







平台:vivado2017.4
芯片:xc7k325tfbg676-2
继续学习PCIE,发现了一个开源的关于PCIEDMA的项目。RiffaPCIE今天来看一看他里面的窍门。
目录
项目介绍
该项目在github上开源的。但是现在作者将驱动部分删除了。奈何实在不会整驱动这部分的东西,在网上找了一个RIFFA2.2.2的版本,里面有驱动的版本。
RIFFA是一个简单硬件描述语言设计框架,主要通过PCIE实现上位机和FPGA之间的通信,解决了FPGA和CPU之间的高速数据交换。其开源版本实现了FPGA与window和Linux主机之间的数据传输。支持Altera和Xilinx的FPGA,主要实现了数据发送和数据接收的两个功能。
在软件方面,用户只需要编写简单的代码既可以和FPGAIP进行通信。在逻辑方面,项目实例化的设计模块具有单独发送和接收信号的接口,只需要在时钟的控制下通过FIFO接口收发数据,关于PCIE的总线地址,TLP等都不需要用户去设计。
FPGA部分包括Xilinx7系列PCIEIP核,利用发送和接收引擎,经过通道仲裁最多可以映射到12个TX和12个RX。PC部分有RIFFA驱动和RIFFA库。

工程分析
下载好项目后。Install里面是编译好的驱动。Source里面是开源代码。为了方便移植代码,我使用的开发板FPGA芯片是K7和文件夹下的KC705正好一致。Riffa已经有好的工程,这里直接打开E:\code1\vivado\DMA\RIFFA_DMA\riffa_pcie_2.2.2\source\fpga\xilinx\kc705文件夹下面的KC705_Gen2x8If128工程。我们使用的vivado2017.4,直接将工程自动升级到最新版本。
先修改FPGA芯片型号为开发板芯片。
之后发现PCIE的IP需要更新,这里直接更新IP。
直接跟新IP。
这里为了验证PCIEDMA的通信,对比自己的开发板,我们板卡使用的是PCIEx4。修改IP的基本设置后如下。
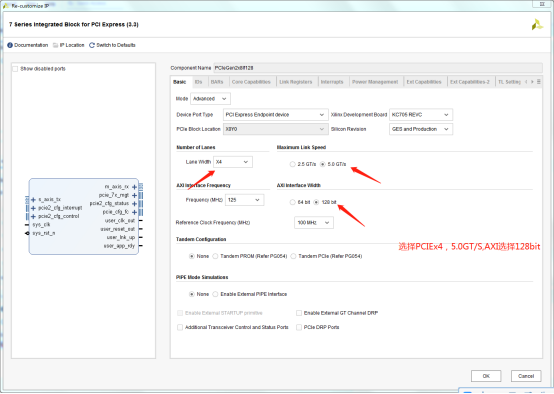
其他的设置保持默认即可。具体的意思可以去看pg054-7series-pcie文档里面很详细的介绍了PCIE的IP核。对于理解PCIE有很大帮助。
修改后需要在源码顶层将修改后信息添加。
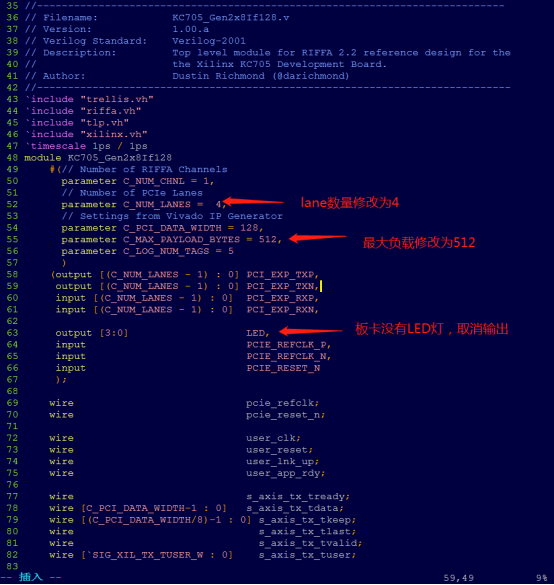
综合。发现有错误。
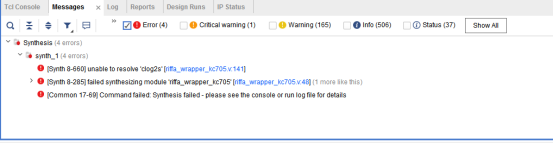
说的是clog2s的问题,找到这个函数的定义,在functions.vh里面,将其设置为set global include。再次编译。
编译完成后,对引脚进行修改。
生成bitstream。
下载到板卡。
驱动安装
在设备管理器里面发现新设备。安装驱动。
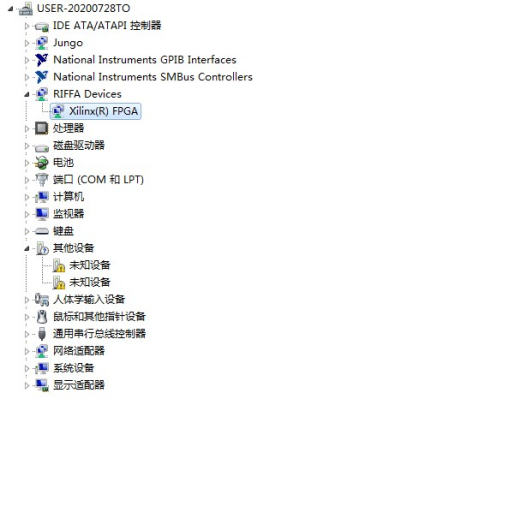
驱动安装完成后。对PCIE进行简单的测试。在C++文件找到sample_app下的testutil.exe。在此处打开命令窗口既可以对Riffa进行简单的测试。
好像并没有说这个怎么用。
代码分析
那直接来看一下testutil.c代码。
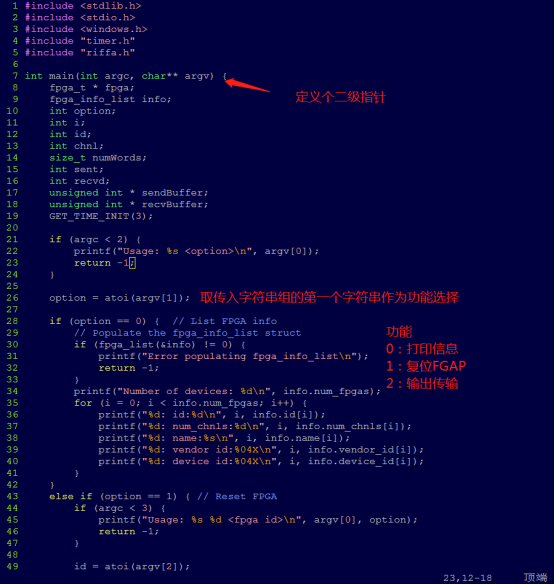
从里面可以看出来,输入的字符串的第一个数用来选择功能(从0开始)。
当第一个数为0的时候,程序的功能为显示FPGA信息。
当第一个数为1的时候,输入的字符串的第二个数指示ID,程序的功能为复位FPGA。
当第一个数为2的时候,输入的字符串的第二个数指示ID,第三个数指示通道号,第四个数指示数据量大小。程序运行为,打开对应ID的FPGA,创建一个发送缓存和一个接收缓存。
发送缓存和接收缓存初始化。发送缓存写1的累加数,接收缓存全写0。
// Initialize the data
for (i = 0; i < numWords; i++) {
sendBuffer[i] = i+1;
recvBuffer[i] = 0;
}将发送缓存里面的数据发送出去。并打印发送了多少个。
sent = fpga_send(fpga, chnl, sendBuffer, numWords, 0, 1, 25000);
printf("words sent: %d\n", sent);将接收到的数据写入接收缓存。并打印接收了多少个。
if (sent != 0) {
// Recv the data
recvd = fpga_recv(fpga, chnl, recvBuffer, numWords, 25000);
printf("words recv: %d\n", recvd);
}然后关闭设备。显示接收缓存的前20个数据。
// Display some data
for (i = 0; i < 20; i++) {
printf("recvBuffer[%d]: %d\n", i, recvBuffer[i]);
}最后对数据进行校验。但是这里对数据校验并没有包含钱4个数据,而是从第四个开始校验。不晓得为什么。
// Display some data
for (i = 0; i < 20; i++) {
printf("recvBuffer[%d]: %d\n", i, recvBuffer[i]);
}
// Check the data
if (recvd != 0) {
for (i = 4; i < recvd; i++) {
if (recvBuffer[i] != sendBuffer[i]) {
printf("recvBuffer[%d]: %d, expected %d\n", i, recvBuffer[i], sendBuffer[i]);
break;
}
}最后根据执行的速度计算出传输速度。打印显示。
printf("send bw: %f MB/s %fms\n",
sent*4.0/1024/1024/((TIME_VAL_TO_MS(1) - TIME_VAL_TO_MS(0))/1000.0),
(TIME_VAL_TO_MS(1) - TIME_VAL_TO_MS(0)) );
printf("recv bw: %f MB/s %fms\n",
recvd*4.0/1024/1024/((TIME_VAL_TO_MS(2) - TIME_VAL_TO_MS(1))/1000.0),
(TIME_VAL_TO_MS(2) - TIME_VAL_TO_MS(1)) );看明白了这个可执行文件的功能,下面进行试验。
测试分析
在sample_app打开命令窗口。
输入:
testutil 0打印FPGA信息。
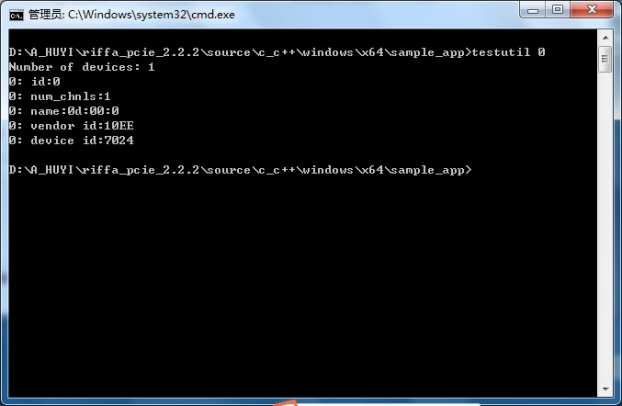
输入:
testutil 1 0复位设备。
输入:
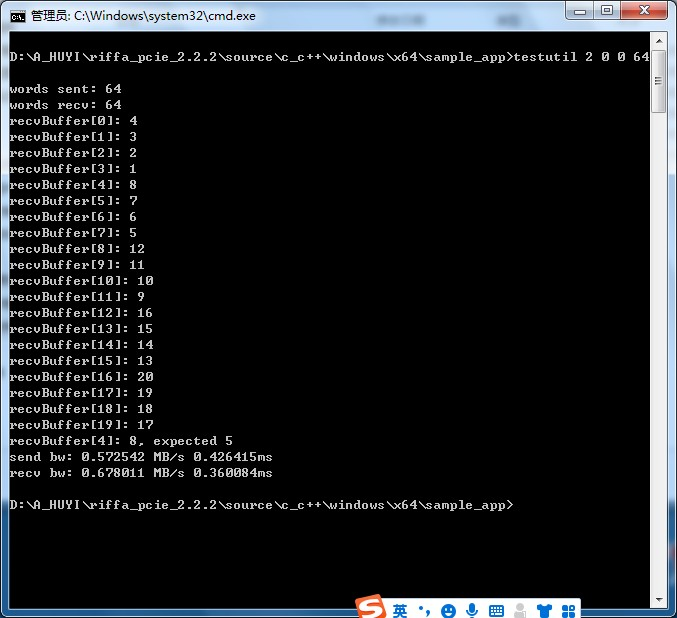
testutil 2 0 0 1024对设备进行收发试验。一次传输数据个数为1024。
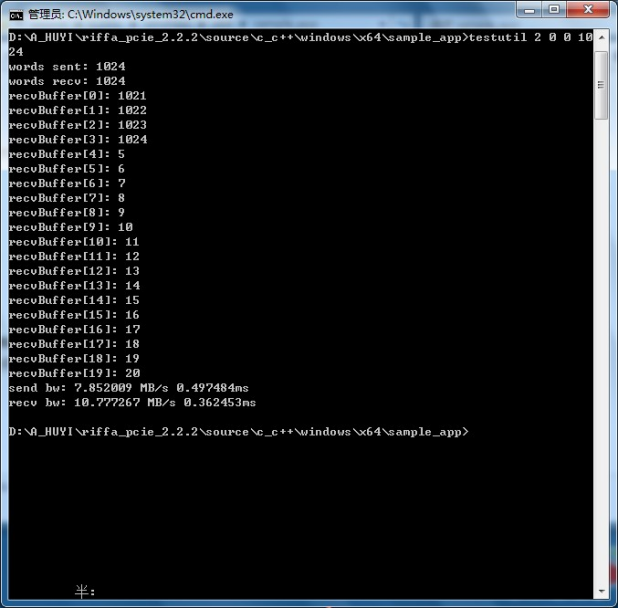
可以看到接收缓存打印出来的前四个数据并不是预想中的1,2,3,4。而是1021,10222,1023,1024。这里还不知晓原因。
继续增加数据量。测试设备的传输速度。
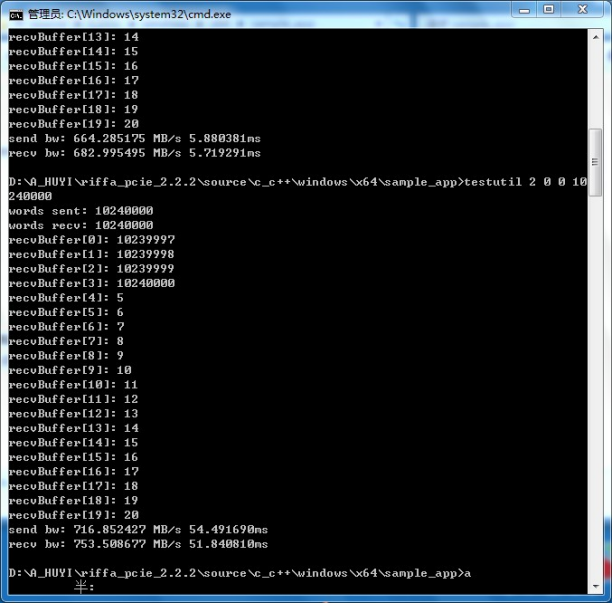
我们使用的设备支持PCIEx4,而riffa只支持PCIEGEN1的带宽。可以看到发送速率:716MB/S 。接收速率:753MB/S 。
而通过计算可以知道。
PCIE2.0X4的带宽为:5GT/S*8/10*4=4Gbps*4=500MB/S*4=2GB/S
PCIE1.0X4的带宽为:2.5GT/S*8/10*4=2Gbps*4=250MB/S*4=1GB/S
这里可能和bios里面的设置有关系。导致只跑到了PCIEGEN1的带宽。
到这里对riffaPCIE的测试结束了,但是并不能简单的将其用起来。
这里将逻辑部分修改一下看一下数据在内部到底怎么传输的。
在工程里面直接修改这个chnl_tester.v文件。首先看看chnl_tester的接口说明。
`timescale 1 ns / 1 ps
module chnl_tester_1#(
parameter U_DLY = 1
)
(
//system signal
input wire CLK ,
input wire RST ,
//写入端口
output wire CHNL_RX_CLK ,//读数据时钟
input wire CHNL_RX ,//RXFIFO控制信号,为1时数据被FIFO接收
output wire CHNL_RX_ACK ,//RXFIFO传输确认信号,该信号为1数据开始接收
input wire CHNL_RX_LAST ,//为1表示最后一个数据被接收
input wire[31:0] CHNL_RX_LEN ,//定义数据长度,以四字节为单位
input wire[30:0] CHNL_RX_OFF ,//通过4个字节字的偏移量来定义开始存储接收数据的位置
input wire[31:0] CHNL_RX_DATA ,//接收的数据
input wire CHNL_RX_DATA_VALID ,//数据有效
output wire CHNL_RX_DATA_REN ,//为1时数据有效,RXFIFO中数据可以被使用
//读出端口
output wire CHNL_TX_CLK ,//发数据时钟
output wire CHNL_TX ,//TXFIFO控制信号,为1时数据被FIFO发送
input wire CHNL_TX_ACK ,//TXFIFO传输确认信号,该信号为1数据开始发送
output wire CHNL_TX_LAST ,//为1表示发送的最后一个数据
output wire[31:0] CHNL_TX_LEN ,//定义数据长度,以四字节为单位
output wire[30:0] CHNL_TX_OFF ,//通过4个字节字的偏移量来定义开始存储发送数据的位置
output wire[31:0] CHNL_TX_DATA ,//发送的数据
output wire CHNL_TX_DATA_VALID ,//数据有效
input wire CHNL_TX_DATA_REN //为1且数据有效时,TXFIFO中数据可以被使用
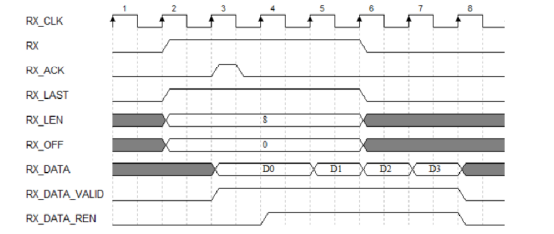
);RIFFA接收通道时序图如图所示。RIFFA通道接收8个4字节(32bit)的数据。当RX为高电平时,RX FIFO开始接收数据,RX_LAST, RX_LEN和RX_OFF的时序与RX严格对齐。当RX_ACK信号为高电平时,对RXFIFO中接收的数据确认。当RX_DATA_VALID和RX_DATA_REN同时为高电平时,DMA引擎开始接收RXFIFO中的数据。RX信号将保持高电平,直到事务的所有数据都被接收到RXFIFO中。图中出现了RX为低电平,而RX_DATA_VALID和RX_DATA_REN仍为高电平的情况,这意味着RXFIFO不再接收新的数据,而DMA引擎正在持续接收RXFIFO中的数据。
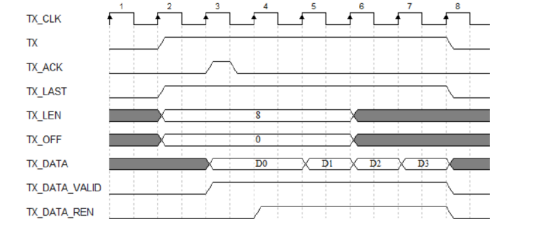
RIFFA的发送如下图所示。RIFFA通道发送8个4字节(32bit)的数据。在所有数据被写入TXFIFO之前,TX信号保持高电平,TX_LAST,TX_LEN和TX_OFF的时序和TX信号一致。当TX_ACK信号为高电平时,TXIFIFO中接收的数据进行确认。当TX_DATA_VALID和TX_DATA_REN同时为高电平时,DMA引擎开始发送 TXFIFO中的数据。TX信号将保持高电平,直到事务的所有数据都被接收到TXFIFO中。
首先使用ILA采集一下逻辑内部的数据传输。
这里我们添加ILA采集数据内部的传输。
ila_0 u_ila_0 (
.clk(CLK), // input wire clk
.probe0(CHNL_RX_CLK ), // input wire [0:0] probe0
.probe1(CHNL_RX ), // input wire [0:0] probe1
.probe2(CHNL_RX_ACK ), // input wire [0:0] probe2
.probe3(CHNL_RX_LAST), // input wire [0:0] probe3
.probe4(CHNL_RX_LEN ), // input wire [31:0] probe4
.probe5(CHNL_RX_OFF ), // input wire [30:0] probe5
.probe6(CHNL_RX_DATA ), // input wire [128:0] probe6
.probe7(CHNL_RX_DATA_VALID), // input wire [0:0] probe7
.probe8(CHNL_RX_DATA_REN ), // input wire [0:0] probe8
.probe9(CHNL_TX_CLK), // input wire [0:0] probe9
.probe10(CHNL_TX ), // input wire [0:0] probe10
.probe11(CHNL_TX_ACK ), // input wire [0:0] probe11
.probe12(CHNL_TX_LAST ), // input wire [0:0] probe12
.probe13(CHNL_TX_LEN ), // input wire [31:0] probe13
.probe14(CHNL_TX_OFF ), // input wire [30:0] probe14
.probe15(CHNL_TX_DATA ), // input wire [128:0] probe15
.probe16(CHNL_TX_DATA_VALID), // input wire [0:0] probe16
.probe17(CHNL_TX_DATA_REN ), // input wire [0:0] probe17
.probe18(rData), // input wire [31:0] probe18
.probe19(rLen), // input wire [31:0] probe19
.probe20(rCount), // input wire [31:0] probe20
.probe21(rState) // input wire [1:0] probe21
);采集,使用命令输入:
testutil 2 0 0 64采集如下
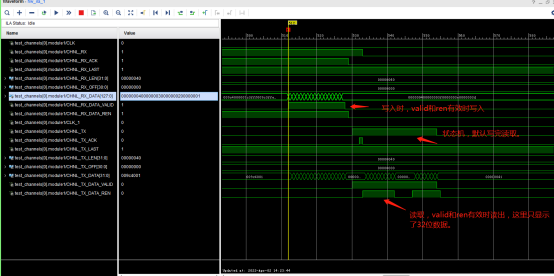
看写入部分,写入的第一个数据为:0x00000004000000030000000200000001。在看写入的最后一个数据为,0x000000400000003f0000003e0000003d。刚好写到0x40即64。
看读出部分。
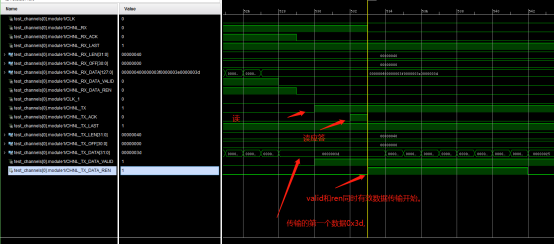
读出部分,这里使用LIA添加了128位的TX_DATA,但是时间采集出来只有32bit,但是也可以大致推断出来,这里,传输的第一个数据为:0x000000400000003f0000003e0000003d,这里就解释了为什么上面sample_app里面检测数据是从4开始检测的了。具体原因看verilog源码(chnl_tester.v)。
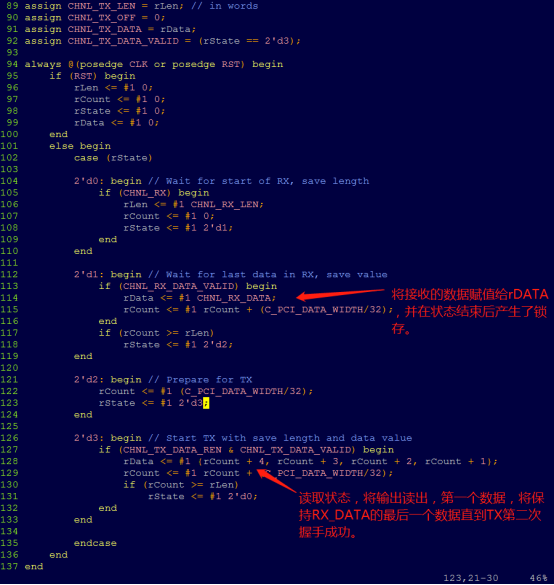
原因就是这样。
修改建议,可以在rstate=2’d2时,增加一句。
2'd2: begin // Prepare for TX
rCount <= #1 (C_PCI_DATA_WIDTH/32);
rState <= #1 2'd3;
rData <= #1 {32'd4, 32'd3, 32'd2, 32'd1};
end这样就保证了读出的第一个数据的正确。
下面修改一下代码,将自定义FIFO内部的数据读出。修改部分如下,将FIFO读出的数据输入到TX_DATA端口。FIFO输入32bit,读出128bit。输入1,2,3......
//--------------------------------------
//fifo
//--------------------------------------
reg [31:0] fifo_wr_data;
reg fifo_wr_data_valid;
wire[11:0] fifo_wr_cnt;
wire[127:0] fifo_rd_data;
wire fifo_rd_data_valid;
reg [7:0] cnt;
assign fifo_rd_data_valid = CHNL_TX_DATA_VALID & CHNL_TX_DATA_REN;
always@(posedge CLK or posedge RST)
begin
if(RST)
begin
fifo_wr_data <= 32'd0;
fifo_wr_data_valid <= 1'b0;
end
else if(fifo_wr_cnt <= 12'd1024 && cnt == 8'd20 )
begin
fifo_wr_data <= fifo_wr_data + 32'd1;
fifo_wr_data_valid <= 1'b1;
end
else
begin
fifo_wr_data <= 32'd0;
fifo_wr_data_valid <= 1'b0;
end
end
always@(posedge CLK or posedge RST)
begin
if(RST)
cnt <= 8'd0;
else if(cnt == 8'd20)
cnt <= cnt;
else
cnt <= cnt + 1'b1;
end
fifo_generator_1 u_fifo_generator_1 (
.rst (RST ),// input wire rst
.wr_clk (CLK ),// input wire wr_clk
.rd_clk (CLK ),// input wire rd_clk
.din (fifo_wr_data ),// input wire [31 : 0] din
.wr_en (fifo_wr_data_valid ),// input wire wr_en
.rd_en (fifo_rd_data_valid ),// input wire rd_en
.dout (fifo_rd_data ),// output wire [127 : 0] dout
.full ( ),// output wire full
.empty ( ),// output wire empty
.rd_data_count ( ),// output wire [11 : 0] rd_data_count
.wr_data_count (fifo_wr_cnt )// output wire [11 : 0] wr_data_count
);测试结果如下。
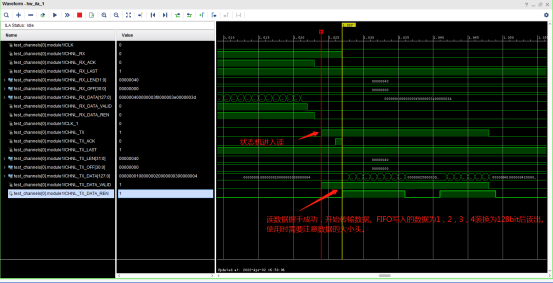
测试结果,FIFO自动写入数据1,2,3,4,经过FIFO位宽转换后,读出的数据数据为0x00000001000000020000000300000004。
测试反馈结果如下。
看得出来数据读出时数据的位置不一致。在实际使用的过程中需要注意这个地方。
整体来说,Riffa做出了大规模数据传输的发送和接收。用户只需要做简单的修改既可以完成数据的传输,还是值得分析分析的。今天的Riffa测试分析就到这里结束了,后续准备吧riffa的十二个通道全部做好,使用产生数据写入DDR,通过Riffa将DDR里面的数据读出到上位机。
















 1699
1699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









