






自从谷歌提出ViT、Open AI发布CLIP,视觉语言模型(VLM)便成为了研究热点,凭借跨模态处理和理解能力,以及零样本学习方法,为CV领域带来了重大革新,但由于大模型体量及泛化的限制,今年多家巨头开启了模型压缩技术的角逐,其中,知识蒸馏的教师-学生模型效果显著,一项基于提示学习的VLM蒸馏新方法,也被顶会CVPR'24关注收录!
为了帮助大家综合掌握,集VLM、知识蒸馏、提示工程一体的创新成果,研梦非凡于9月4日晚(周三),邀请了从事多模态大模型研究的王导师,独家详解来自南开&蚂蚁集团的CVPR'24研究《PromptKD:基于提示学习的VLM蒸馏新方法!》(AI前沿直播课NO.65),从VLM、Knowledge Distillation、Prompt Learning的知识回顾,到PromptSRC等顶会相关工作,重点讲解PromptKD方法原理、提示蒸馏过程及实验研究,1节课get前沿视野及论文idea!
👇🏻扫描二维码找助教0元预约直播课!

凡预约即可免费领取300篇精选论文(50篇VLM蒸馏+50篇提示工程+100篇多模态+100篇LLM/VLM)+文末还有算力等科研福利!
unsetunset直播课内容概览unsetunset
01 研究背景
关注的问题
本文主要贡献
无监督领域特定提示驱动知识蒸馏
预存储文本特征
教师-学生范式
广泛的实验验证
02 知识准备
视觉语言模型(VLM)
经典模型CLIP介绍
CLIP特点与架构
知识蒸馏(Knowledge Distillation)
什么是知识蒸馏?
为什么要知识蒸馏?
知识蒸馏的原理:Teacher、Student模型
知识蒸馏的分类:基于目标、基于特征的蒸馏
提示学习(Prompt Learning)
Prompt-Tuning的优缺点
Prompt-Tuning的代表性工作
👇🏻扫描二维码找助教0元预约直播课!

凡预约即可免费领取300篇精选论文(50篇VLM蒸馏+50篇提示工程+100篇多模态+100篇LLM/VLM)+文末还有算力等科研福利!
03 相关工作
PromptSRC(ICCV'23)
简介:自我调节的提示学习框架,解决了提示过拟合问题,以实现更好的泛化
框架原理
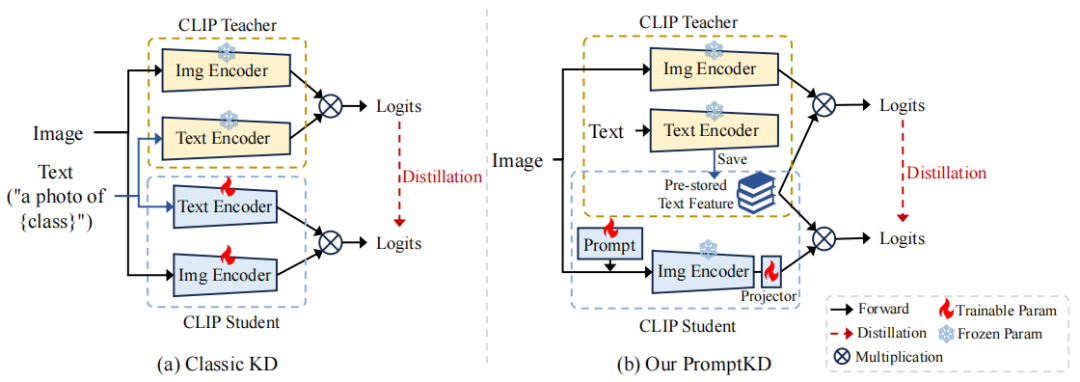
04 PromptKD详解(CVPR'24)
方法简介
两阶段训练流程
Prompt Learning
通过促进快速模仿来启动蒸馏过程,鼓励学生模型生成与教师模型相似的预测
伪代码
05 实验研究
实验一
实验指标、数据集等
实验设置
实验二
实验流程
消融实验
06 总结和展望
导师介绍
王导师
【学术背景】985硕出身,拥有丰富的深度学习研究、论文发表经验,多篇SCI论文、EI会议论文(一作)
【研究方向】大语言模型、视觉语言模型、多模态学习,以及自然语言处理、进化算法等
👇🏻扫描二维码找助教0元预约直播课!

凡预约即可免费领取300篇精选论文(50篇VLM蒸馏+50篇提示工程+100篇多模态+100篇LLM/VLM)+文末还有算力等科研福利!
unsetunset研梦非凡科研论文指导方案unsetunset
idea并不是直接拍脑门拍出来的,是一遍一遍实验、跑代码、改模型、思路修正的过程中产生的。研梦非凡1V1定制化论文指导,和研梦导师一起找idea,研梦导师指导实验,共同解决数据问题。授之以渔——搭建论文写作框架,增删改查,针对性实验指导!哪里薄弱补哪里!


<<< 左右滑动见更多 >>>
👇🏻扫描二维码咨询助教两种指导方案

unsetunset研梦非凡部分导师介绍unsetunset
研梦非凡导师团队,来自海外QStop200、国内华五、C9、985高校的教授/博士导师/博士后,以及世界500强公司算法工程师、国内外知名人工智能实验室研究员等。
这是一支实力强大的高学历导师团队,在计算机科学、机器学习、深度学习等领域,积累了丰富的科研经历,研究成果也发表在国际各大顶级会议和期刊上,在指导学员的过程中,全程秉持初心,坚持手把手个性化带教。包括但不限于以下导师~




<<< 左右滑动见更多 >>>
👇🏻扫码加助教为你匹配合适课题的大牛导师

unsetunset研梦非凡科研福利unsetunset
🌟90分钟人工智能零基础入门课免费领
🌟7小时科研论文写作系列课免费领
🌟年度会员福利价129元(原价2999)
🌟50小时3080GPU算力免费领
🌟百篇8月论文资料大合集免费领
👇🏻 扫码领取以上5重粉丝专属科研福利!



















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









