







平台:vivado2017.4
芯片:xc7k325tfbg676-2 (active)
关于PCIE的开发学习。使用xilinx官方提供的IP核。
第一种方式是基于PCIE_PIO的分析,可以实现简单的读写功能。使用7 Series PCI Express v3.3 IP core 的设计,使用方法我已经放在上一个博客之中。
(294条消息) PCIE实现PIO模式寄存器读写调试记录_hy_520520的博客-CSDN博客_pcie接口调试
第二种方式是使用XAPP1052,其作为最古老的一种开发方式,可以让使用者接触最底层的代码,了解PCIE传输方式。也是学习PCIE DMA的最方便的途径。
本博客大量关于PCIE的基础知识均来自于《PCI+EXPRESS体系结构导读》王齐编著。
目录
-
关于PCIE的基础知识
不同于PCI,PCIE采用了高速差分总线,并且采用端到端的连接方式。并且支持多种数据路由方式,基于多通路的数据传递方式,和基于报文的数据传送方式。我们这里要学习的XAPP1052就是基于TLP报文的传输方式。
-
PCIE的传输速度
PCIE的链路可以由多个lane组成,目前链路可以支持1、2、4、8、12、16、32个lane,即x1、x2、x4、x8、x12、x16、x32。每一个lane上使用的总线频率与PCIE总线使用的版本有关系。PCIE总线规范与总线频率和编码的关系。
| PCIE总线规范 | 总线频率/GHZ | 传输速度 | 单lane的峰值带宽(x1) | 双lane的峰值带宽(x2) | 编码方式 |
| 1.x | 2.5GHZ | 2.5GT/S | 250 MB/S | 500 MB/S | 8/10b |
| 2.x | 5GHZ | 5GT/S | 500 MB/S | 1 GB/S | 8/10b |
| 3.x | 8GHZ | 8GT/S | 984.6 MB/S | 1.969 GB/S | 128/130b |
| 4.X | 16GHZ | 16GT/S | 1.969 GB/S | 3.938 GB/S | 128/130b |
| 5.x | 32GHZ | 32GT/S or 25GT/S | 3.9 GB/S or 3.08GB/S | 7.8 GB/S or 6.16GB/S | 128/130b |
GT/S:千兆传输/秒,即每秒内传输的次数。
Gbps:千兆位/秒。
在PCIE总线中使用GT/S计算PCIE的峰值带宽,也就是最大吞吐量。
吞吐量=传送速率*线路编码方案。
PCIE1.x协议传送速率为2.5GT/S。每一条lane上每秒钟传输2.5G个bits。采用的编码方案为8/10b。即每10个bits中就有2bit是无用信息。所以PCIE1.x单lane的峰值带宽为:2.5GT/S*8/10=2Gbps=250MB/S
同理可以计算:
PCIE2.x单lane峰值带宽为:5GT/S*8/10=4Gbps=500MB/S
PCIE3.x单lane峰值带宽为:8GT/S*128/130=7.88Gbps=984.6MB/S
PCIE4.x单lane峰值带宽为:16GT/S*128/130=15.76Gbps=1.969GB/S
-
PCIE的结构层次
PCIE总线中,数据报文在接收和发送的过程中,需要通过多个层次,包括事物层、数据链路层和物理层。
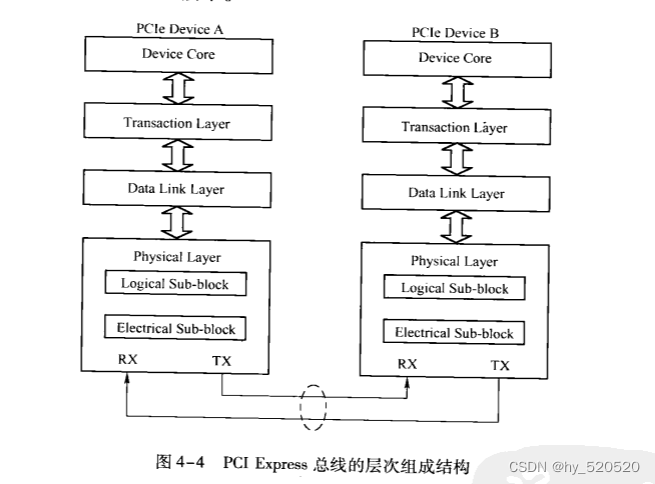
-
事物层
其中事物层,事物层和核心相连接。接收来自核心层的数据,并封装为TLP,发向数据链路层。并且可以从数据链路层中接收数据报文,然后转发到PCIE设备的核心层。事务层的另外一个重要工作是处理PCIE总线的“序”。在PCIE总线中,事物层传递报文时可以乱序。
-
数据链路层
保证来自事物层的报文可以可靠,完整的发送到接收端的数据链路层。
-
物理层
物理层是PCIE总线的最底层,将PCIE设备连接在一起。为PCIE设备间的数据通信提供传送介质,保证数据传输的物理环境。
-
PCIE体系结构组成部件
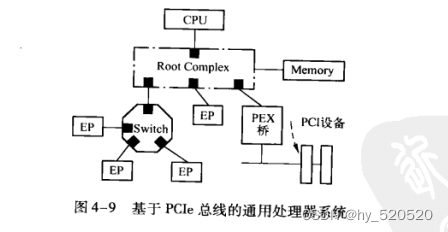
PCIE总线最为处理器系统的局部总线,其作用与PCI总线类似。主要目的是为了连接处理器系统中的外部设备。当然PCIE总线也可以连接其他处理器系统。在大多数处理器系统中,都使用了RC、switch和PCIE - to - PCI桥这些模块连接PCIE和PCI设备。在PCIE总线中,基于PCIE总线的设备,也称为EP(Endpoint)
-
RC的组成结构
RC是PCIE体系结构的一个重要组成部件,也是一个比较混乱的概念。根据知乎上的解释,RC的主要作用是将存储域地址空间转换为PCIE域地址空间,同时还要完成CPU端FSB总线协议和PCIE协议的转换。RC统管从该点扩展出来的所有PCIE总线。可以理解为CPU和PCIE之间的桥。RC负责根据CPU的访问事务产生对应报文,发送给下游设备,同时解析下游设备上报的TLP报文。并通知CPU。
-
Switch
PCIE总线体系结构中,PCIE总线使用Switch进行链路拓展。一个Switch通过拓展后可以连接多个EP设备。Switch解决了多个设备之间TLP优先级问题(QoS问题)。防止了PCIE链路拥挤。在多个TLP到达时,保证优先级高的报文首先通过。保证了在链路带宽有限的情况下,提高效率。
-
PCIE - to - PCI/PCI - X桥片
PCIE桥片具有两个作用。
- 将PCIE总线转换为PCI总线。
- 将PCI总线转换为PCIE总线。
PCIE桥一端和PCIE总线相连接。另外一端可以和多条PCI总线连接。
-
PCIE的拓展配置空间
我们知道PCI设备的基本配置空间由64个字节组成。其地址范围为0x00-0x3F。此外PCI/PCI-X和PCIE设备拓展了0x40-0xFF这段配置空间。主要用于存放一些与MSI、MSI-X中断机制和电源管理相关的capability结构。PCIE还支持拓展0x100-0xFFF这些配置空间。存放一些PCIE设备独有的capability结构。
这里我们注意看一下和后续解析TLP有关的capability结构。
-
PCI Express capability结构
该寄存器存放与PCIE设备相关的一些参数,包括版本信息,端口描述等。
-
Device capability结构
该寄存器存[2:0]字段为“Max_Payload_Size_supported”该字段存放该设备支持的Max_Payload_Size大小只读。
| Bit[2:0] | 支持的Max_Payload_Size |
| 0b000 | 128B |
| 0b001 | 256B |
| 0b010 | 512B |
| 0b011 | 1024B |
| 0b100 | 2048B |
| 0b101 | 4096B |
“Max_Payload_Size_supported”字段决定了一个TLP报文可能使用的最大有效负载。
“Max_Payload_Size_supported”字段仅表示该PCIE设备允许使用的Max_Payload_Size参数。在Device capability寄存器中,还有一个Max_Payload_Size参数,由软件决定,表示实际使用的Max_Payload_Size参数大小。
“Max_Payload_Size_supported”表示PCIE设备能够支持的最大Payload大小。Max_Payload_Size是链路两端PCIE协商,确定实际使用值。
其他部分详情见《PCI+EXPRESS体系结构导读》4.3节
-
关于PCIE的事物层
上面也说到,PCIE事物层是接收核心层的数据请求,并转换为PCIE总线事务,这些总线事务在TLP头中定义。包括诸如,存储器读写事务,IO读写事务,配置读写事务等等。这里我们主要关注存储器读写事务,和后续的1052部分有很大的关系。
-
关于TLP的格式
处理器或者其他PCIE设备访问PCIE设备时,所发送的数据首先通过事物层封装为TLP。
| TLP Prefix (Optional) | TLP Prefix (Optional) | TLP Head | Data Payload | TLP Digest (Optional) |
TLP Prefix :为了拓展TLP头。在PCIEV2.1规范中新增。
TLP Head :TLP头。又3或者4个DW组成。第一个双字保存通用TLP头,其他字段存放于通用TLP头的Type字段相关。
Data Payload :数据的有效负载。长度可变,0-1024DW。
TLP Digest :是否需要根据TLP 头决定。
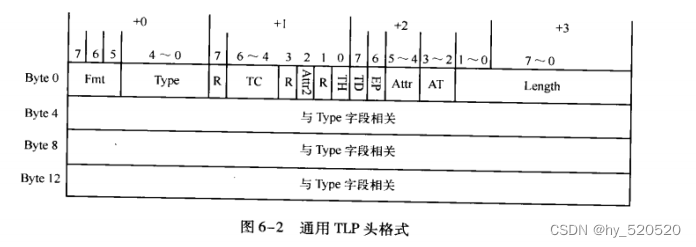
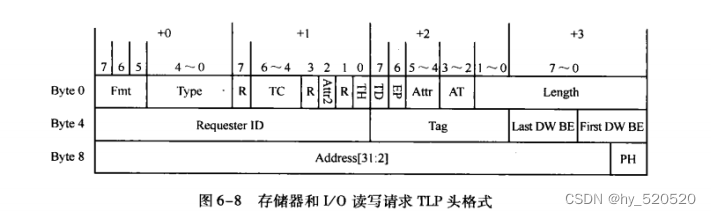
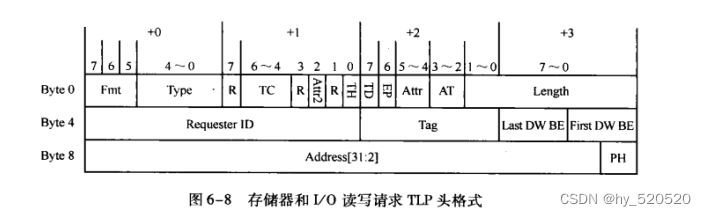
- FMT,TYPE:确定当前TLP使用的总线事务。3 OR 4 DW,TLP中的有效负载。所有的读请求TLP都不带数据,而写请求TLP带数据。其他TLP可能有数据也可能无数据,如完成报文。

TYPE为TLP的类型。
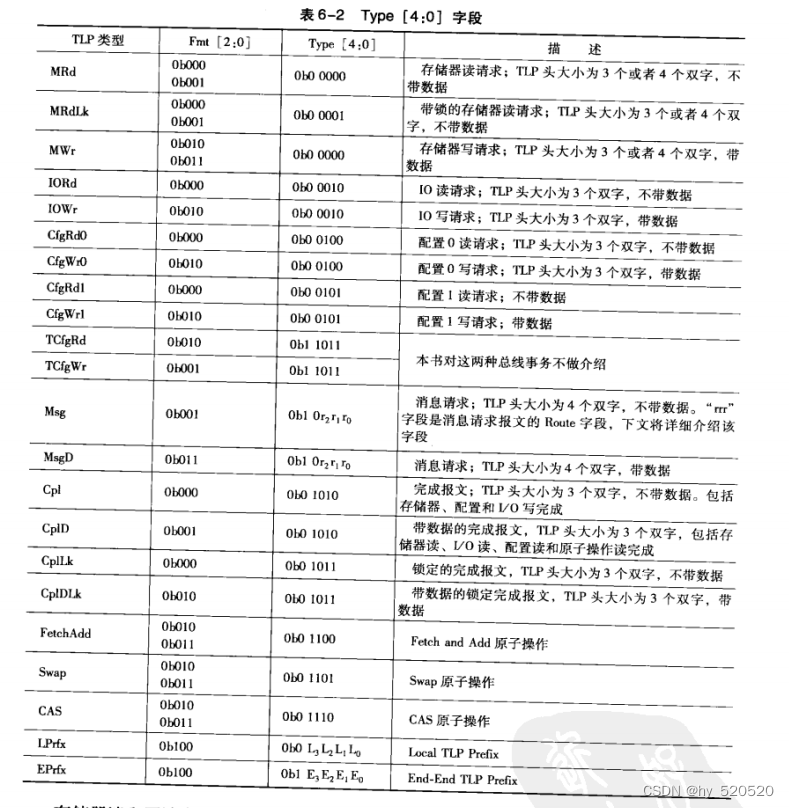
使用FMT加TYPE就可以确定当前TLP的类型。
其中存储器写TLP使用Posted方式传输,其他总线事务使用Non_Posted方式。当PCIE设备进行存储器读,IO读写或者配置读写请求时。首先向目标设备发送数据读写请求TLP,当目标设备收到这些读写请求TLP后,将数据和完成信息通过完成报文(Cpl或CPLD)发送给源设备。
其中存储器读,IO读和配置读需要使用CPLD报文,因为目标设备需要将数据传递给源设备。而IO写和配置写需要使用CPL报文,因为目标设备不需要将任何数据传递给源设备,但是要通知源设备,写操作已经完成,数据已经成功传递给目标设备。
- TC:传输类型
- Attr字段:表示TLP的序。详情见《PCI+EXPRESS体系结构导读》6.1.3
- Length:描述有效负载(Data Payload)大小。
-
关于存储器、IO配置读写请求TLP

存储器写请求TLP使用Posted总线事务。PCIE主设备仅仅使用存储器写请求TLP既可完成存储器写操作,主设备不需要目标设备的回应报文。
存储器读请求,PCIE主设备,RC或者EP,访问目标的存储器空间时,使用Non_Posted总线事务向目标设备发出存储器读请求TLP,目标设备收到TLP后,使用存储器读完成TLP,主动向主设备传递数据。主设备收到目标设备的存储器度完成TLP后,将完成一次存储器读操作。
- Length
存储器读请求TLP中不包含Data Payload,这里为需要从目标设备数据区域读取的数据长度。
存储器写请求TLP中,表示当前报文的Data Payload大小。
- DW BE
字节使能,一般不使用。代表数据的位有效。
- Requester ID
生成这个TLP报文的PCIE设备总信号(Bus number),设备号(Device Number)和功能号(Function Number)。对于存储器写请求TLP,这个字段不是必须的。对于存储器读请求,IO和配置读写请求TLP,必须使用Requester ID字段。
存储器,IO读请求TLP中包含有Requester ID和TAG字段。在PCIE总线中Requester ID和Tag字段合称为Transaction ID。
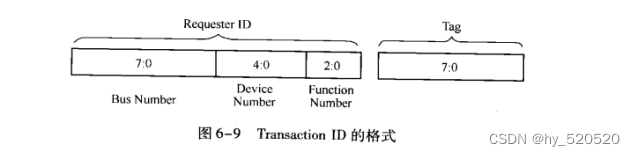
注意这里的这个Transaction ID。源设备发送Non_Posted数据请求后,在没有获得全部完成报文之前。不能释放Transaction ID。在同一个PCIE设备发送的TLP中,其Requester ID是相同的。设计者需要管理的资源是Tag字段。在后续的DMA传输的过程中,Tag字段使我们解决DMA乱序问题的重要手段。
-
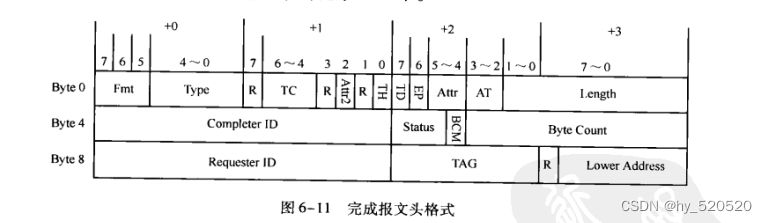
完成报文
在PCIE总线中,有以下几类数据请求需要收到完成报文之后,才能完成整个数据传送过程。
所有的数据读请求:存储器、IO读请求,配置读请求和原子操作请求
所有的Non_Posted数据写请求:IO读请求,和配置写请求。
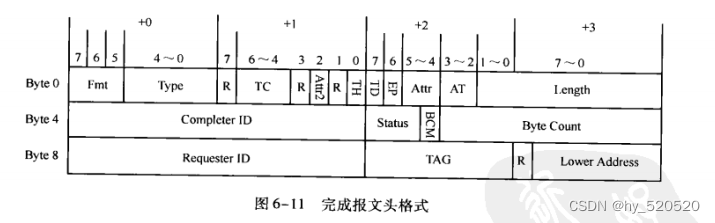
完成报文一次最多能够传送的报文大小不能超过Max_Payload_Size参数。在多数处理器中,完成报文中包含的数据在一个Cache行之内,完成报文使用RCB参数来处理数据对界,RCB参数的大小与处理器系统的Cache行长度和DDR_SDRAM的一次突发传送长度相关。
-
Byte Count字段
记录源设备还需要从目标设备中获得多少字节的数据就能完成全部数据传递。当前TLP中有效负载也被Byte Count统计在内。如一个源设备向目标设备“读取128B的存储器读请求TLP”而且目标设备收到这个读请求TLP后,可能使用两个存储器读完成TLP传递数据。第一个存储器度完成TLP的有效数据为64B,而Byte Count字段为128。第二个存储器读完成TLP中的有效数据为64B,而Byte Count字段也是64。当数据请求端接收完毕第一个存储器度完成TLP后,发现还有64B的数据没有接收完毕。必须等待下一个存储器读完成TLP。等待数据请求端收齐所有数据后,才能结束整个存储器读请求。从而释放这个存储器读过程使用的Tag资源。
-
TLP中与数据负载相关的参数
在PCIE总线中,有些含有TLP的Data Payload,如存储器写请求,存储器读完成TLP等。在PCIE总线中。TLP含有的Data payload大小与Max_Payload_Size、Max_Read_Payload_Size和RCB参数。
在PCIE总线中,有些含有TLP的Data Payload,如存储器写请求,存储器读完成TLP等。在PCIE总线中。TLP含有的Data payload大小与Max_Payload_Size、Max_Read_Payload_Size和RCB参数。
-
Max_Payload_Size
PCIE设备包含有Max_Payload_Size、Max_Payload_Size_Support两个参数。
Max_Payload_Size_Support参数存放一个PCIE设备中TLP有效负载的最大值,由硬件决定。Max_Payload_Size参数是存放PCIE设备实际使用TLP有效负载的最大值。由链路两端的设备协商决定。是PCIE设备进行数据传送时时基使用的参数。
在PCIE设备发送数据报文时,使用Max_Payload_Size参数决定TLP的最大有效负载。当PCIE设备的传送的数据大小超过Max_Payload_Size时,这段数据将分割为多个TLP进行发送。当PCIE设备接收TLP时,该TLP的最大有效负载也不能超过Max_Payload_Size参数。超过则认为该TLP非法。
RC或者EP在发送存储器读完成TLP时,这个存储器读完成TLP的最大Payload也不能超过Max_Payload_Size参数,如果超过该参数,PCIE设备需要发送多个读完成报文。值的注意的是,这些读完成报文需要满足RCB参数的要求。
-
Max_Read_Request_Size
规定了PCIE设备一次能从目标设备读取多少数据。该参数在Device Control寄存器中定义。该参数与存储器读请求TLP的Length字段相关。其中Length字段不能大于Max_Read_Request_Size。注意,Max_Read_Request_Size和Max_Payload_Size参数之间没有直接联系。Max_Payload_Size参数仅仅与存储器写请求和存储器读完成报文相关。
PCIE总线规定存储器读请求,其读取的数据长度不能超过Max_Read_Request_Size参数。即存储器读TLP中的Length字段不能大于这个参数。如果大于这个参数,该PCIE需要向目标设备发送多个存储器读请求TLP。
如果一个EP的Max_Read_Request_Size参数被设置为4KB。而且这个EP没发出一个4KB大小的存储器读请求时。EP都需要准备一个4KB大小的缓冲。这对于绝大多数EP都是一个相当苛刻的条件。
-
RCB参数
RCB位于Link_Control寄存器中。RCB位决定了RCB参数的值。在PCIE中,RCB参数的大小为64B或者128B。RC的RCB参数缺省值为64B,其他PCIE设备RCB缺省值为128B。PCIE总线规定RC的RCB参数的值为64B或者128B,其他PCIE设备的RCB参数为128B。
当一个EP向RC或者其他EP读取数据时,这个RP首先向RC或者其他EP发送存储器读请求TLP。之后由RC或者其他EP发送存储器读完成TLP,将数据传递给这个EP。
如果存储器读完成报文所传递的地址范围没有跨越RCB参数的边界,那么数据发送端只能使用一个存储器读完成报文将数据传递给请求方,否则可以使用多个存储器读完成TLP。
如果存储器读完成报文所传递的数据地址范围跨越了RCB边界,那么数据发送端(目标设备)可以使用一个或者多个完成报文进行数据传递。数据发送端使用多个存储器读完成报文完成数据传递时,需要遵守以下原则。
- 第一个完成报文所传送的数据,其其实地址与要求的起始地址相同。其结束地址或者为要求的结束地址(使用一个完成报文传递所有数据),或者为RCB参数的整数倍(使用多个完成报文传递数据)。
- 最后一个完成报文的起始地址或者为要求的起始地址(使用一个完成报文传递所有数据),或者为RCB参数的整数倍(使用多个完成报文传递数据)。其结束地址必须为要求的结束地址。
- 中间的完成报文的起始地址和结束地址必须为RCB参数的整数倍。
这里只介绍与本次实验相关的TLP。其他部分TLP格式详情见《PCI+EXPRESS体系结构导读》第六章
-
XAPP1052工程搭建仿真
前面学习XILINX的XDMA,XDMA是一个用户开发量很小的DMA数据搬移工具。只需要在XILINX提供的BD平台上使用原理图开发既可以搭建一个XDMA开发平台,数据搬移全是经过AXI总线协议。用户只需要了解完毕AXI协议,搭建一个USER既可以实现CPU和FPGA的数据搬移。并且为用户提供了M_AXI和AXI_LITE以及AXI_STREAM方便用户进行数据传递和寄存器控制。感兴趣的可以看我的另外一篇文章。
(364条消息) XDMA调试记录_hy_520520的博客-CSDN博客_xdma
后面又学习一个开源的RIFFA PICE,该平台是Github上一个开源项目。RIFFA是一个简单硬件描述语言设计框架,主要通过PCIE实现上位机和FPGA之间的通信,解决了FPGA和CPU之间的高速数据交换。其开源版本实现了FPGA与window和Linux主机之间的数据传输。支持Altera和Xilinx的FPGA,主要实现了数据发送和数据接收的两个功能。数据采用FIFO作为接口,用户只需要编写简单的控制逻辑代码。感兴趣的可以去看另外一篇文章。
(364条消息) 基于Riffa架构的PCIEDMA测试分析_hy_520520的博客-CSDN博客_riffa
现在为了深入学习DMA的运作过程。在网上翻阅相关的资料,查询到关于XILINX的XAPP1052是一个很好地项目。这个已经是十几年前的开发成果,但是这并不妨碍我们去学习PCIE。前面提到关于XILINX的PCIE的IP核7 Series PCI Express v3.3 IP core。我们知道XILINX的IP现在都接入了AXI协议,PIO模式下就是解析在AXI协议上解析TLP数据,实现了PCIE的单点通信。属于PCIE最基础的应用。不适用用大数据量的通信。而XAPP1052就很好的解决了这一痛点。XAPP1052在单对单的通信基础上增加了DMA通信,可以实现大规模数据搬移。正式因为PCIE的TLP特点,经过前面对PCIE的TLP分析可以知道一个TLP可以带数据和不带数据。带数据的量根据Length长度知道,并且不能超过PCIE设备双方所约定的Max_Read_Request_Size参数。
第一步从XILINX官方下载,直接搜索XAPP1052。
在官网填写资料后既可以下载该文件。xapp1052.zip
同时需要下载文档。xapp1052.pdf
文档详细的介绍了XAPP1052的原理,以及如何通过控制寄存器来启动一次DMA传送。随后说明了驱动的安装以及使用方法。需要注意的是附录部分对DMA相关的寄存器的描述。
-
XAPP1052的工作原理
在xapp1052.zip文件中我们将pcie_7x_0_example工程打开。
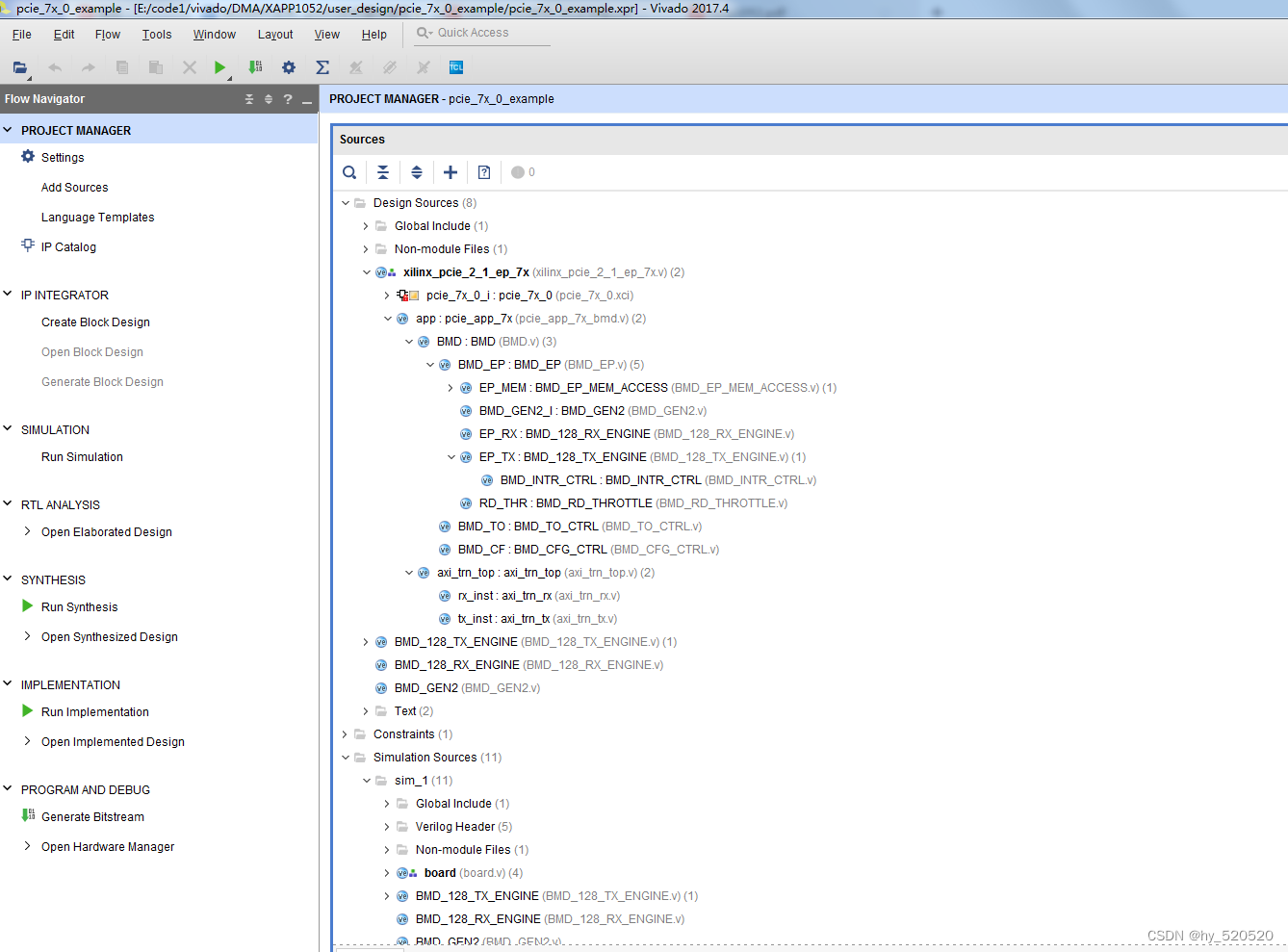
该工程是XILINX在官方开发板KC705上创建的实验工程。
Xapp1052是基于BMD架构。XILINX全系列IP都支持AXI协议,xapp1052使用了BMD协议。Xilinx在文件中已经做好了AXI转BMD协议过程。下面是官方给到的BMD结构示意图。
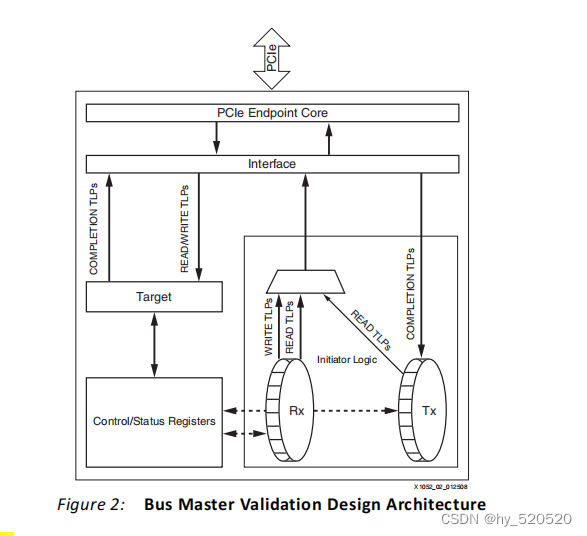
BMD结构由initiator logic,target logic,status/control registers,interface logic,和endpoint core for PCI Express组成。
| 结构 | 作用 |
| initiator logic | 生成内存写入或者内的读取TLP |
| target logic | 负值接收单个内存读或者写入TLP |
| status/control registers | 寄存器模块 |
| interface logic | 接口逻辑 |
| endpoint core for PCI Express | IP Core |
结合上图代码中的结构。
| 模块 | 作用 |
| BMD_EP_MEM_ACCESS.v | 负责BAR空间寄存器部分的写入读出。存放了一组操作DMA控制器的寄存器。RC通过向EP发送存储器读写请求控制读写,从而完成DMA相关的操作。 |
| BMD_128_RX_ENGINE.v | 负责接收RC发送的存储器读请求TLP和存储器写请求TLP。 以及接收RC发送的存储器读完成报文CPLD。 |
| BMD_128_TX_ENGINE.v | 向RC发送带数据的存储器读完成报文。 启动DMA读。即向RC发送存储器读请求TLP。 |
| axi_trn_top.v | 负责将IP的AXI信号转换为BMD信号。 |
-
BAR空间
XAPP1052使用了BAR0空间,使用了2KB的大小,在实际中,使用了如下的寄存器。此部分在XAPP1052.pdf中有详细的说明,这里我摘取一部分。
| 寄存器 | 偏移量 | 描述 |
| 设备控制状态寄存器 | 0x00 | bit31~8:FPGA芯片型号,接口类型,版本信息等等。 bit0:DMA复位。 |
| 设备DMA控制状态寄存器 | 0x04 | bit23:读DMA完成的中断禁用。 bit22:设置读no-snoop位。 bit21:设置读relaxed模型。 bit16:读DMA开始 bit7:写DMA完成的中断禁用 bit6:设置写no-snoop位(cache命中有关) bit5:设置写relaxed模型。即可以超前写。 bit0:写DMA开始。 |
| 写入DMA TLP地址寄存器 | 0x08 | bit31~0:设置DMA写TLP地址,后续的TLP的地址在此基础上增加。 |
| 写入DMA TLP大小寄存器 | 0x0c | bit31~24:使用64位使能时,写入DMA上TLP地址高位。 bit20:与TLP的Requester ID相关。 bit19:64位使能。 bit18~16:控制生成TLP的流量(TLP的传输类型)。 bit15~0:一个TLP后面跟随的数据length大小。 |
| 写入DMA TLP计数寄存器 | 0x10 | bit15~0:设置DMA写入TLP的个数。 |
| 写入DMA数据测试寄存器 | 0x14 | bit31~0:设置DMA写入的测试数据。XAPP1052将次数据作为测试数据通过TLP发送。(仅仅测试用) |
| 校验数据寄存器 | 0x18 | bit31~0:设置DMA读取时从内存中发送的数据和此数据对比,校验数据是否一致。(仅仅测试用) |
| 读取DMA TLP地址寄存器 | 0x1c | bit31~0:设置DMA读取TLP地址,后续的TLP的地址在此基础上增加。 |
| 读取DMA TLP大小寄存器 | 0x20 | bit31~24:使用64位使能时,写入DMA上TLP地址高位。 bit20:与TLP的Requester ID相关。 bit19:64位使能。 bit18~16:控制生成TLP的流量(TLP的传输类型)。 bit15~0:一个TLP后面跟随的数据length大小。 |
| 读取DMA TLP计数寄存器 | 0x24 | bit15~0:读出TLP包的个数(tx中只使用了低15位)。 |
| 写入DMA性能寄存器 | 0x28 | bit31~0:锁存在DMA写入期间总时钟周期。 |
| 读取DMA性能寄存器 | 0x2c | bit31~0:锁存在DMA读取期间总时钟周期。 |
| 设备数据负载寄存器 | 0x40(RO) | bit18~16:约定最大读请求大小(DW) bit10~8:设备规定的TLP报文的有效数据负载大小(DW) bit2~0:设备支持的TLP报文最大数据负载(DW) |
Xapp1052只使用了bar0空间,且baro0空间全部为与DMA控制相关的。用户使用时,可以再此基础上开发bar1空间,用于存放用户寄存器。
-
RC(CPU)读写EP(FPGA)寄存器空间
xapp1052使用单点读写访问FPGA内部寄存器空间。
其读出过程如下。
RC主动发起一次存储器读请求TLP。
在xapp1052中,由RC发起的存储器读写均为单次的读写,即length为1。只带一个数据。
在RX模块中,模块收到一个存储器读请求TLP。从当前的存储器读请求TLP头中提取出,各个字段的参数,其中Byte0,Byte4中的参数保存在TX模块上去。方便TX模块创建存储器读完成TLP,并且将地址上对应的数据从MEM模块中找出来加载到TX发送的存储器读完成TLP上。发送完毕后产生响应信号发送给IP Core。
TX模块检测到req_compl_信号,表示RX模块接收的存储器读请求有效。TX模块准备发送存储器读完成TLP。Byte0字段根据RX接收到的发送,Byte4的Byte Count字段根据存储器读请求TLP头的First DW BE确定保留读出寄存器的那几位有效。Lower address存放在存储器读完成TLP中第一个数据所对应地址的最低位。值的注意的是,在读完成报文中,并不存在First DW BE和Last DW BE字段,因此接收端必须使用存储器读完成TLP的Low Address字段,识别一个TLP中包含数据的起始地址。随后放入1DW的数据。此时,由RC发起的存储器读请求TLP,由FPGA收到并且发送了带数据存储器读完成TLP。一次读完成。
RC主动发起一次存储器写请求TLP。
RC需要配置xapp1052的寄存器,这时候由RC主动发起一次存储器写请求。
由RC主动发起的存储器写请求。在XAPP1052中,由RC发起的存储器写请求length长度为1。将写入的地址Address[31:2]提取出来,将第一个DW作为写入的数据。RC发起的存储器写请求就被FPGA的RX模块解析,解析出地址,数据。从而在MEM模块中将需要写入地址上的值写入。
-
DMA写
XAPP1052使用DMA写过程是将0x14地址上的数据通过存储器写请求TLP发送到RC。启动DMA写入的过程如下所示。
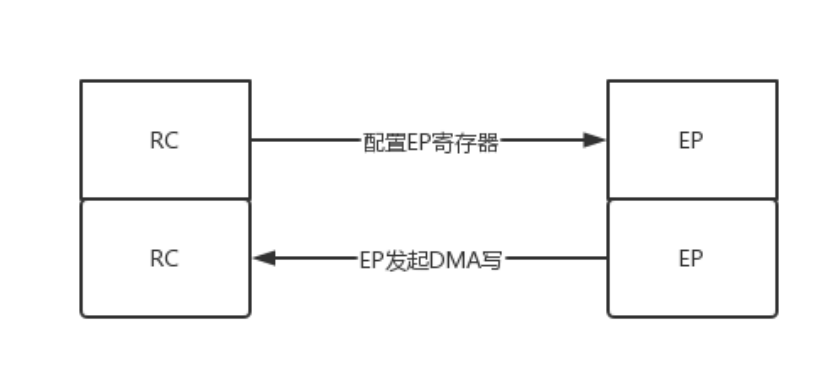
启动写过程在XAPP1052.pdf上我们可以看到配置过程如下。

- 配置Assert Initiator Reset寄存器(设备控制状态寄存器),复位DMA。
- 配置Write DMA H/W Address寄存器(写入DMA TLP地址寄存器),添加要写入的地址值。
- 配置Write DMA TLP Size寄存器(写入DMA TLP大小寄存器),控制一个TLP后的数据量大小。注意不要超过Max_Read_Request_Size参数。
- 配置Write DMA TLP Count寄存器(写入DMA TLP计数寄存器),控制写入TLP的个数。
- 配置TLP Payload Pattern寄存器(写入DMA数据测试寄存器),控制写入的数据,DMA写过程将此数据发送出去。
- 配置Write DMA Start寄存器(设备DMA控制状态寄存器),控制DMA写入的开始。
上面是官方关于DMA写入的过程。XAPP1052的DMA写入过程较为复杂。XAPP1052需要通过MEM模块产生DMA控制逻辑。示例中,XAPP1052将写入DMA数据测试寄存器上的数据进行封装然后传递给存储器写请求TLP。在由TX模块将存储器写请求TLP发送到RC。
上述过程中,TX发送资源模块将根据配置的TLP大小产生Data Payload。在一个TLP请求发送完成后,根据要写入的TLP的个数,继续发送TLP到RC。
-
DMA读
XAPP1052使用DMA读过程是TX模块接收到读DMA请求,发送存储器读请求TLP后。RC接收到存储器读请求TLP后,打包发送带数据存储器读完成TLP后被RX模块接收。
启动DMA读的过程如下所示。
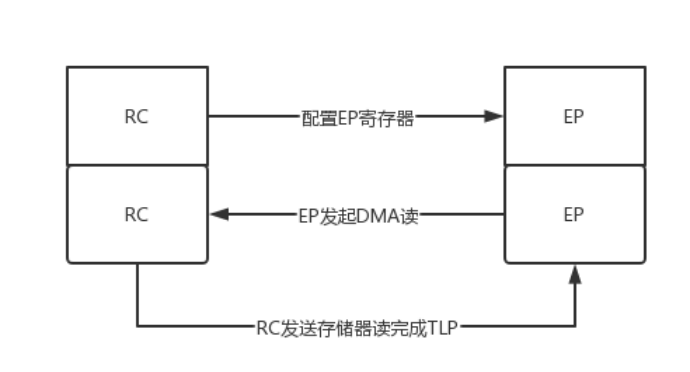
启动读过程在XAPP1052.pdf上我们可以看到配置过程如下。

- 配置Assert Initiator Reset寄存器(设备控制状态寄存器),复位DMA。
- 配置Read DMA H/W Address寄存器(读取DMA TLP地址寄存器),添加要读出的地址值。
- 配置Read DMA TLP Size寄存器(读取DMA TLP大小寄存器),控制一个TLP后的数据量大小。
- 配置Read DMA TLP Count寄存器(读取DMA TLP计数寄存器),控制读取TLP的个数。
- 配置Read DMA Start寄存器(设备DMA控制状态寄存器),控制DMA读取的开始。
上面是官方所述的DMA读取过程。XAPP1052的读取过程较为复杂。XAPP1052需要通过MEM模块产生DMA控制逻辑。通过TX模块向RC发送存储器读请求TLP。RC在收到由EP发送来的存储器读请求TLP后,在目标地址区域准备好数据后,通过存储器读完成报文发送到EP。EP的RX模块接收到存储器读完成TLP后,从后续的Data Payload中提取出数据。存入缓存中。
首先DMA控制逻辑将组织一个或者多个存储器读请求TLP,然后由TX将存储器读请求TLP传递给RC。
RC在正确接收到这个请求报文后,使用一个或者多个存储器读完成TLP将数据传递给EP。
EP卡接收逻辑从RC中获得这些存储器读完成TLP时,首先需要进行乱序处理。之后在完成一个DMA读操作。
-
XAPP1052仿真
前面在学习PCIE_PIO模式时就知道,XILINX为我们提供了一个一个很方便的仿真脚本。我们只需要直接运行仿真部分即可。首先打开下载的xapp1052.zip文件中的在KC705上的实例工程。
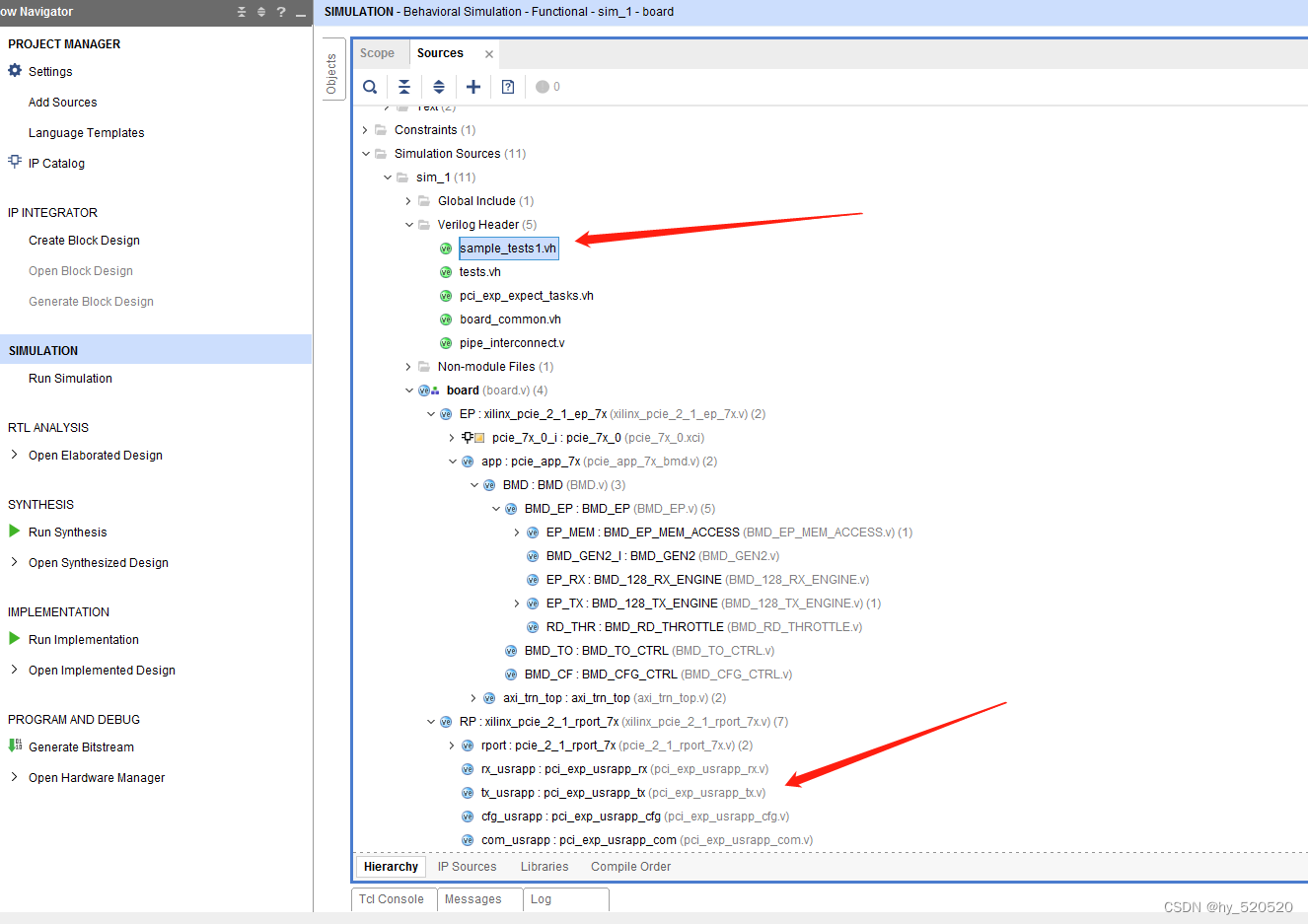
打开实例工程后,这是XILINX提供的仿真模型。可以看到仿真主要分为两个部分,EP即为XAPP1052FPGA代码部分。RP为模拟RC部分,此部分主要模拟RC产生各种TLP。
下面看到pci_exp_usrapp_tx.v部分代码。
使用的initial说明语句,第一部分和第二部分为对寄存器的初始值赋值。
第三部分initial说明语句。
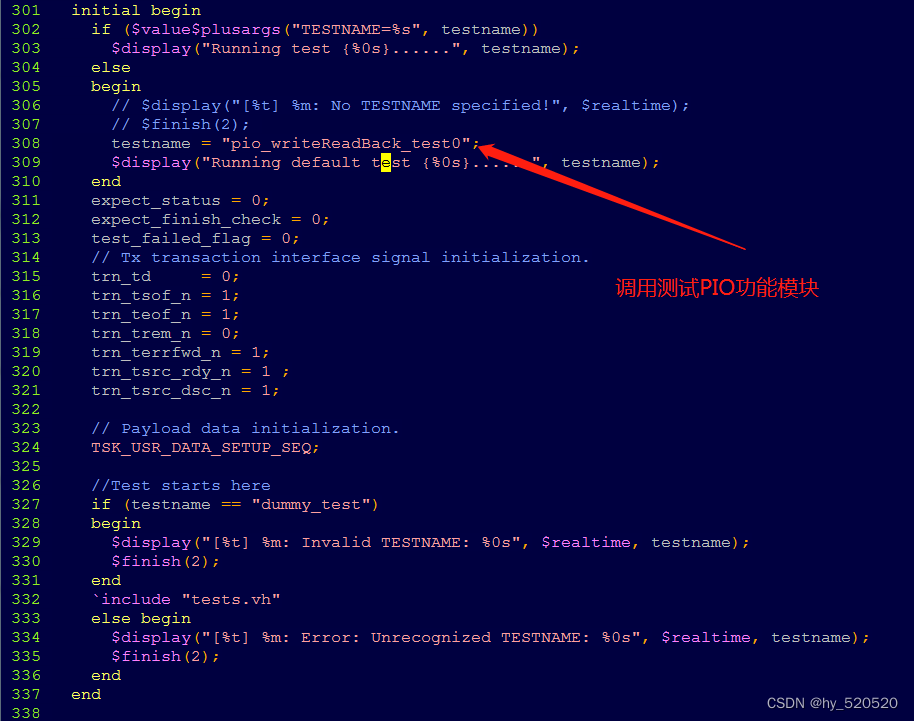
这里我们可以看到调用了pio_writeReadBack_test0测试模块。
下面打开sample_tests1.vh文件。
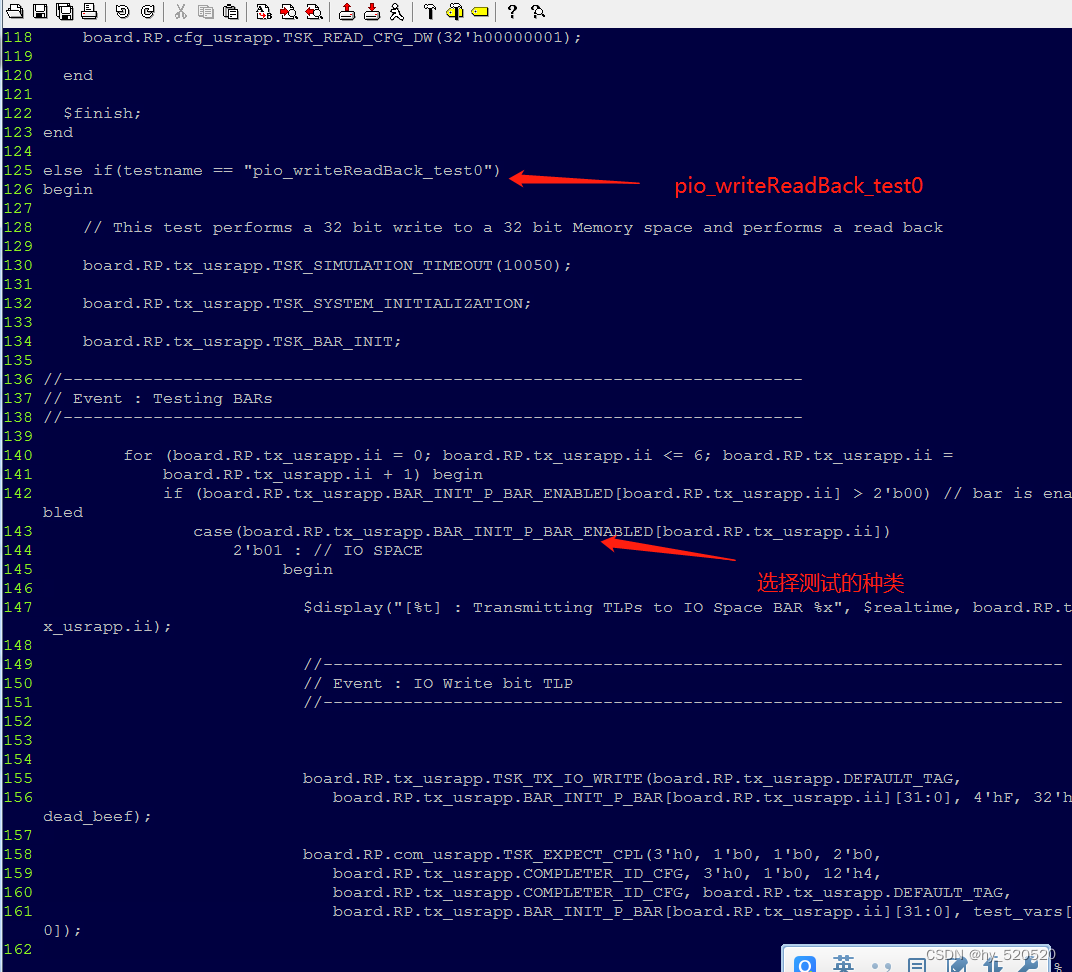
插入代码。我们可以看到,在pio_writeReadBack_test0中,进行了测试。
Event:IO Write bit TLP
Event : IO Read bit TLP
Event : Memory Write 32 bit TLP
Event : Memory Read 32 bit TLP
Event : Memory Write 64 bit TLP
Event : Memory Read 64 bit TLP
代码中根据BAR_INIT_P_BAR_ENABLED参数来决定运行测试种类。
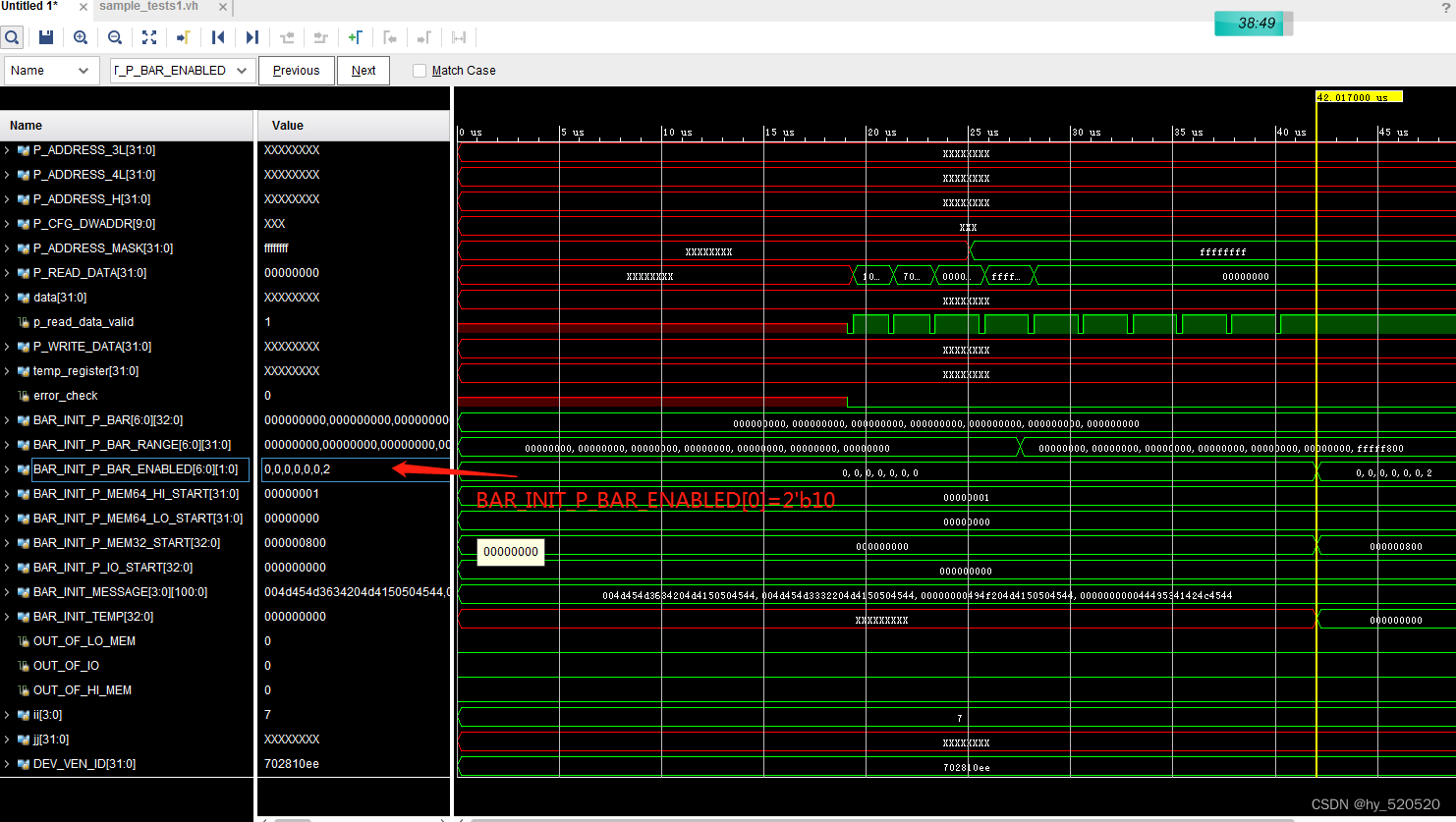
分析BMD_128_RX_ENGINE.v文件。RX部分只接受四种类型的TLP。
32位的存储器读请求TLP。
32位的存储器写请求TLP。
不带数据CPL报文。
带数据CPLD报文。
`define BMD_MEM_RD32_FMT_TYPE 7'b00_00000
`define BMD_MEM_WR32_FMT_TYPE 7'b10_00000
`define BMD_CPL_FMT_TYPE 7'b00_01010
`define BMD_CPLD_FMT_TYPE 7'b10_01010
在仿真中我们打开BMD_128_RX_ENGINE.v部分时序图。
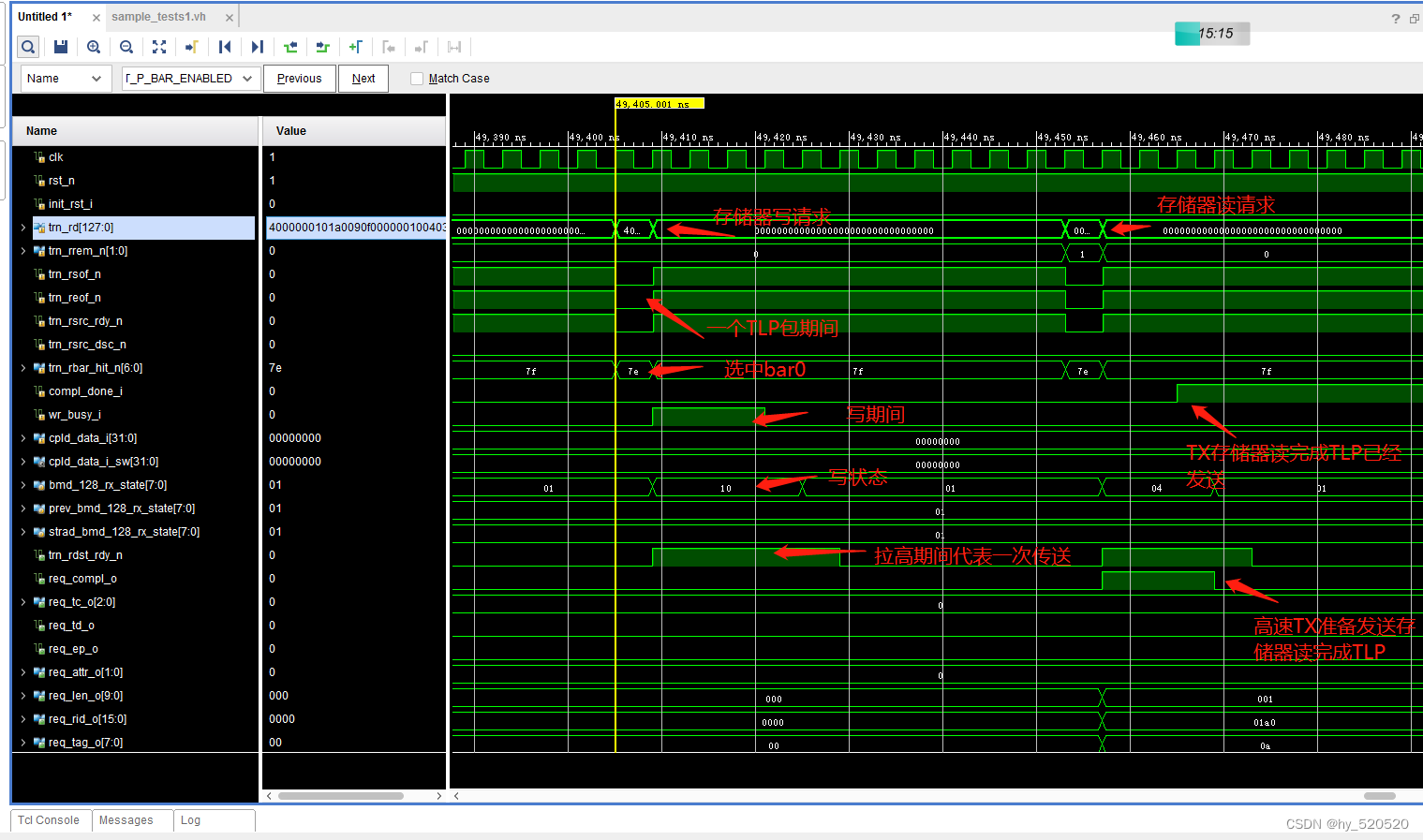
从上面的仿真我们可以看出来,仿真验证了RC发送存储器读写请求的过程。
写过程:存储器写请求TLP包到来,解析TLP。进入写状态。解析出数据地址等信号。MEM写入完成拉低wr_busy_i。
读过程:存储器读请求TLP包到来,解析TLP。进入读状态。拉高req_compl_o信号,告诉TX模块准备发送存储器读完成TLP。TX发送完成后,拉高compl_done_i信号,告诉RX模块读完成。
上面已经提到。DMA的过程全部是由FPGA主动发起的,不过需要RC来配置FPGA的寄存器,告诉FPGA这个DMA的过程中的地址,TLP长度,以及TLP的个数。
下面我们对仿真文件进行改写。这里只验证DMA写入的过程。
首先打开pci_exp_usrapp_tx.v文件。
前面说到,原本的仿真只进行了PIO存储器读写验真。并没有进行DMA部分的仿真。这里我们需要添加DMA部分仿真。名字为:“user_test_1”。
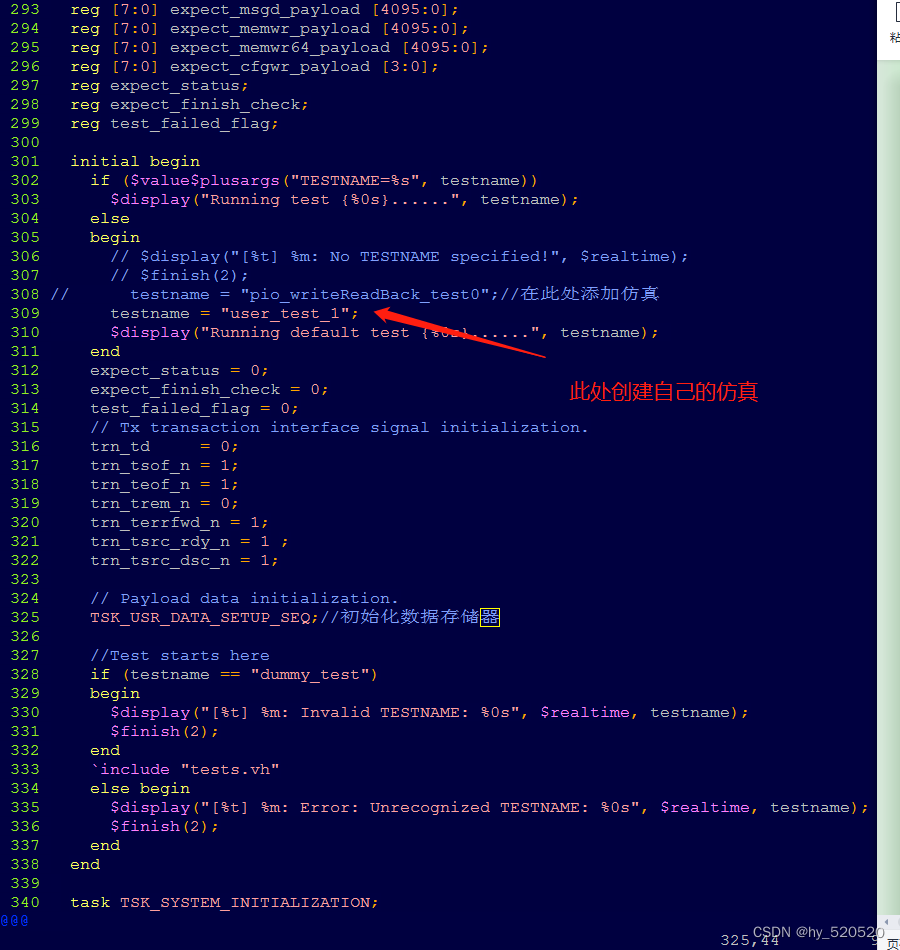
接下来在sample_tests1.vh文件中创建自己的仿真文件。
-
DMA写仿真
前面已经在pci_exp_usrapp_tx.v文件中修改了添加了自己的仿真部分user_test_1。接下来我们在sample_tests1.vh中添加。
插入代码
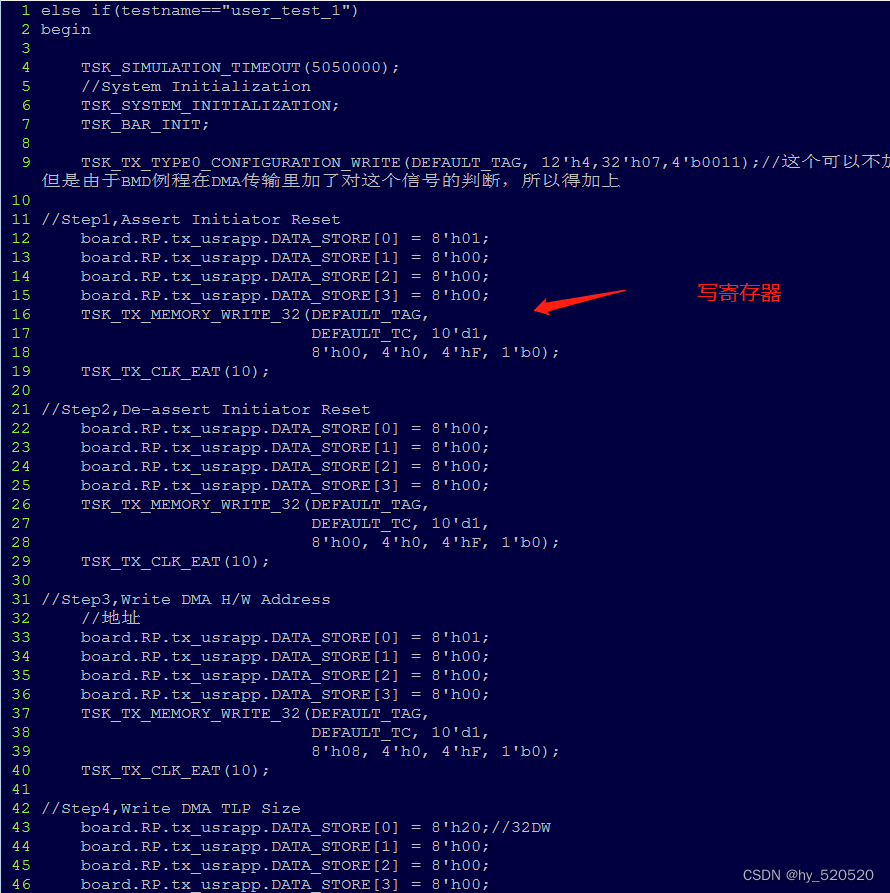
添加这部分配置DMA启动后。我们打开仿真。在BMD_128_RX_ENGINE仿真中。寻找
init_rst_i信号,此信号为复位DMA控制器。
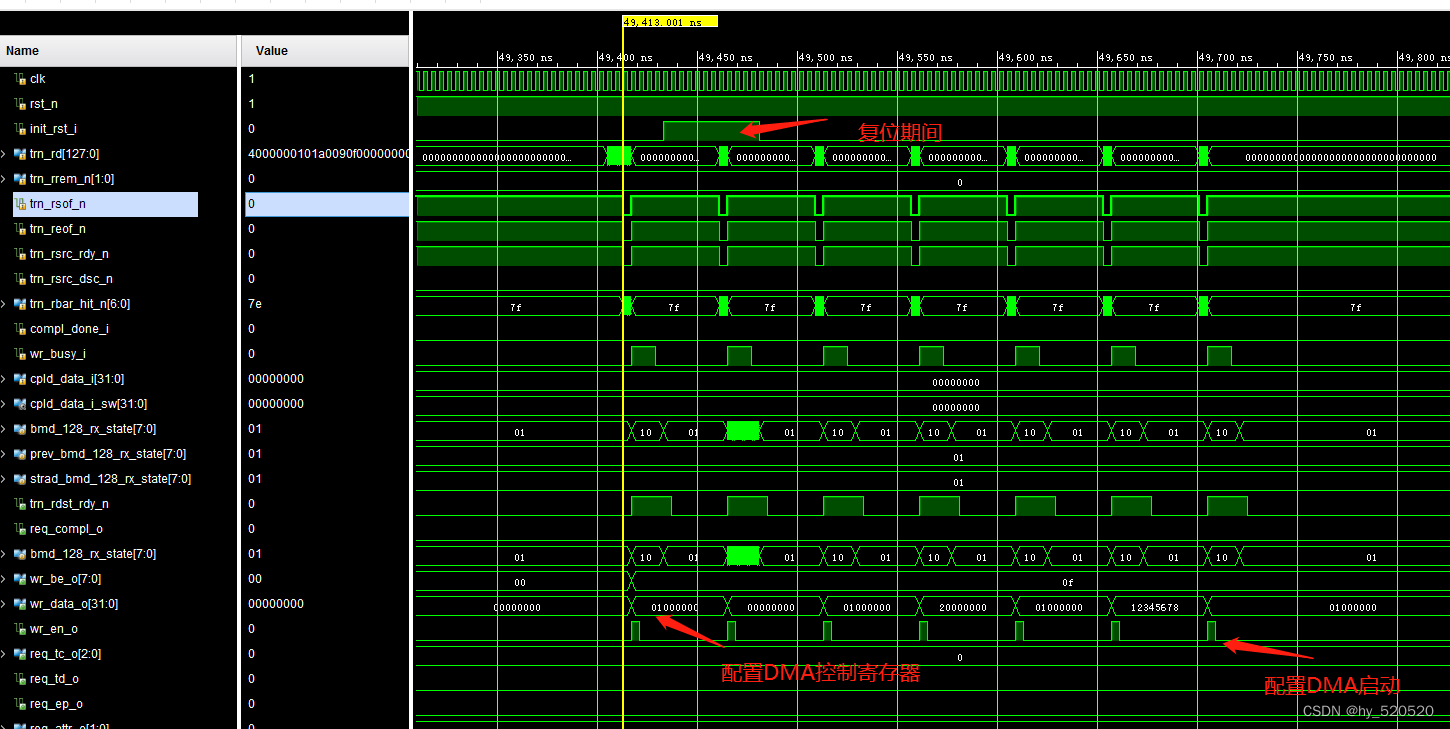
在图中我们看到EP的RX模块成功接收了由RC发出的存储器写TLP。
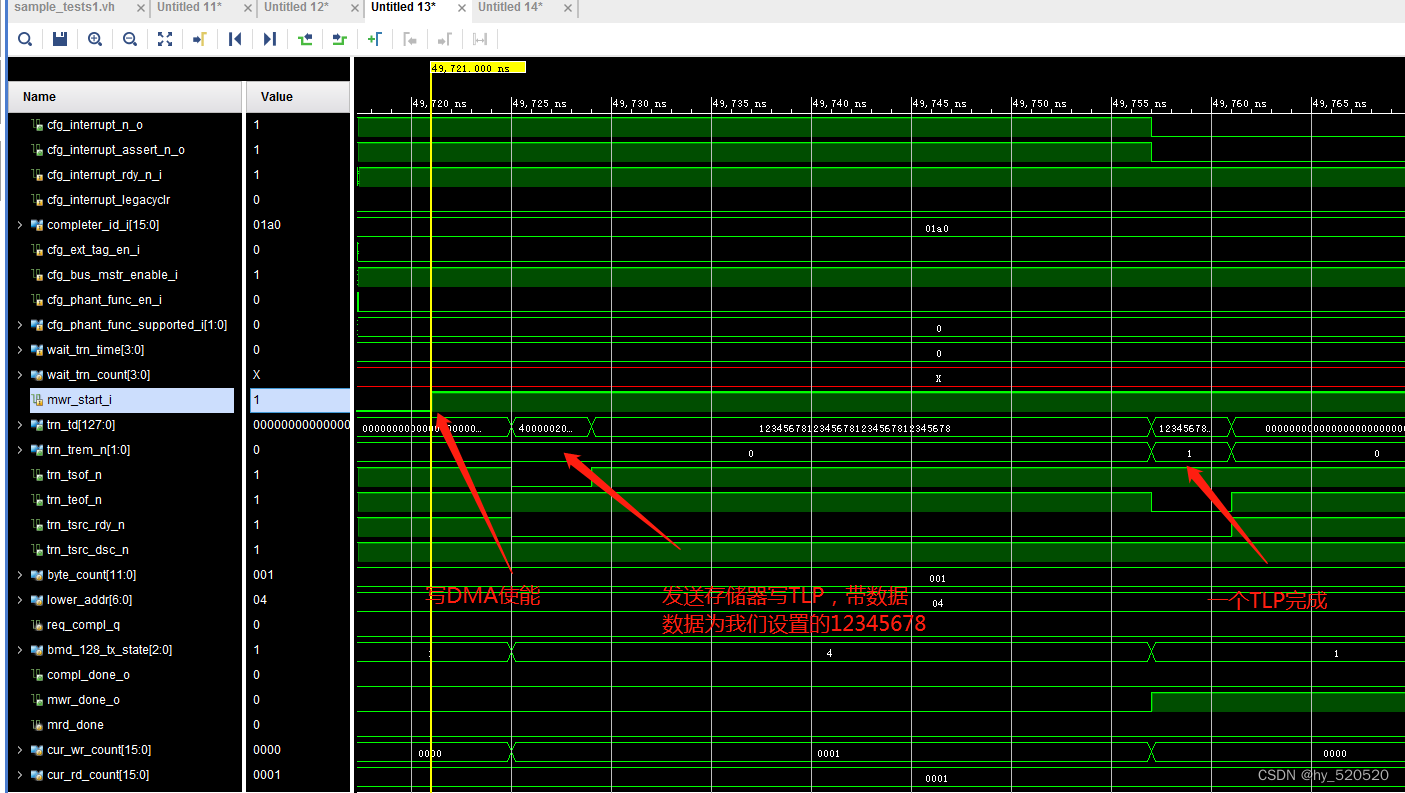
从图中可以看到在EP的RX模块接收到由RC发出的配置DMA启动后,TX模块自动启动发送存储器写请求TLP。发送的数据为12345678,数据量为32个DW。感兴趣的朋友可以在仿真中修改TLP个数和大小。
-
DMA读仿真
对比DMA写仿真,DMA读仿真需要改动的地方就更多了。同样的是,需要RC先去配置EP的DMA控制器寄存器。TX发出存储器读请求TLP后,RC给EP发送带数据的存储器读完成TLP。
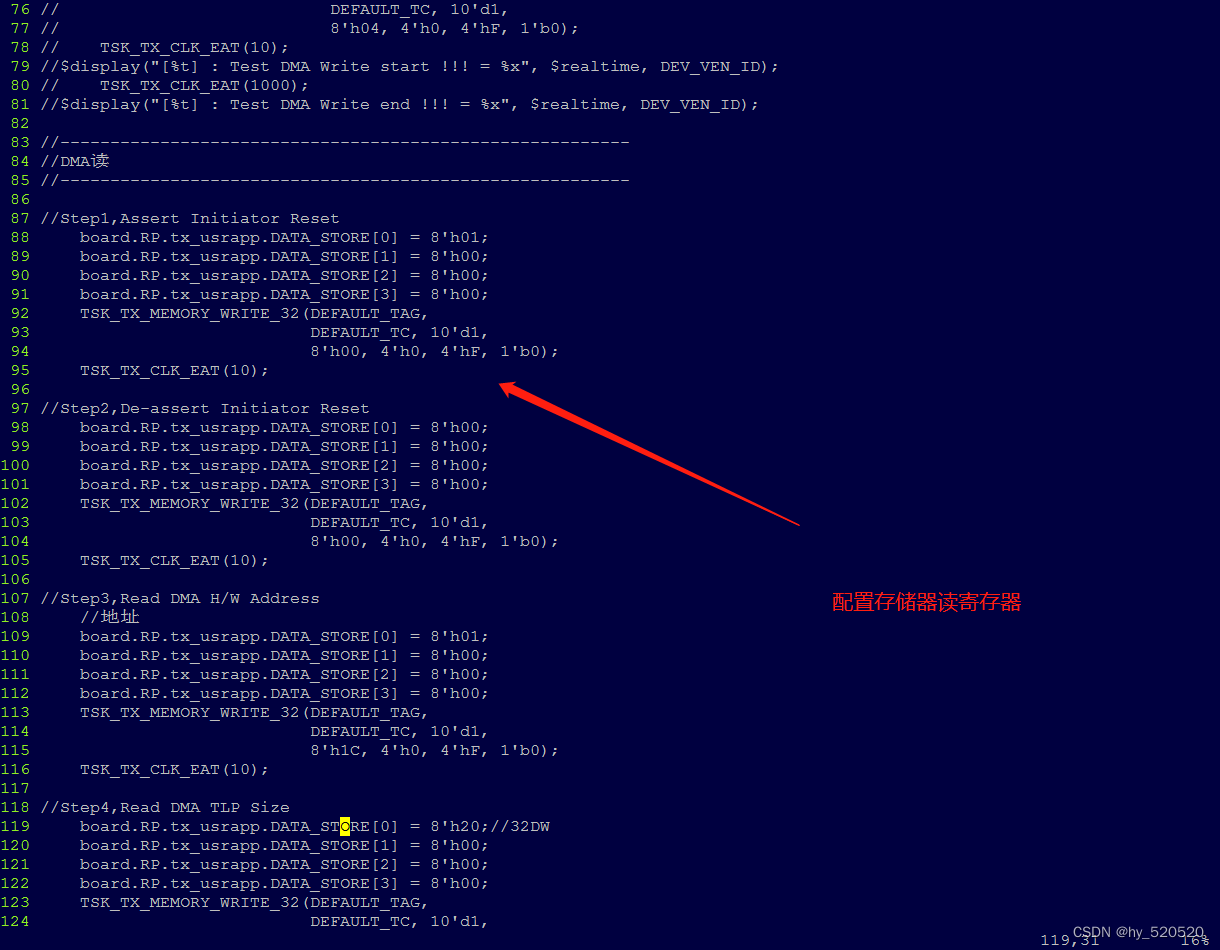
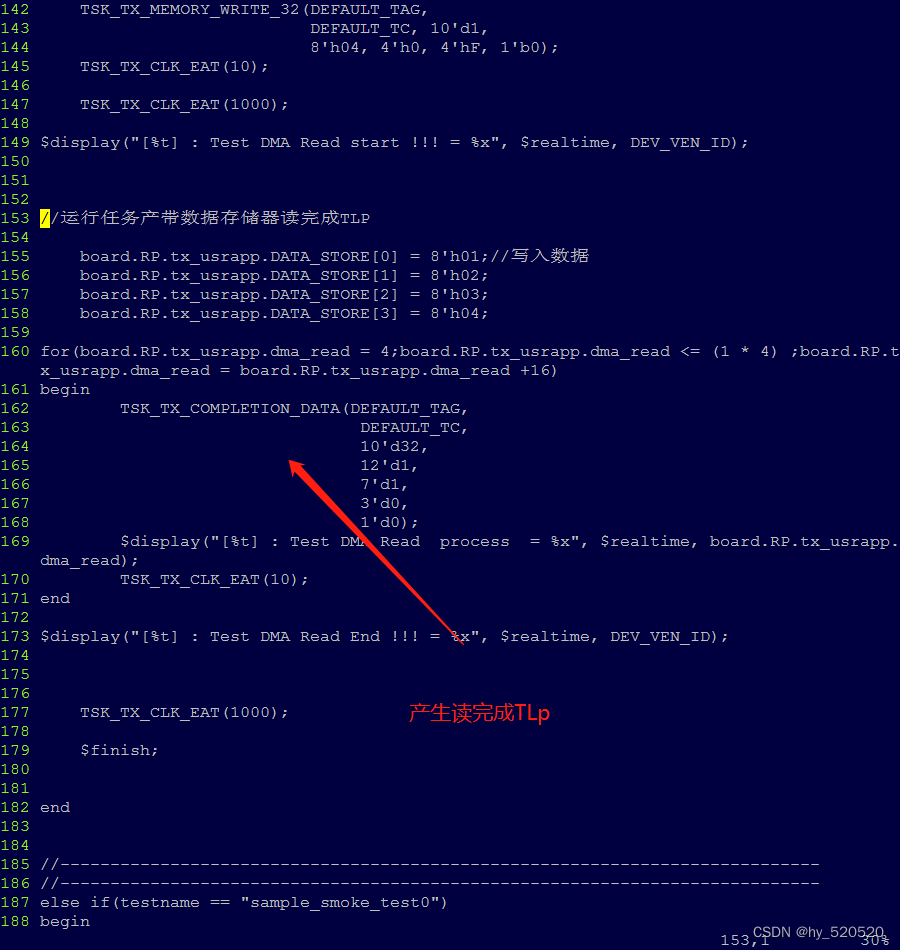
代码解读。这里我使用取巧的方式,在发送玩DMA控制器配置命令后。等待直接启动任务向EP发送存储器读完成TLP。
修改task任务模块。保证RC发送的存储器读完成,能够被EP接收。
/************************************************************
Task : TSK_TX_COMPLETION_DATA
Inputs : Tag, TC, Length, Completion ID
Outputs : Transaction Tx Interface Signaling
Description : Generates a Completion TLP
*************************************************************/
task TSK_TX_COMPLETION_DATA;
//生成一个完成TLP
//使用全局COMPLETE_ID_CFG作为完成ID,将来自根端口模型的与数据TLP的PCI快速完成发送到端点DUT。全局DATA_STORE字节数组用于将完成数据传递给任务
input [7:0] tag_;
input [2:0] tc_;
input [9:0] len_;
input [11:0] byte_count_;
input [6:0] lower_addr_;
input [2:0] comp_status_;
input ep_;
reg [10:0] _len;
integer _j;
begin
if (len_ == 0)
_len = 1024;
else
_len = len_;
if (trn_lnk_up_n) begin
$display("[%t] : Trn interface is MIA", $realtime);
$finish(1);
end
TSK_TX_SYNCHRONIZE(0, 0, 0);
// trn_td <= #(Tcq) {
// 1'b0,
// 2'b10,
// 5'b01010,
// 1'b0,
// tc_,
// 4'b0000,
// 1'b0,
// 1'b0,
// 2'b00,
// 2'b00,
// len_, // 32
// COMPLETER_ID_CFG,
// comp_status_,
// 1'b0,
// byte_count_, // 64
// REQUESTER_ID,
// tag_,
// 1'b0,
// lower_addr_,
// DATA_STORE[0],
// DATA_STORE[1],
// DATA_STORE[2],
// DATA_STORE[3]
// };
trn_td <= #(Tcq) {
1'b0,
2'b10,
5'b01010,
1'b0,
tc_,
4'b0000,
1'b0,
1'b0,
2'b00,
2'b00,
len_, // 32
COMPLETER_ID_CFG,
comp_status_,
1'b0,
byte_count_, // 64
COMPLETER_ID_CFG,
tag_,
1'b0,
lower_addr_,
DATA_STORE[0],
DATA_STORE[1],
DATA_STORE[2],
DATA_STORE[3]
};
trn_tsof_n <= #(Tcq) 0;
trn_tsrc_rdy_n <= #(Tcq) 0 ;
if (_len == 1) begin
trn_teof_n <= #(Tcq) 0;
if (ep_)
trn_terrfwd_n <= #(Tcq) 0;
trn_trem_n <= #(Tcq) 2'b00;
TSK_TX_SYNCHRONIZE(1, 1, 1);
end else begin
trn_teof_n <= #(Tcq) 1;
trn_trem_n <= #(Tcq) 2'b00;
TSK_TX_SYNCHRONIZE(1, 1, 0);
for (_j = 4; _j < (_len * 4); _j = _j + 16) begin
// trn_td <= #(Tcq) {
// DATA_STORE[_j + 0],
// DATA_STORE[_j + 1],
// DATA_STORE[_j + 2],
// DATA_STORE[_j + 3],
// DATA_STORE[_j + 4],
// DATA_STORE[_j + 5],
// DATA_STORE[_j + 6],
// DATA_STORE[_j + 7],
// DATA_STORE[_j + 8],
// DATA_STORE[_j + 9],
// DATA_STORE[_j + 10],
// DATA_STORE[_j + 11],
// DATA_STORE[_j + 12],
// DATA_STORE[_j + 13],
// DATA_STORE[_j + 14],
// DATA_STORE[_j + 15]
// };
trn_td <= #(Tcq) {
DATA_STORE[0],
DATA_STORE[1],
DATA_STORE[2],
DATA_STORE[3],
DATA_STORE[0],
DATA_STORE[1],
DATA_STORE[2],
DATA_STORE[3],
DATA_STORE[0],
DATA_STORE[1],
DATA_STORE[2],
DATA_STORE[3],
DATA_STORE[0],
DATA_STORE[1],
DATA_STORE[2],
DATA_STORE[3]
};
if ((_j + 15) >= ((_len * 4) - 1)) begin
trn_tsof_n <= #(Tcq) 1;
trn_teof_n <= #(Tcq) 0;
if (ep_)
trn_terrfwd_n <= #(Tcq) 0;
trn_tsrc_rdy_n <= #(Tcq) 0;
case ((_len - 1) % 4)
1 : trn_trem_n <= #(Tcq) 2'b11; // D0---------
2 : trn_trem_n <= #(Tcq) 2'b10; // D0-D1------
3 : trn_trem_n <= #(Tcq) 2'b01; // D0-D1-D2---
0 : trn_trem_n <= #(Tcq) 2'b00; // D0-D1-D2-D3
endcase
TSK_TX_SYNCHRONIZE(0, 1, 1);
end else begin
TSK_TX_SYNCHRONIZE(0, 1, 0);
end
end
end
trn_tsof_n <= #(Tcq) 1;
trn_teof_n <= #(Tcq) 1;
trn_terrfwd_n <= #(Tcq) 1;
trn_trem_n <= #(Tcq) 0;
trn_tsrc_rdy_n <= #(Tcq) 1;
end
endtask // TSK_TX_COMPLETION_DATA 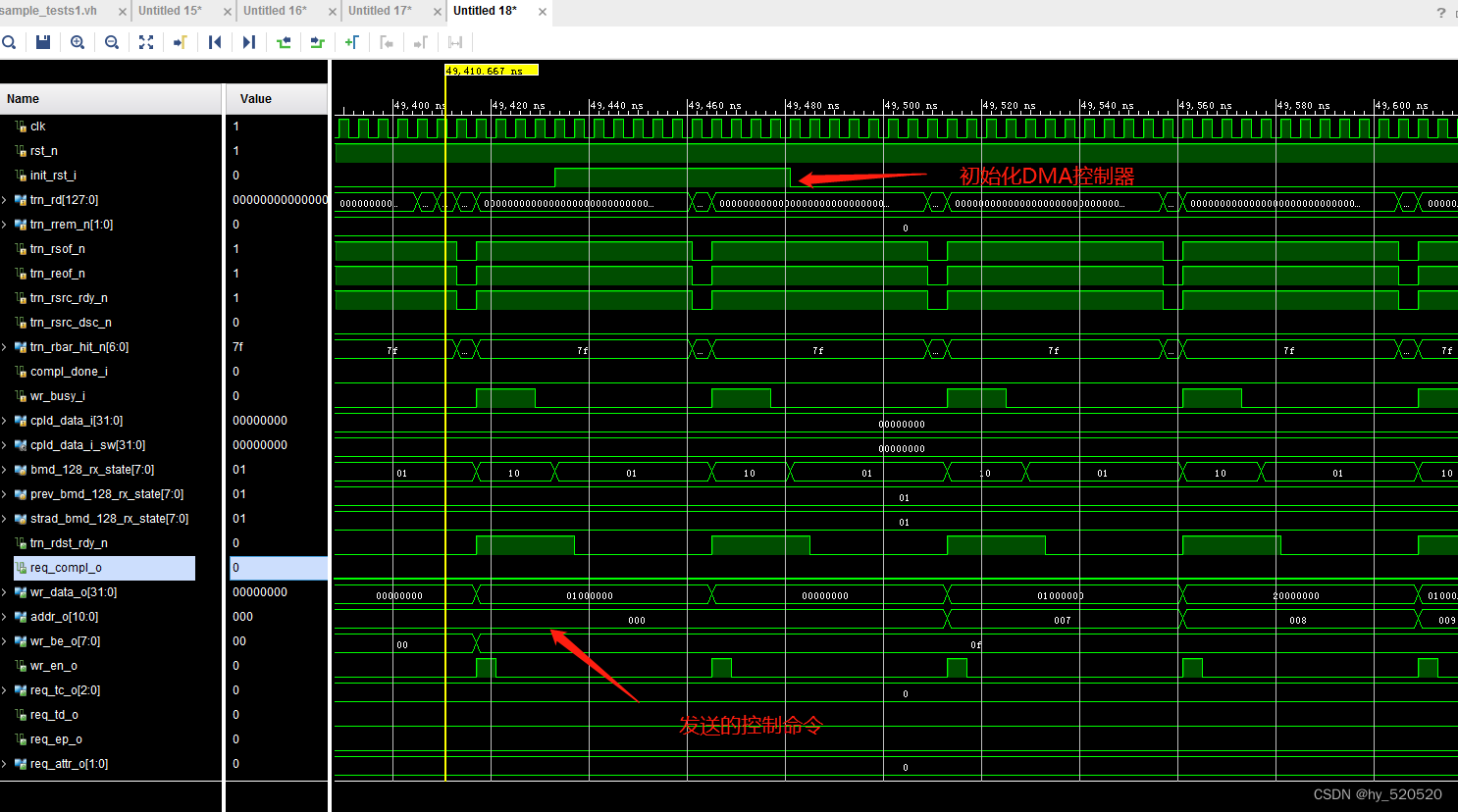
在图中我们看到EP的RX模块成功接收了由RC发出的存储器写TLP。
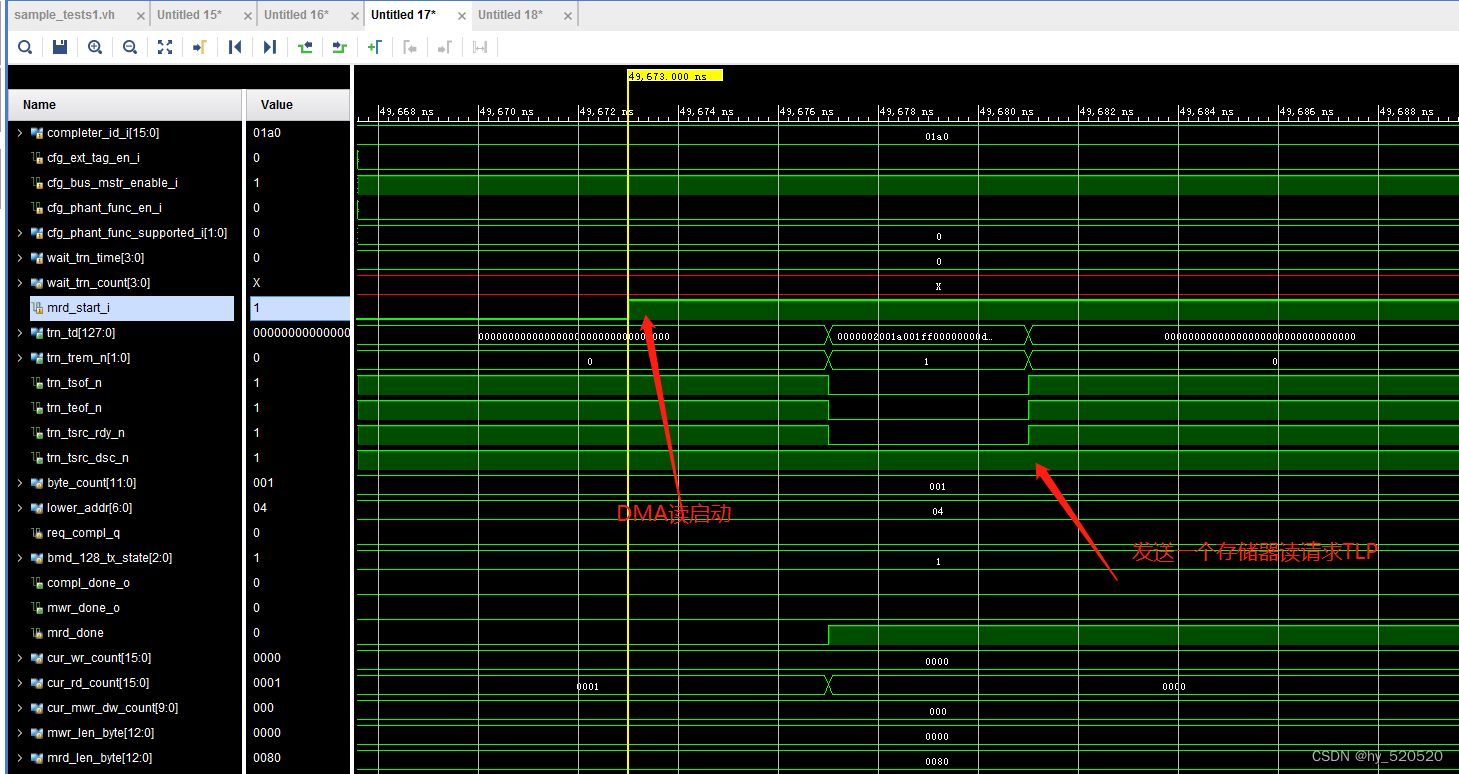
这里我们看TX模块。在收到DMA读取命令后,向RC发送一个存储器读请求TLP。
在RX模块收到由RC发出的存储器读完成报文。
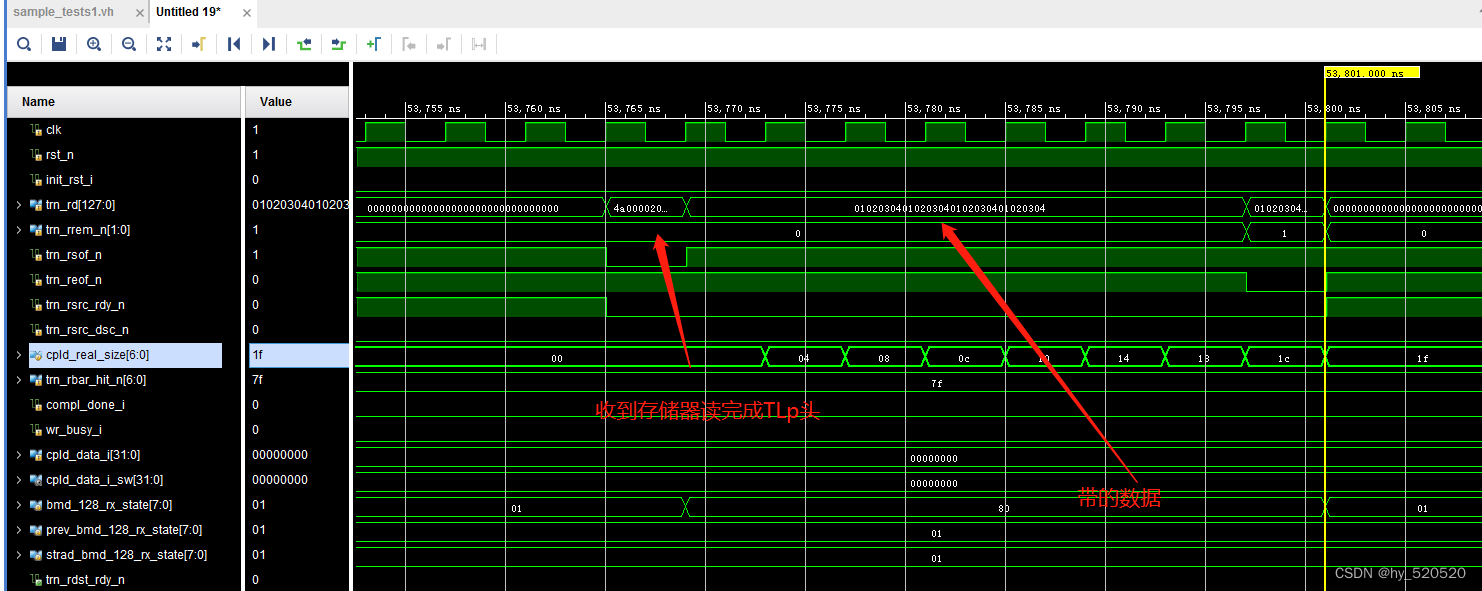
可以看到接收到的数据是由我们设定的01020304。到这里xapp1052的仿真部分就此结束,在DMA读仿真过程中。仿真方法取巧了,RC在启动DMA读后,直接发送了存储器读完成TLP给到EP。有需要的朋友可以在此基础上修改。
下半部分将实现xapp1052修改,以及使用VS2015测试读写。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









