








今天的论文参考了2019年KDD的paper《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》和2020年的paper《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》,这也是阿里妈妈盖坤组最新的在定向广告方向的研究实践成果,即在进行CTR预估的时候考虑了用户更长时间的行为序列信息。
首先从整体来讲,我觉得这篇paper是有一定划时代的意义的,和之前看到的只是从改进模型结构本身来提升CTR不同的是,这篇paper体现了下一代推荐系统的发展趋势:算法和架构的 co-design,这也是我在去年9月份的AI大会上听阿里妈妈资深算法专家朱小强提到的。
众所周知,随着深度学习的到来,给各个行业都或多或少的带来了很多增益,其中属广告推荐等领域获益最大,因为这些领域积累了大量的用户行为数据。于是在一开始的时候,所有算法工程师要做的事情就是不断提升模型的复杂度,从这些海量而复杂的用户行为序列中学习规律,其实包括学术界也是一样,结构复杂、眼花缭乱的复杂模型架构层出不穷的出现在各种顶会的paper上。确实在一开始的时候,越复杂越精巧的模型总能不断刷新各个场景模型的baseline,这也得益于GPU等硬件设备的优化、普及和推广以及越来越模块化、易用的深度学习框架。我们称这一时期为计算力的红利,从DNN => DIN => DIEN模型越来越复杂,这一时期一直到2018年年底,工业界的很多人会越来越感到计算力红利差不多到了一个瓶颈,因为由于硬件本身技术的限制,模型的复杂度被限制在了一个瓶颈下,再提升模型的复杂度,可能就没法到达工业界要求的响应时延。再往后看,在硬件技术无法取得突破性进步之前(硬件技术的本质突破是很难在短时间内完成的),恐怕单纯的提高模型复杂度已经走不通了。那么在下一个硬件技术期突破来临之前,当下的最可能能够进一步提升系统效果的思路就是:算法和架构的co-design。
而今天讲的paper就是模型和架构co-design的一个比较初步但是有效的实现,即2019年的paper《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》。
话不多说,先上架构图:
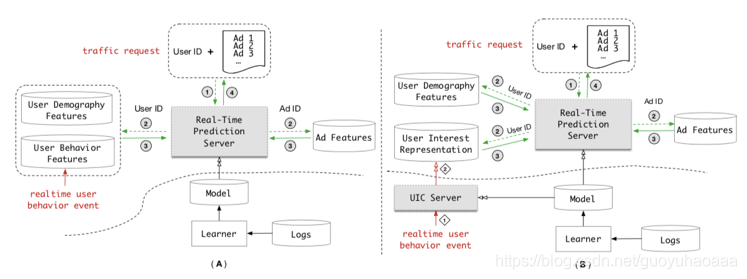
左边的是阿里原来的定性广告预测架构图,右边是改进后的架构图。图中的traffic request是粗排那边得到的广告集合很和用户当前请求组成的request,传统的方法是根据当前的用户ID去数据库里提取用户在一段时间内的行为序列(一般是2周),然后对用户在2周内的行为数据进行建模分析,这种架构最大的缺点就是,因为有在线响应时延的要求,用户行为序列的处理长度是有限的,对于有些特别活跃的用户,可能2周内的行为序列长度有1000以上,对于这种只能强制截取了。但是作者通过绘制如下图:
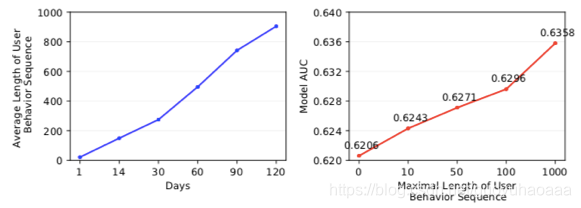
从图中非常容易的可以看出,时间段范围越长,用户的平均行为序列越长;模型使用越多的用户行为序列,那么就能达到更好的AUC值。所以如果能在保证在线时延的情况下,尽力增加模型可以建模使用的行为序列长度,对最终的CTR一定是大有好处的。
于是作者提出了名为:UIC(user interest center) Server的一种结构。其实这个UIC里面就存储了每一个用户的点击行为序列信息,不过这个信息是经过了编码压缩之后的,不是原始的、直接的点击序列样式。这样,在进行traffic request响应的时候,系统直接去UIC去取之前算好的用户行为序列表征,即解耦用户兴趣建模和CTR预估。而从图中也可以非常清楚的看出,这个UIC是当每次用户有行为的时候进行更新,而不是traffic request的时候一起算。这里我要说明一下,这篇paper的应用场景是手机淘宝打开的时候的定向广告推荐,这在paper里叫做traffic request,而用户打开手机淘宝后,会对一些商品有点击、购买等行为,这个叫做realtime user behavior。不难看出这个UIC的结构是非常重要的,也是本文最大的创新点。
从整个系统的运行角度来说,UIC的在线步骤和预测模块的在线部分是独立的,论文里称UIC为“latency free for realtime”,即UIC是伴随用户每次点击商品就会及时更新用户状态,而预测模块在用户发起traffic request的时候,直接去UIC里取计算好的用户行为状态,整个UIC的结构如下所示:
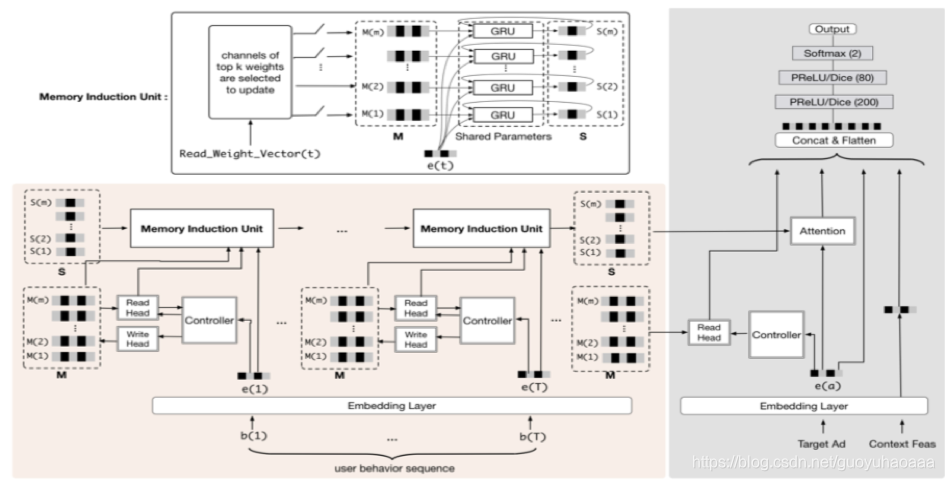
为了从用户超长的点击序列(通常在1000以上)中全面、准确地压缩抽取出用户的多样化的兴趣,paper作者基于memory network的思想提出了一种称之为“multi-channel memory network”的架构,示意图如下所示:

因为每个用户的点击序列可以反映出其多样化的兴趣爱好,也就是说一个序列在一个人多种的兴趣爱好之下下产生的,“multi-channel memory network”可以根据用户的点击序列,来自动的对其中每一个channel network的参数进行跟新,从而达到了对用户行为序列信息进行存储于压缩,原来长度超过1000的行为信息,被压缩到了固定长度的多channel的memory network,参数表示为
{
M
t
(
i
)
∣
i
=
1
m
}
\{M_t(i)|_{i=1}^m\}
{Mt(i)∣i=1m},其中m就代表了channel的数量,需要注意的是每一个用户会对应于一个独有的memory network,不同用户之间的memory network是不共享的。下面讲解一下memory network的状态更新过程:
1 memory read
当接收到用户t时刻的行为,controller就产生一个read key
k
t
k_t
kt(在具体实现中这个controller是由GRU来做的,这个read key包括后面的write key,add vector 和 erase vector是由当前t时刻用户浏览的商品和上一时刻的状态一起作为GRU的输入而产生的),然后这个
k
t
k_t
kt就会对memory network中的不同的channel向量进行相似度的计算得到
w
t
r
w_t^r
wtr:
w
t
r
(
t
)
=
e
x
p
(
K
(
k
t
,
M
t
(
i
)
)
)
∑
j
m
e
x
p
(
K
(
k
t
,
M
t
(
j
)
)
)
w_t^r(t)=\frac{exp(K(k_t,M_t(i)))}{\sum_{j}^mexp(K(k_t,M_t(j)))}
wtr(t)=∑jmexp(K(kt,Mt(j)))exp(K(kt,Mt(i)))
其中分子分母中的
K
K
K运算就是向量计算cos夹角的操作。得到了read key针对每一个memory channel的相似度权重,然后进行加权求和操作:
r
t
=
∑
i
m
w
r
t
(
i
)
M
t
(
i
)
r_t=\sum_{i}^mw_r^t(i)M_t(i)
rt=∑imwrt(i)Mt(i)
2 memory write
和memory read部分一样,也会产生一个write key,继续和memory channel进行相似度计算,最后得到
w
t
w
w_t^w
wtw,在这一步骤中controller会继续产生一个erase vector
e
t
e_t
et和add vector
a
t
a_t
at,接下来就是
M
t
M_t
Mt的状态更新公式了:
M
t
=
(
1
−
w
t
w
⨂
e
t
)
⨀
M
t
−
1
+
w
t
w
⨂
a
t
M_t=(1-w_t^w\bigotimes e_t)\bigodot M_{t-1}+w_t^w\bigotimes a_t
Mt=(1−wtw⨂et)⨀Mt−1+wtw⨂at
其中
⨂
\bigotimes
⨂代表了outer product操作,
⨀
\bigodot
⨀代表了dot product操作。
当然作者发现了这些不同memory channel之间的更新并不是公平的,特别当用户点击序列里面大量都是热门商品的时候,这样就会使某一个或两个memory channel更新比较频繁,为了解决这个问题,作者提出了一种正则策略,即对最终
w
t
w
w_t^w
wtw再乘以一个参数矩阵
g
t
g_t
gt,使其累计权重值能够更加的平均一些:
P
t
=
s
o
f
t
m
a
x
(
W
g
g
t
)
P_t=softmax(W_gg_t)
Pt=softmax(Wggt)
w
t
n
e
w
=
w
t
w
p
t
w_t^{new}=w_t^wp_t
wtnew=wtwpt
w
n
e
w
=
∑
t
=
1
T
w
t
n
e
w
w^{new}=\sum_{t=1}^Tw_t^{new}
wnew=∑t=1Twtnew //代表了截止到T时刻为止,累计
w
w
w^w
ww权重之和
L
r
e
g
=
λ
∑
i
=
1
m
(
w
n
e
w
(
i
)
−
1
m
∑
i
=
1
m
w
n
e
w
(
i
)
)
2
L_{reg}=\lambda\sum_{i=1}^m(w^{new}(i)-\frac{1}{m}\sum_{i=1}^mw^{new}(i))^2
Lreg=λ∑i=1m(wnew(i)−m1∑i=1mwnew(i))2 //m代表了memory channel的数量
3 memory induction unit
由于memory network存储的是原始的用户行为记录信息,但是对于用户行为的演化确没有很好的建模,为了对用户行为演化信息进行很好的建模。因此这里就引入了以GRU为具体进行实现的memory induction unit,结构图如下所示:
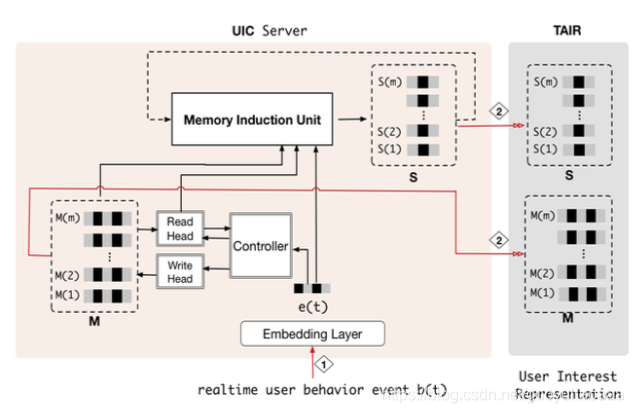
在每次经过了memory write操作更新了memory network的参数之后,即从
M
t
−
1
=
>
M
t
M_{t-1}=>M_t
Mt−1=>Mt之后,会选取
t
o
p
k
(
w
t
r
)
∣
i
=
1
k
top_k(w_t^r)|_{i=1}^k
topk(wtr)∣i=1k 对应的memory slot信息输入到GRU中,公式如下:
S
t
(
i
)
=
G
R
U
(
S
t
−
1
(
i
)
,
M
t
(
i
)
,
e
t
)
S_t(i)=GRU(S_{t-1}(i),M_t(i),e_t)
St(i)=GRU(St−1(i),Mt(i),et)
最后作者通过实验证明了这种实验结构是有效的,尤其是在对超长用户行为序列建模方面相比于之前只使用最近2周的用户行为信息,能够更加精准的预测用户行为。
第二篇分享的工作参考了2020年的paper《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》,这个工作也可以看做是2019年工作的进一步延伸。
因为memory network 的记忆是有限的,因此针对超长用户行为建模方面还是有一些提升空间的。针对这种情况作者提出了一种名为Search-based Interest model,即把整个CTR预测过程分成了2个stage:1 从超长的用户行为序列中检索出和当前预测item最相关的k个item候选列表;2 使用后续的DIN/DIEN等模型对筛选出的k个item行为列表进行建模与预测。
这里针对第一步采用不同的检索策略,可以分为hard-search和soft-search两种方式:
1 hard-search
S
i
g
n
(
C
i
=
C
a
)
Sign(C_i=C_a)
Sign(Ci=Ca) i代表了当前输入item,a代表了target item。这里hard的方式就是利用了电商场景商品的天然特性,即每一个商品会有一个“类别”标签,因此只要是和当前target item属于同一个类别的商品都会被筛选出来,这种看似粗暴的方式其实也是最终阿里妈妈在实际中的使用方式,具体实做中会构建
u
s
e
r
=
>
c
a
t
e
g
o
r
y
=
>
i
t
e
m
user=>category=>item
user=>category=>item这样的两级索引结构,直接快速的检索出和当前target item相关的item序列集合;
2 soft-search ( W b e i ) ⨀ ( W a e a ) T (W_be_i)\bigodot (W_ae_a)^T (Wbei)⨀(Waea)T 其中 W b , W a W_b,W_a Wb,Wa是参数矩阵, ⨀ \bigodot ⨀代表了内积操作,即通过内积的方式找出最相似的k个item。同时需要注意到的是,long-term和short-term用户的行为分布是不一致的,因此在soft-search部分加入了auxiliary loss辅助item embedding的生成,而soft-search对应部分的网络架构也是比较简单的,细节直接看下图就可以了,这里就不再赘述了。
整体2阶段的模型架构图如下所示:
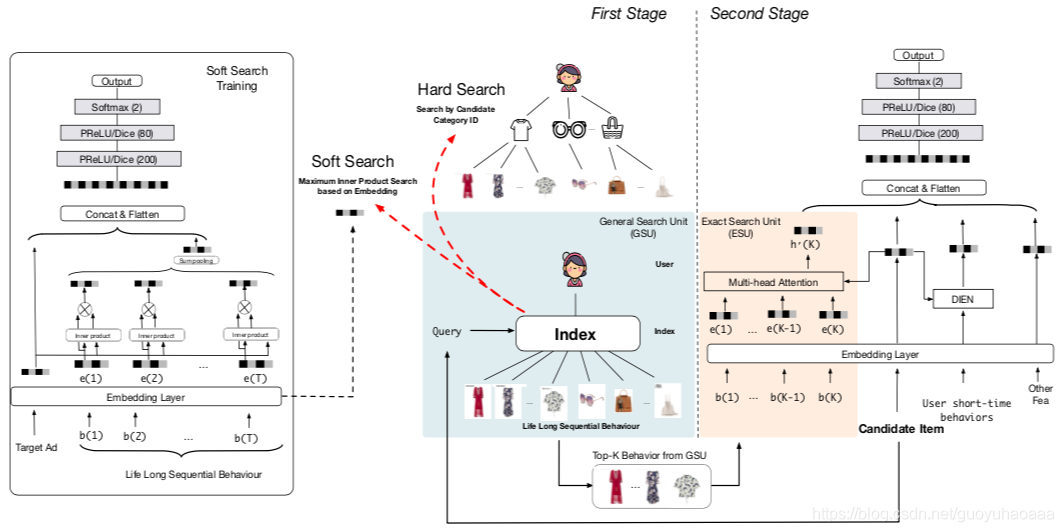
在通过first stage得到了压缩的用户行为序列之后,这些序列就会被输入到second stage对应的网络结构中去。从上图可以看到这部分使用了Exact Search Unit和DIEN对用户行为进行建模,DIEN在前面的博客已经讲过,这里就不再赘述了。这个Exact Search Unit其实是参考了multi-head attention的思想,具体细节如下:
针对用户每一个点击的时间间隔,引入了类似于位置向量的时间间隔向量序列:
E
t
=
[
e
1
t
;
e
2
t
.
.
.
.
.
.
;
e
K
t
]
E_t=[e_1^t;e_2^t......;e_K^t]
Et=[e1t;e2t......;eKt]
接下来是item的embedding序列:
E
∗
=
[
e
1
∗
;
e
2
∗
.
.
.
.
.
.
;
e
K
∗
]
E^*=[e_1^*;e_2^*......;e_K^*]
E∗=[e1∗;e2∗......;eK∗]
两者拼接得到
z
j
=
c
o
n
c
a
t
(
e
j
∗
,
e
j
t
)
z_j=concat(e_j^*,e_j^t)
zj=concat(ej∗,ejt)作为用户行为的最终表征。接下来使用类似的multi-head网络结构:
a
t
t
s
c
o
r
e
i
=
S
o
t
f
m
a
x
(
w
b
i
z
b
⨀
w
a
i
e
a
)
att_{score}^i=Sotfmax(w_{bi}z_b\bigodot w_{ai}e_a)
attscorei=Sotfmax(wbizb⨀waiea),其中
e
a
e_a
ea代表了target item的embedding表示。
h
e
a
d
i
=
a
t
t
s
c
o
r
e
i
z
b
head_i=att_{score}^iz_b
headi=attscoreizb
其中
i
i
i代表了第
i
i
i个head的参数,假设head的数量为q个,那么最终得到最终的形式为
f
i
n
a
l
=
c
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
.
.
h
e
a
d
q
)
final=concat(head_1,head_2,.....head_q)
final=concat(head1,head2,.....headq),最终将final向量输入到MLP网络中去得到最终的CTR预估结果。
最终模型的loss由first stage的GSU损失和second stage的ESU 损失组成,即
L
o
s
s
=
α
L
o
s
s
G
S
U
+
β
L
o
s
s
E
S
U
Loss=\alpha Loss_{GSU}+\beta Loss_{ESU}
Loss=αLossGSU+βLossESU。

















 3225
3225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









