







 该专栏为热销专栏榜 第25名
该专栏为热销专栏榜 第25名 本文介绍了如何将RepViT结构应用到YOLOv8的主干网络中以提升性能。RepViT是将轻量级ViT的设计应用于CNN的尝试,通过结构性重组、扩展比率调整、宏观和微观设计优化实现性能和效率的提升。作者详细阐述了RepViT的基本原理、核心代码,并提供了详细的网络结构添加教程,包括多个修改步骤,以实现YOLOv8的改进。
本文介绍了如何将RepViT结构应用到YOLOv8的主干网络中以提升性能。RepViT是将轻量级ViT的设计应用于CNN的尝试,通过结构性重组、扩展比率调整、宏观和微观设计优化实现性能和效率的提升。作者详细阐述了RepViT的基本原理、核心代码,并提供了详细的网络结构添加教程,包括多个修改步骤,以实现YOLOv8的改进。
一、本文介绍
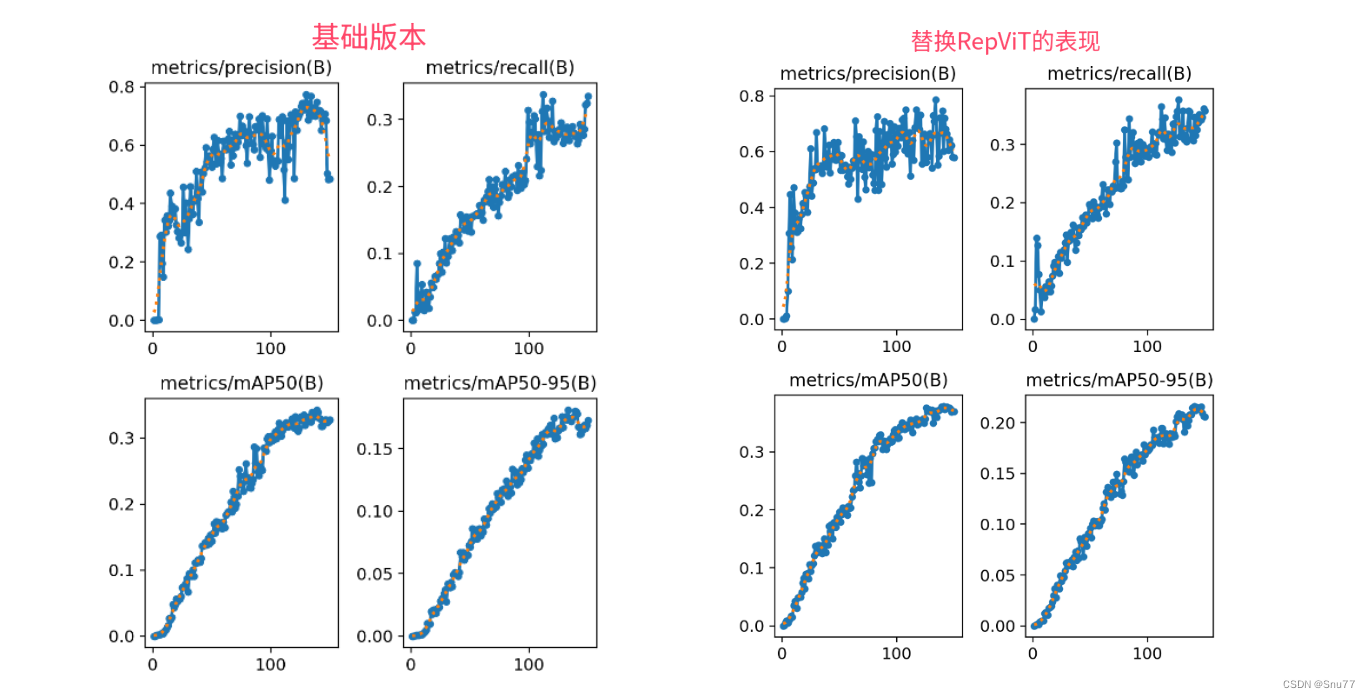
本文给大家来的改进机制是RepViT,用其替换我们整个主干网络,其是今年最新推出的主干网络,其主要思想是将轻量级视觉变换器(ViT)的设计原则应用于传统的轻量级卷积神经网络(CNN)。我将其替换整个YOLOv8的Backbone,实现了大幅度涨点。我对修改后的网络(我用的最轻量的版本),在一个包含1000张图片包含大中小的检测目标的数据集上(共有20+类别),进行训练测试,发现所有的目标上均有一定程度的涨点效果,下面我会附上基础版本和修改版本的训练对比图。
推荐指数:⭐⭐⭐⭐⭐
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2753
2753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











