






 研究者提出MedMamba,一种结合卷积层和状态空间模型的新型方法,用于医学图像分类。实验结果显示在多个数据集上MedMamba表现优秀,可能成为医学图像分析的新基准。
研究者提出MedMamba,一种结合卷积层和状态空间模型的新型方法,用于医学图像分类。实验结果显示在多个数据集上MedMamba表现优秀,可能成为医学图像分析的新基准。
Mamba虽火,但把Mamba用好的工作真不多,而且医学影像的Mamba魔改工作也忒多了吧~真卷
【总结】MedMamba:一种用于医学图像分类的视觉Mamba,引入一种新的Conv-SSM模块,在多个医学数据集上性能表现出色!代码刚刚开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、AIGC工作~
MedMamba

MedMamba: Vision Mamba for Medical Image Classification
单位:广州医科大学, 广师大
代码:https://github.com/YubiaoYue/MedMamba
论文:https://arxiv.org/abs/2403.03849
CVPR 2024 论文和开源项目合集请戳—>https://github.com/amusi/CVPR2024-Papers-with-Code
医学图像分类是计算机视觉领域中一项非常基础和关键的任务。近年来,基于CNN和Transformer的模型被广泛用于对各种医学图像进行分类。不幸的是,CNN在长期建模能力方面的局限性使其无法有效地提取医学图像中的细粒度特征,而Transformer则受到其二次计算复杂性的阻碍。
最近的研究表明,以Mamba为代表的状态空间模型(SSM)可以有效地对长程相互作用进行建模,同时保持线性计算复杂性。
受此启发,我们提出了用于医学图像分类的视觉Mamba(MedMamba)。
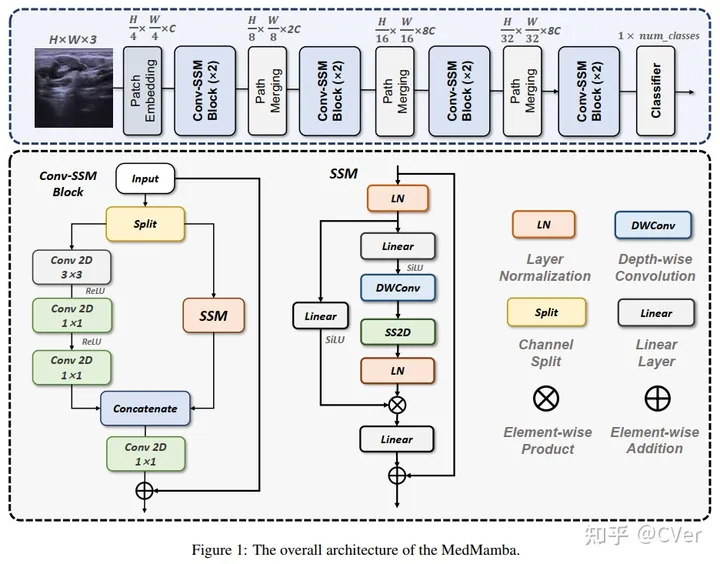
更具体地说,我们介绍了一种新的Conv-SSM模块,它将卷积层的局部特征提取能力与SSM捕获长程依赖性的能力相结合。
实验结果
为了证明MedMamba的潜力,我们使用三个具有不同成像技术的公开医学数据集(即Kvasir(内窥镜图像)、FETAL_PLANES_DB(超声图像)和Covid19肺炎正常胸部X射线(X射线图像))和两个自己建立的私人数据集进行了广泛的实验。实验结果表明,所提出的MedMamba在检测各种医学图像中的病变方面表现良好。据我们所知,这是第一款为医学图像分类量身定制的视觉Mamba。

这项工作的目的是为医学图像分类任务建立一个新的基线,并为未来在医学中开发更高效、更有效的基于SSM的人工智能算法和应用系统提供有价值的见解。
现在点击关注@CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~涨点神器、LLM、AIGC(图像/视频/3D生成)、多模态、医学影像、分类、检测、分割、跟踪、扩散、CNN、Transformer、NeRF、3DGS、low-level、自动驾驶、ReID、遥感等方向通通拿下!
CVPR 2024 论文和开源项目合集请戳—>
https://github.com/amusi/CVPR2024-Papers-with-Codegithub.com/amusi/CVPR2024-Papers-with-Code

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









