






一、回忆Farthest Point Sampling算法过程(建议详细看完)
我们选取一个点云,我们假设整个点集为![]() 一共有n个点,来进行算法的讲解。
一共有n个点,来进行算法的讲解。
- 随机在整个点集中选取一个点
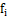 作为起始点,并且放入集合
作为起始点,并且放入集合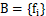 中,其中集合B为我们采样后的点集。
中,其中集合B为我们采样后的点集。 - 计算剩余n-1个点到
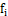 的距离,并且选择距离最大的点,假设为
的距离,并且选择距离最大的点,假设为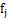 ,并将这个点写入集合
,并将这个点写入集合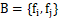 。
。 - 计算剩余n-2个点距离集合B中的点
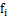 的距离,并选取最小的距离值假设为
的距离,并选取最小的距离值假设为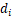 ,其中假设点为
,其中假设点为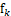 ,再计算n-2个点距离集合B中点
,再计算n-2个点距离集合B中点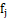 的距离,并选取最小的距离值假设为
的距离,并选取最小的距离值假设为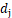 ,其中假设点为
,其中假设点为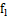 ,随后选取
,随后选取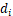 和
和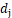 中比较大的值,假设
中比较大的值,假设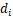 >
>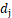 。则将
。则将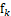 ,放入点集
,放入点集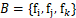 。
。 - 重复上面的第三步,直到选出我们需要的采样点个数时,终止运行。
建议、建议、建议:网上有很多博客已经写好这个算法,建议大家将算法原理对应代码过程,理解算法中的原理。
python:大家可以看一下这个博客中的代码实现:
二、重点:我们今天的重点,深度学习中FPS采样算法流程以及代码实现
其实,你会发现深度学习中运行FPS速度很快,但是我们按照算法流程编写代码运行以后,速度非常的慢,这是由于我们写的算法是每个点之间的计算,但是深度学习中是矩阵的运算,而且在GPU上运行,所以速度比较快。
下面图解,可能有些抽象,大家对照代码理解。
首先,我们可以整体看一下这个过程:
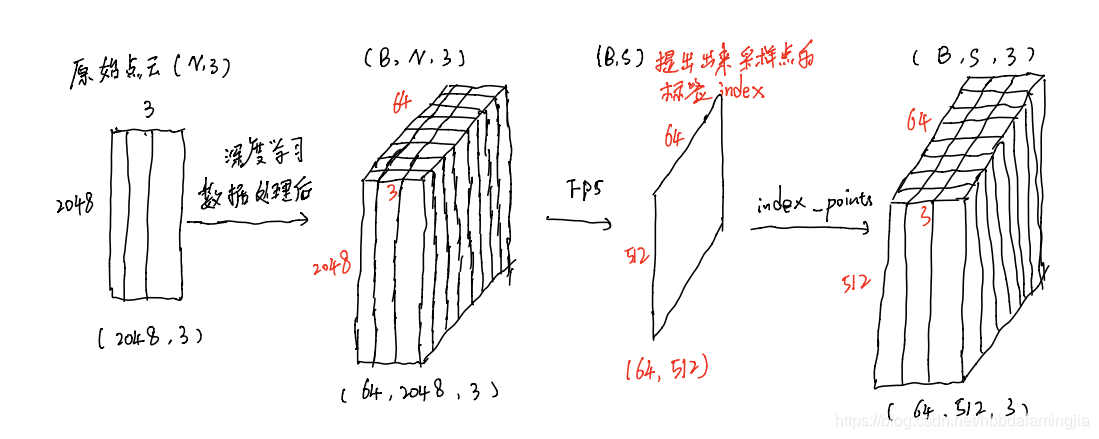
其次,我们简述FPS内部过程:定义一些常量(对照代码看名称)
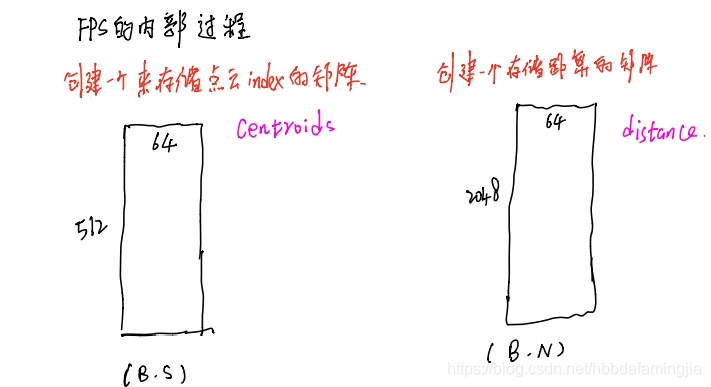
第一次循环:
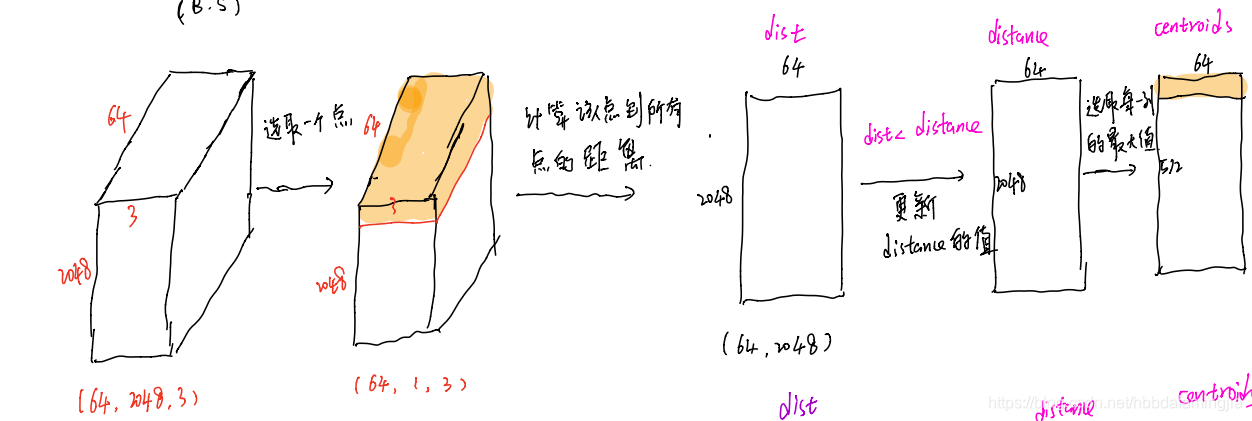
第二次循环:
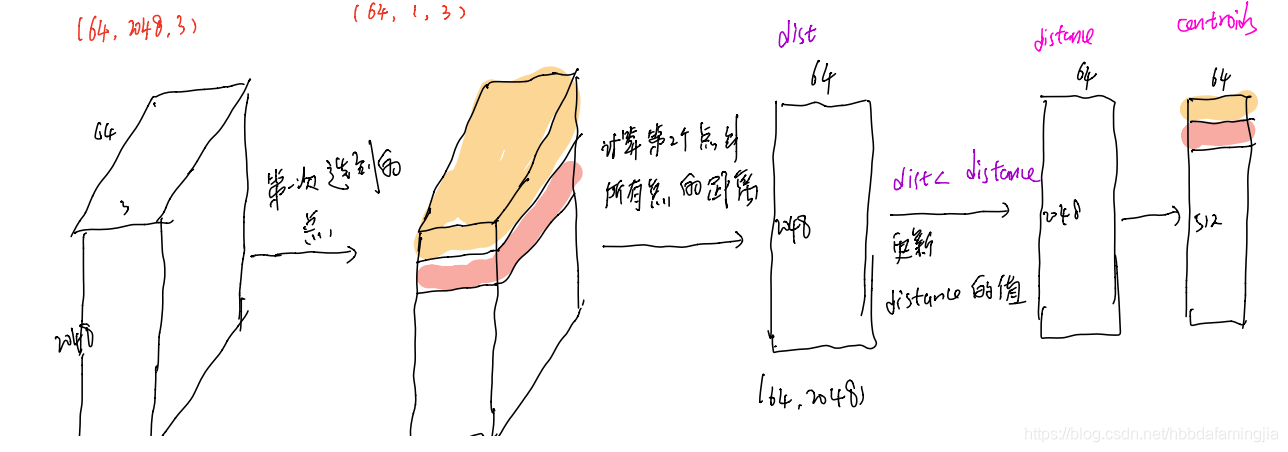
进行512次循环,即可得到采样点的index,维度为(64,512)。
主要是每次更新distance矩阵的值,然后求最远点,将最远点的index保存到centroids中。保证dist
以下代码为完整FPS的过程:
def farthest_point_sample(xyz, npoint, RAN=True):
"""
Input:
xyz: pointcloud data, [B, N, C]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device) #用来储存采样index
#[64,512]
distance = torch.ones(B, N).to(device) * 1e10 #用来储存距离
#[64,2048]
if RAN:
farthest = torch.randint(0, 1, (B,), dtype=torch.long).to(device) #表示上一次抽样的到点 [64]
else:
farthest = torch.randint(1, 2, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device) #一个1-B的整数 [64]
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3) #找出上一次采样的点
#[64,1,3]
dist = torch.sum((xyz - centroid) ** 2, -1)#[64,2048]
mask = dist < distance #更新每次最小距离
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1] #求取最大距离 [64]
print(farthest)
return centroids以下代码将FPS抽取出来的点云的index,转化为点云:
def index_points(points, idx):
"""
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, S]
Return:
new_points:, indexed points data, [B, S, C]
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape)
view_shape[1:] = [1] * (len(view_shape) - 1)
repeat_shape = list(idx.shape)
repeat_shape[0] = 1
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape)
new_points = points[batch_indices, idx, :]
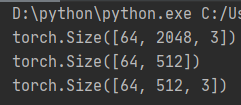
return new_points运行结果显示:可以从2048个点-->采样到512个点。

















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









