







分类目录:《机器学习中的数学》总目录
相关文章:
· 常用概率分布(一):伯努利分布(Bernoulli分布)
· 常用概率分布(二):范畴分布(Multinoulli分布)
· 常用概率分布(三):二项分布(Binomial分布)
· 常用概率分布(四):均匀分布(Uniform分布)
· 常用概率分布(五):高斯分布(Gaussian分布)/正态分布(Normal分布)
· 常用概率分布(六):指数分布(Exponential分布)
· 常用概率分布(七): 拉普拉斯分布(Laplace分布)
· 常用概率分布(八):狄拉克分布(Dirac分布)
· 常用概率分布(九):经验分布(Empirical分布)
· 常用概率分布(十):贝塔分布(Beta分布)
· 常用概率分布(十一):狄利克雷分布(Dirichlet分布)
· 常用概率分布(十二):逻辑斯谛分布(Logistic 分布)
均匀分布(Uniform分布)是关于定义在区间
[
a
,
b
]
(
a
<
b
)
[a, b](a<b)
[a,b](a<b)上连续变量的简单概率分布,其概率密度函数如下图所示:
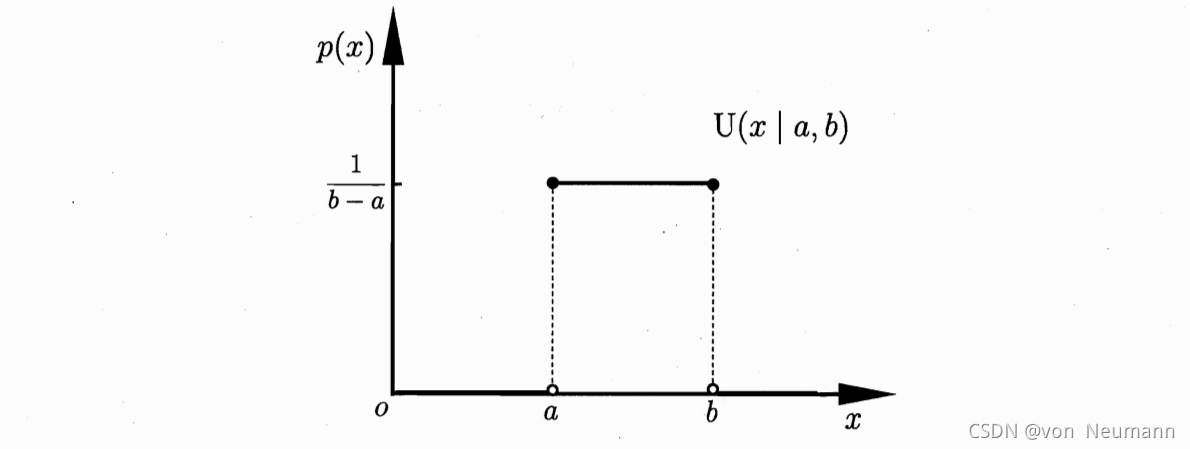
它的概率密度函数为:
U
(
x
∣
a
,
b
)
=
1
b
−
a
U(x|a,b)=\frac{1}{b-a}
U(x∣a,b)=b−a1
它具有如下的一些性质:
- E [ x ] = a + b 2 E[x]=\frac{a+b}{2} E[x]=2a+b
- V a r ( x ) = ( b − a ) 2 12 Var(x)=\frac{(b-a)^2}{12} Var(x)=12(b−a)2



















 5563
5563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











