




原文:百度安全验证 https://baijiahao.baidu.com/s?id=1763013481665368406&wfr=spider&for=pc
https://baijiahao.baidu.com/s?id=1763013481665368406&wfr=spider&for=pc
使用较大的宽高比,配合Prompt: multiple views of the same character in the same outfit
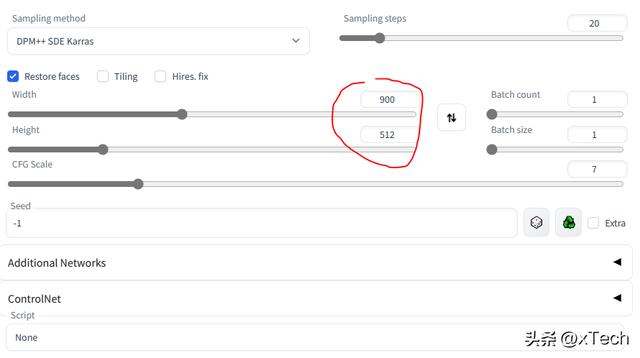
(masterpiece), (high quility), (detailed skin), (photorealistic), best quality, ultra high res, intricate details, a russian 18 years old girl wearing school uniform, buttoned shirt, jeans, necktie, full body, (multiple views of the same character in the same outfit:1.6)
有的时候,绘制多个人物,眼睛等部位可能渲染不好,解决方法:增加细节描述,比如detailed face, detailed eyes, detailed mouth





a Korean 18 year old girl wearing school uniform, perfect face, buttoned shirt, shorts, necktie, full body, multiple views of the same character in the same outfit, photorealistic,best quality, masterpiece, high resolution


人物表情控制
注意:使用强度控制,这里smile强度加大到1.6倍。
a portrait of a Korean girl, 18 year old, (perfect face), (smile:1.6), photorealistic,best quality, masterpiece, high resolutionPrompt S/R
smile, happy, blush, screaming, crying输出结果


使用ControlNet,一次生成人物多种姿态

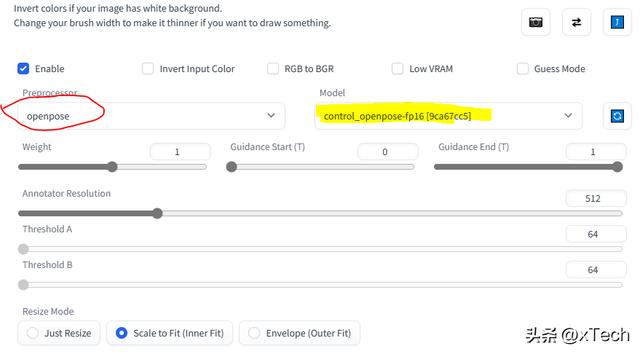
需要配合使用embeddings插件charturnerv2:这是一个civitAI上面已经训练好了的embedding。直接get下来使用即可。
Prompt样例:
charturnerv2, a character turnaround of a [ Eun-Young Yeong-Suk | Ji-Won Ji-Soo | Seong-Hyeon Yeong-Suk ], a 18 years old beautiful girl, (perfect face), wearing long dress, (multiple views of the same character in the same outfit:1.1)输出


使用ControlNet,控制人物单个姿态
使用ControlNet,具体如何配置在之前的文章中已经介绍过了
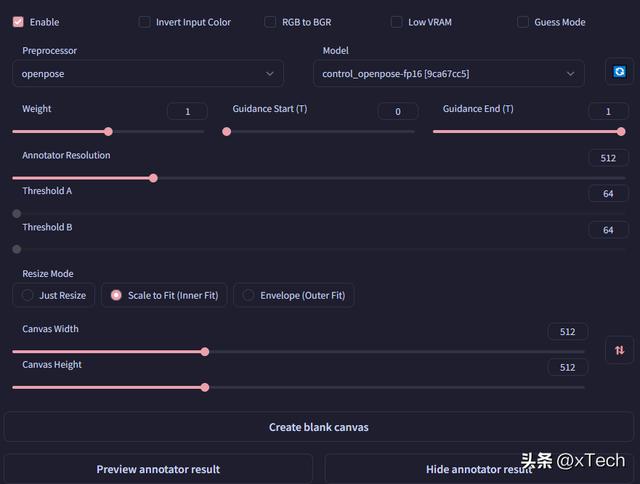
比如使用一种半跪着的姿势

输出结果

你还可以将表情与姿态结合,创作出你所希望的形象。具体这里就不画出来了。
注意:上面介绍的方法在大概90%的情况下,生成的是同一个人物的照片,如果想要达到100%,只要通过模型训练。比如下面的快速训练方法Textual Inversion Embedding。
训练自己的Textual Inversion Embedding
Textual Inversion是一种训练现有神经网络的一小部分的方法,可以用来教会它新的概念,例如绘制特定的人物,或者某种绘画风格。
具体怎么训练的,看这篇文章Stable Diffusion: 训练特定人物模型

















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









