉落在BEV空间之外的点(BEV空间的大小固定,一般是以车体为中心的200*200的网格空间),然后将网格坐标展平,同样可以得到一个一维张量,该张量有4个通道
(x,y,z,batch_id),这个一维张量包含B*N*D*H*W个点 - 将所有的feature基于坐标位置进行排序,给每一个点一个rank值,rank相等的点在同一个batch和同一个BEV pillar,这样就把属于相同BEV pillar的体素放在相邻位置,得到点云在体素中的索引
- 采用cumsum_trick完成Voxel Pooling运算,上一步将特征值进行了排序,将落在同一个pillar的特征累加,最终获得新的张量。
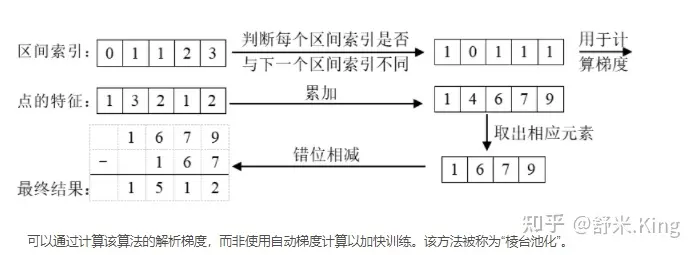
因为多个视角的相机形成的视锥点云会存在交叉现象,对于上图,已经知道一个特征向量1 3 2 1 2,每个特征的区间索引为0 1 1 2 3,区间索引表示每个特征所属的BEV网格,通过上述排序操作将属于同一batch同一BEV网格的特征放在了相邻位置,现在要做的是将属于同一BEV网格中的特征进行累加,根据区间索引得知第2位和第3位的特征属于同一个BEV pillar,因此在进行累计求和后的结果为1 5 1 2
2.4 BEV特征融合和语义分割
为了执行语义分割任务,最后还接个BevEncode对BEV特征进一步进行编码,BevEncode由一个2d Conv、resnet18的前三层、以及两个上采样层组成,最终输出的特征图shape为(4, 1, 200, 200)。















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









