






 本文介绍了三种优先级仲裁算法:Fixed Priority、Round-Robin和Weighted Round-Robin。Fixed Priority基于固定优先级分配资源;Round-Robin解决了优先级高的请求可能导致低优先级请求被饿死的问题,通过轮转优先级实现公平;Weighted Round-Robin引入权重,允许高权重请求连续多次获取资源。文章详细阐述了每种算法的工作原理,并给出了Verilog实现的思考。
本文介绍了三种优先级仲裁算法:Fixed Priority、Round-Robin和Weighted Round-Robin。Fixed Priority基于固定优先级分配资源;Round-Robin解决了优先级高的请求可能导致低优先级请求被饿死的问题,通过轮转优先级实现公平;Weighted Round-Robin引入权重,允许高权重请求连续多次获取资源。文章详细阐述了每种算法的工作原理,并给出了Verilog实现的思考。
1. Fixed Priority Arbitrary
固定优先级就是指每个req的优先级是不变的,即优先级高的先被处理,优先级低的必须是在没有更高优先级的req的时候才会被处理。所以转化为数学模型就是找出req序列中第一个为1的位置,然后将其转换为onehot。
例如:
req[3:0] = 4'b1100 ==> grant[3:0] = 4'b0100
req[3:0] = 4'b1010 ==> grant[3:0] = 4'b0010
要做的第一步就是先根据req构造出一个mask,该mask会将第一个非0bit以上的值掩盖。例如,
req[3:0] = 4'b1100 ==> mask[3:0] = 4'b1000
req[3:0] = 4'b1010 ==> mask[3:0] = 4'b1100
可以通过假设req[0]为1,那么mask[0] = 0,mask[3:1] = req[2:0] | mask[2:0]。
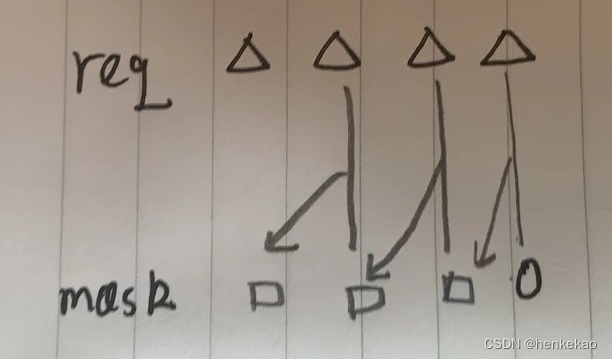
得到mask后,就能够使用mask将req变为onehot的grant,即grant[3:0] = req[3:0] & (~mask[3:0])。
module fixed_priorty_arb (
//output
gnt,
//input
req);
parameter REQ_WIDTH = 16;
input [REQ_WIDTH-1:0] req;
output[REQ_WIDTH-1:0] gnt;
wire [REQ_WIDTH-1:0] req;
wire [REQ_WIDTH-1:0] mask;
wire [REQ_WIDTH-1:0] gnt;
assign mask[0] = 1'b0;
assign mask[REQ_WIDTH-1:1] = req[REQ_WIDTH-2:0] | mask[REQ_WIDTH-2:0];
assign gnt[REQ_WIDTH-1:0] = req[REQ_WIDTH-1:0] & (~pre_req[REQ_WIDTH-1:0]);
endmodule2. Round-Robin Priority Arbitrary
前面所描述的Fixed Priority Arbitrary有个缺点,如果优先级高的一直来req,那么优先级低的req将会被饿死,一直不能被选中执行。因此,为了更加公平,可以采用Round-Robin仲裁算法。
该算法每个req的优先级并不固定,会根据前一次的仲裁结果动态调整各个req的优先级。具体描述如下,同样假设有有四个req(DCBA),规定四个req的初始优先级从左到右依次变高,即A的优先级最高,D的优先级最低。Round-Robin规定,当前仲裁胜出的req的优先级在下一轮仲裁中变为最低,胜出req相邻左边的优先级变为最高。即假设在第一次仲裁时,req为4'b0110,那么B在该次仲裁中胜出,那么下一轮仲裁时,四个req的优先级顺序变为BADC(注意这里是顺序轮转,A的优先级会变得比D、C低)。
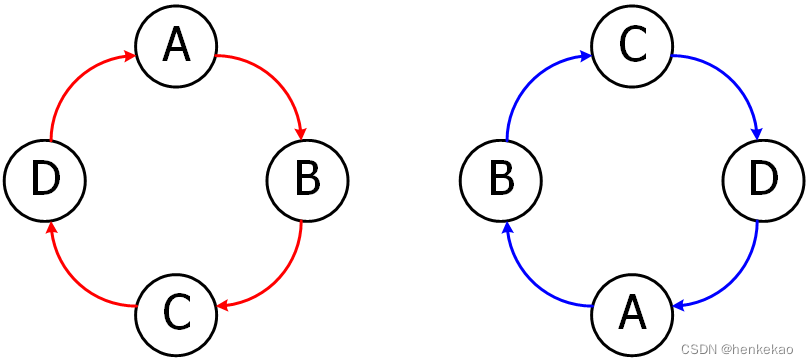
那如何将Round-Robin转换为相应的数学模型呢?本着有轮子就不新造的理念,可以试着将Fixed Priority Arbitrary升级为Round-Robin。观察可以发现,第一次的仲裁其实是一次优先级顺序为DCBA的Fixed Priority Arbitrary,第二次仲裁是将原本优先级顺序为DCBA的变为BADC的一次Fixed Priority Arbitrary。为了便于理解,进一步将第二次仲裁拆分为DCBA和DC00两个同时执行的Fixed Priority Arbitrary,如下图所示。
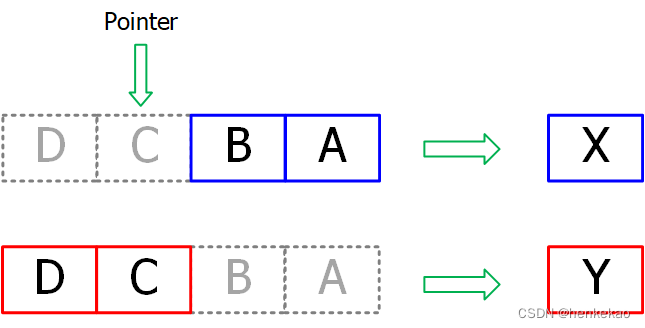
两个仲裁分布得到了X和Y,X和Y之间谁最终胜出就很简单了,因为在本轮仲裁中,DC的优先级高于BA,所以只要在DC中有相应的req,则Y胜出,反之则X胜出。这里提出pointer的概念,pointer所指的位置表示优先级最高,pointer的更新是基于上一次仲裁结果进行更新。以pointer为分界点做两个Fixed Priority Arbitrary,再根据Pointer所指位置以及左边是否有req决定最终胜出的req。完整示意图如下,
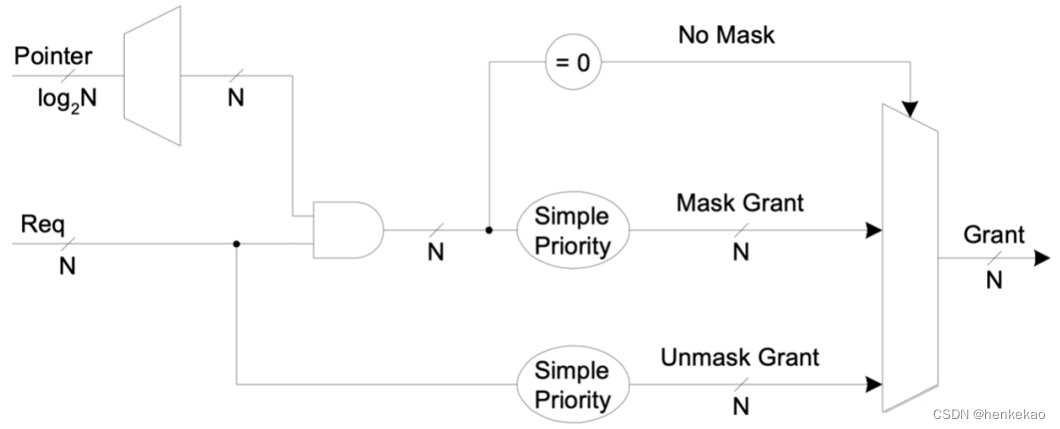
那如何得到pointer呢?其实在Fixed Priority Arbitrary中,就已经得到了该Pointer。在Fixed Priority Arbitrary中计算grant使用的mask就是这里需要的Pointer。因为mask是根据req从右到左第一个为1 位置,计算得到的左侧为全1,右侧为全0的序列。利用该mask将DCBA变为DC00序列,再利用Fixed Priority Arbitrary计算得到Y。再根据masked req是否为全0来决定选择那个Fixed Priority Arbitrary的计算结果。
module rr_arb (
//output
gnt,
//input
clk, rst_n, req);
parameter REQ_WIDTH = 16;
input clk;
input rst_n;
input [REQ_WIDTH-1:0] req;
output[REQ_WIDTH-1:0] gnt;
wire [REQ_WIDTH-1:0] req;
wire [REQ_WIDTH-1:0] mask_pre;
wire [REQ_WIDTH-1:0] gnt;
reg [REQ_WIDTH-1:0] mask;
// Fixed priorty arb of unmasked req
assign mask_f0[0] = 1'b0;
assign mask_f0[REQ_WIDTH-1:1] = req[REQ_WIDTH-2:0] | mask_f0[REQ_WIDTH-2:0];
assign gnt_unmasked[REQ_WIDTH-1:0] = req[REQ_WIDTH-1:0] & (~mask_f0[REQ_WIDTH-1:0]);
// Fixed priorty arb of masked req
assign mask_req[REQ_WIDTH-1:0] = req[REQ_WIDTH-1:0] & mask_reg[REQ_WIDTH-1:0];
assign mask_f1[0] = 1'b0;
assign mask_f1[REQ_WIDTH-1:1] = mask_req[REQ_WIDTH-2:0] | mask_f1[REQ_WIDTH-2:0];
assign gnt_masked[REQ_WIDTH-1:0] = mask_req[REQ_WIDTH-1:0] & (~mask_f0[REQ_WIDTH-1:0]);
// gnt
assign no_req_masked = ~(| mask_req[REQ_WIDTH-1:0]);
assign gnt[REQ_WIDTH-1:0] = no_req_masked ? gnt_unmasked[REQ_WIDTH-1:0] :
gnt_masked[REQ_WIDTH-1:0];
// assign gnt[REQ_WIDTH-1:0] = ({REQ_WIDTH{no_req_masked}} & gnt_unmasked[REQ_WIDTH-1:0]) |
gnt_masked[REQ_WIDTH-1:0];
// update mask_reg
assign rr_en = (|req[REQ_WIDTH-1:0]);
always@(posedge clk or negedge rst_n) begin
if (~rst_n)
mask_reg[REQ_WIDTH-1:0] <= {REQ_WIDTH{1'b0}};
else if(rr_en) begin
if (no_req_masked)
mask_reg[REQ_WIDTH-1:0] <= mask_f0[REQ_WIDTH-1:0];
else
mask_reg[REQ_WIDTH-1:0] <= mask_f1[REQ_WIDTH-1:0];
end
end
endmodule3. Weighted Round-Robin Priority Arbitrary
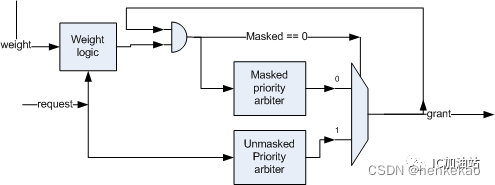
在Round-Robin Priority Arbitrary中,当一个Req被granted之后,用于记录优先级状态的Pointer就会立即更新,但Weighted Round-Robin Priority Arbitrary并不会这么做。如果当前Req的权重大,且该Req连续请求grant时,那么该Req最多可连续被granted N次(N取决于权重大小),在这之后Pointer才会被更新。也就是说Weighted Round-Robin Priority Arbitrary相对于Round-Robin Priority Arbitrary而言,除更新Pointer的规则发生变化外,其余逻辑完全相同。这里需要注意以下几点:
- 每个Req都有相应的counter寄存器记录其被连续grant的次数,该寄存器的复位值应动态可配置;
- 该counter寄存器在对应Req被grant一次之后会减1;
- 如果Req连续请求grant,那么当counter减至0后,该Req的优先级变为最低,需更新Pointer;
- 如果Req没有连续请求grant,那么Pointer就会根据下次实际Req的情况进行更新,而不会死等该Req的counter减至0;
module rr_arb (
//output
gnt,
//input
clk, rst_n, req, wt_cfg);
parameter REQ_WIDTH = 16;
parameter WT_WIDTH = 5;
input clk;
input rst_n;
input [REQ_WIDTH-1:0] req;
input [REQ_WIDTH*WT_WIDTH-1:0] wt_cfg;
output[REQ_WIDTH-1:0] gnt;
wire [REQ_WIDTH-1:0] req;
wire [REQ_WIDTH-1:0] mask_pre;
wire [REQ_WIDTH-1:0] gnt;
wire [REQ_WIDTH*WT_WIDTH-1:0] wt_cfg;
reg [REQ_WIDTH-1:0] mask;
reg [REQ_WIDTH*WT_WIDTH-1:0] wt_cnt;
// Fixed priorty arb of unmasked req
assign mask_f0[0] = 1'b0;
assign mask_f0[REQ_WIDTH-1:1] = req[REQ_WIDTH-2:0] | mask_f0[REQ_WIDTH-2:0];
assign gnt_unmasked[REQ_WIDTH-1:0] = req[REQ_WIDTH-1:0] & (~mask_f0[REQ_WIDTH-1:0]);
// Fixed priorty arb of masked req
genvar i;
generate
for (i = 0; i < REQ_WIDTH; i = i + 1;) begin
mask_wt[i] = wt_cnt[(i*WT_WIDTH-1)+:WT_WIDTH] == {WT_WIDTH{1'b0}};
end
endgenerate
assign mask_req[REQ_WIDTH-1:0] = req[REQ_WIDTH-1:0] & mask_reg[REQ_WIDTH-1:0] & mask_wt[REQ_WIDTH-1:0];
assign mask_f1[0] = 1'b0;
assign mask_f1[REQ_WIDTH-1:1] = mask_req[REQ_WIDTH-2:0] | mask_f1[REQ_WIDTH-2:0];
assign gnt_masked[REQ_WIDTH-1:0] = mask_req[REQ_WIDTH-1:0] & (~mask_f0[REQ_WIDTH-1:0]);
// gnt
assign no_req_masked = ~(| mask_req[REQ_WIDTH-1:0]);
assign gnt[REQ_WIDTH-1:0] = no_req_masked ? gnt_unmasked[REQ_WIDTH-1:0] :
gnt_masked[REQ_WIDTH-1:0];
// update wt_cnt
genvar i;
generate
for (i = 0; i < REQ_WIDTH; i = i + 1;) begin
wt_cnt_max = wt_cnt[(i*WT_WIDTH-1)+:WT_WIDTH] == wt_cfg[(i*WT_WIDTH-1)+:WT_WIDTH];
wt_cnt_update0[i] = (mask_wt[i] | (~rr_en)| (~gnt[i])) & (~wt_cnt_max);
wt_cnt_update1[i] = (~mask_wt[i]) & gnt[i];
always@(posedge clk or negedge rst_n) begin
if (~rst_n)
wt_cnt[(i*WT_WIDTH-1)+:WT_WIDTH] <= wt_cfg[(i*WT_WIDTH-1)+:WT_WIDTH];
else if (wt_cnt_update0[i])
wt_cnt[(i*WT_WIDTH-1)+:WT_WIDTH] <= wt_cfg[(i*WT_WIDTH-1)+:WT_WIDTH];
else if (wt_cnt_update1[i])
wt_cnt[(i*WT_WIDTH-1)+:WT_WIDTH] <= wt_cnt[(i*WT_WIDTH-1)+:WT_WIDTH] - 1'b1;
end
end
endgenerate
// update mask_reg
assign rr_en = (|req[REQ_WIDTH-1:0]);
assign serial_req = ~(|(mask_reg[REQ_WIDTH-1:0] & {1'b0, gnt[REQ_WIDTH-1:1]}));
//将gnt右移1bit,如果是连续req,那么gnt为onehot中为1的bit将和mask reg中的0对齐,如果不是连续req,那么那么gnt为onehot中为1的bit一定和mask reg中的1对齐
assign update_mask_reg = rr_en & (no_req_masked | (~serial_req));
always@(posedge clk or negedge rst_n) begin
if (~rst_n)
mask_reg[REQ_WIDTH-1:0] <= {REQ_WIDTH{1'b0}};
else if(update_mask_reg) begin
if (no_req_masked)
mask_reg[REQ_WIDTH-1:0] <= mask_f0[REQ_WIDTH-1:0];
else
mask_reg[REQ_WIDTH-1:0] <= mask_f1[REQ_WIDTH-1:0];
end
end
endmodule参考文献:


















 2507
2507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











