







 超级会员免费看
超级会员免费看

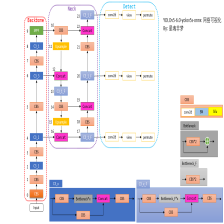
理解有监督学习的深度学习的关键在于将 推理 和 训练 阶段进行分开,分别理解各种深度神经网络架构的推理和训练阶段的操作就可以理解某个模型。
推理阶段是将模型看成一个类似于黑箱的非线性函数,比如通过各种卷积模块的组合构成一个 backbone,输出想要的shape的张量,再去做后处理。
训练阶段是需要划分正负样本,然后根据任务设计一个损失函数,使用优化算法如SGD以迭代的方式更新神经元的weight和bias,优化的目标是最小化损失函数,因此训练好的模型就可以拟合训练集。
我们通常可以把所有的神经网络以 编码器-解码器 的架构进行理解。
图像分类:
- 推理阶段:输入为图像, 然后是编码器(如CNN)进行编码为张量,一般是W/H 减小 x 倍, 而通道数C 增加 y 倍, 编码成新的张量 (W/x, H/x, yC)。然后是 解码器 ,加入FC、softmax 等。当然,也可以将 softmax 之前的全部理解为 编码器, 把softmax 理解为 解

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











