









 本文对比了五款常用GPU在深度学习领域的性能,包括RTX2080Ti、RTX2080、GTX1080Ti、TitanV和TeslaV100。结果显示,截至2018年10月,RTX2080Ti在单GPU深度学习研究中表现最佳,尤其是在FP32和FP16精度下。文章详细分析了各GPU在不同模型上的性能,并考虑了成本因素。
本文对比了五款常用GPU在深度学习领域的性能,包括RTX2080Ti、RTX2080、GTX1080Ti、TitanV和TeslaV100。结果显示,截至2018年10月,RTX2080Ti在单GPU深度学习研究中表现最佳,尤其是在FP32和FP16精度下。文章详细分析了各GPU在不同模型上的性能,并考虑了成本因素。
有人经常问,深度学习的最佳GPU是什么?近日Lambda给出了答案,他们通过比较研究人员常用的前5个GPU来获得答案(测试结果也考虑到了成本和性能):
-
RTX 2080 Ti
-
RTX 2080
-
GTX 1080 Ti
-
Titan V
-
Tesla V100
· 结 · 果 · 总 · 结 ·
截至2018年10月8日,NVIDIA RTX 2080 Ti是运行TensorFlow的单GPU深度学习研究的最佳GPU。其他与这款GPU相比将是:
-
FP32下比 1080 Ti 快 37%,FP16下快 62%,价格贵25%
-
FP32下比 2080 快 35%,FP16下快 47%,价格贵25%
-
FP32下比 Titan V 快 96%,FP16下快3%,成本约为二分之一
-
FP32下比 V100 快 80%,FP16下快82%,成本约为五分之一
· 结 · 果 · 深 · 入 ·
通过测量FP32和FP16吞吐量来评估每个GPU的性能,同时训练常见模型。我们将每个型号的GPU吞吐量除以1080 Ti的吞吐量,这降标准化数据并提供了每个GPU与1080 Ti的加速比,是衡量处理同一工作的两个系统的相对性指标。
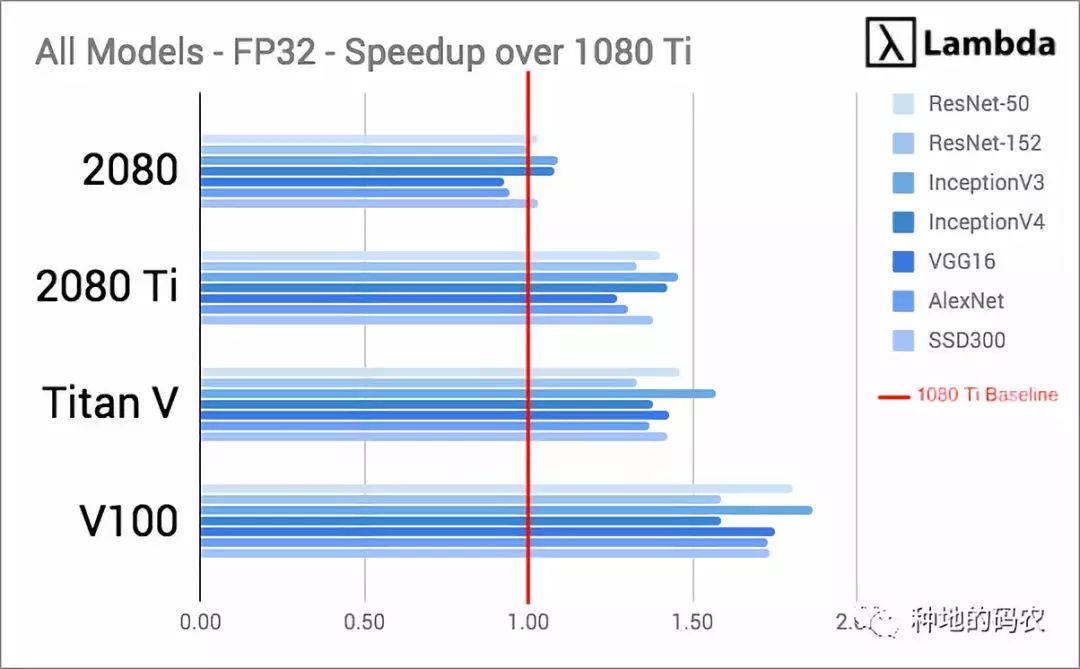
各个型号上GPU的吞吐量
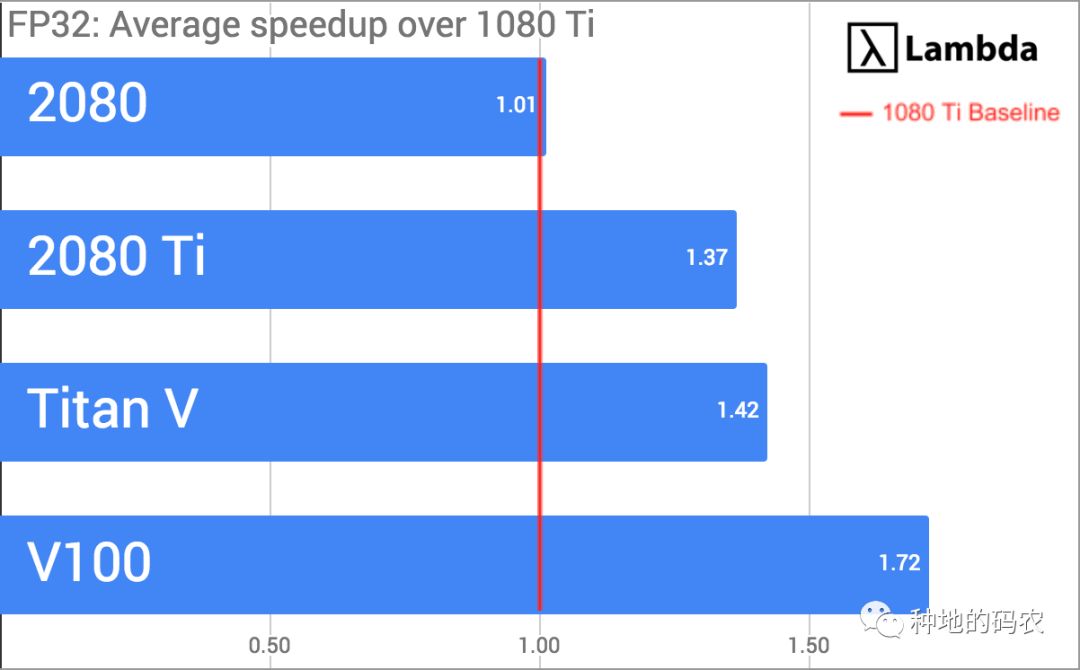
FP32所有模型的平均速度与1080 Ti的对比
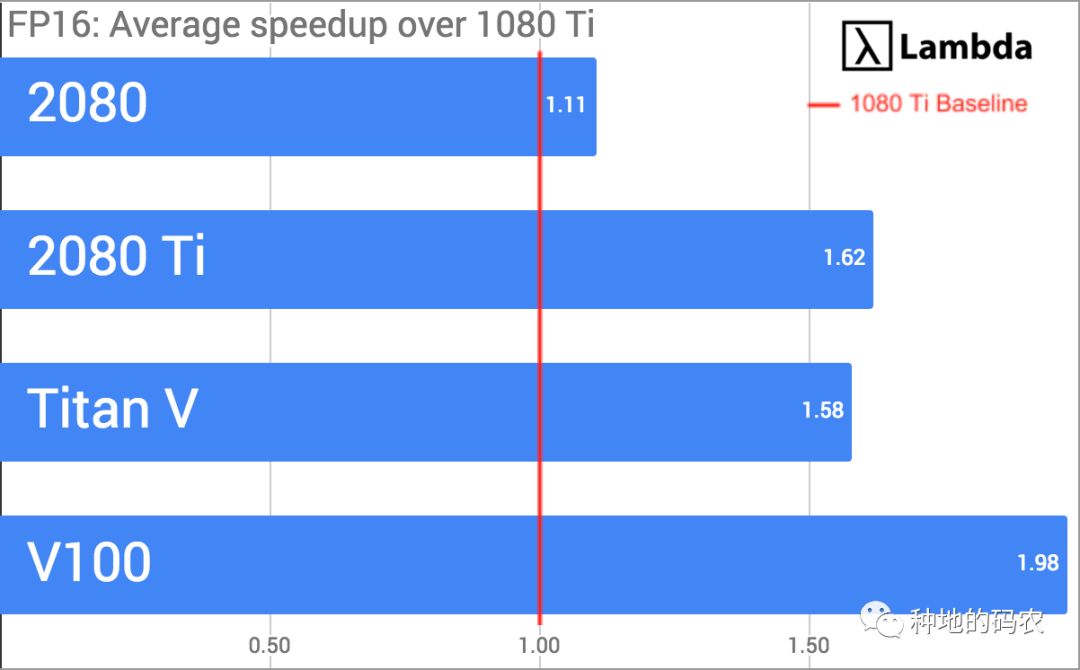
FP16所有模型的平均速度与1080 Ti的对比
最后,我们将每个GPU的值除以系统成本来计算最佳GPU:
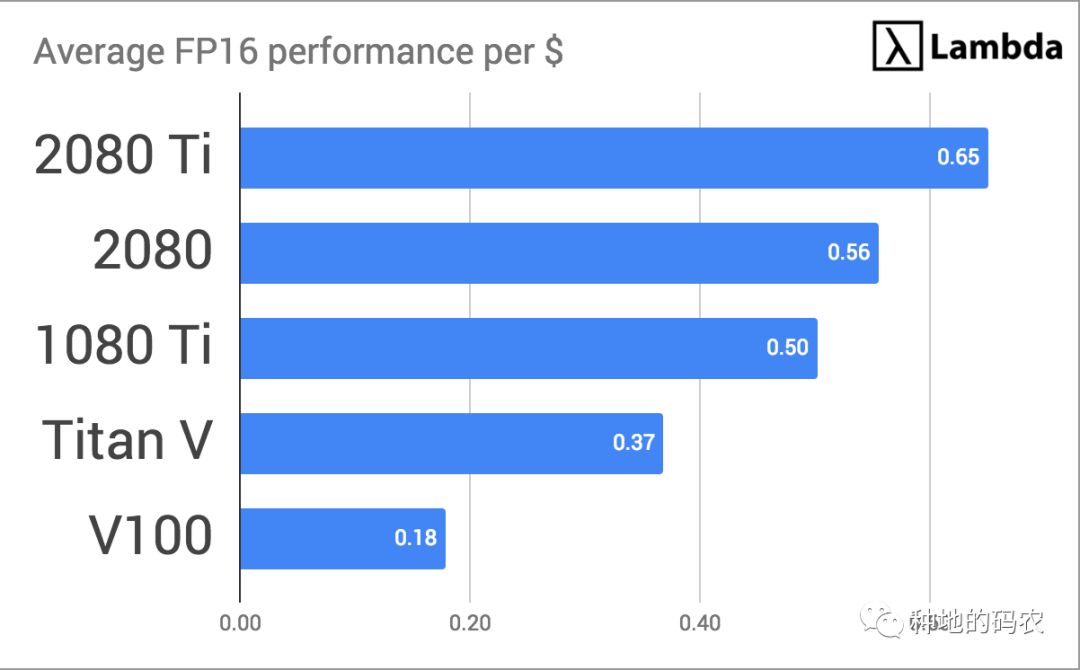
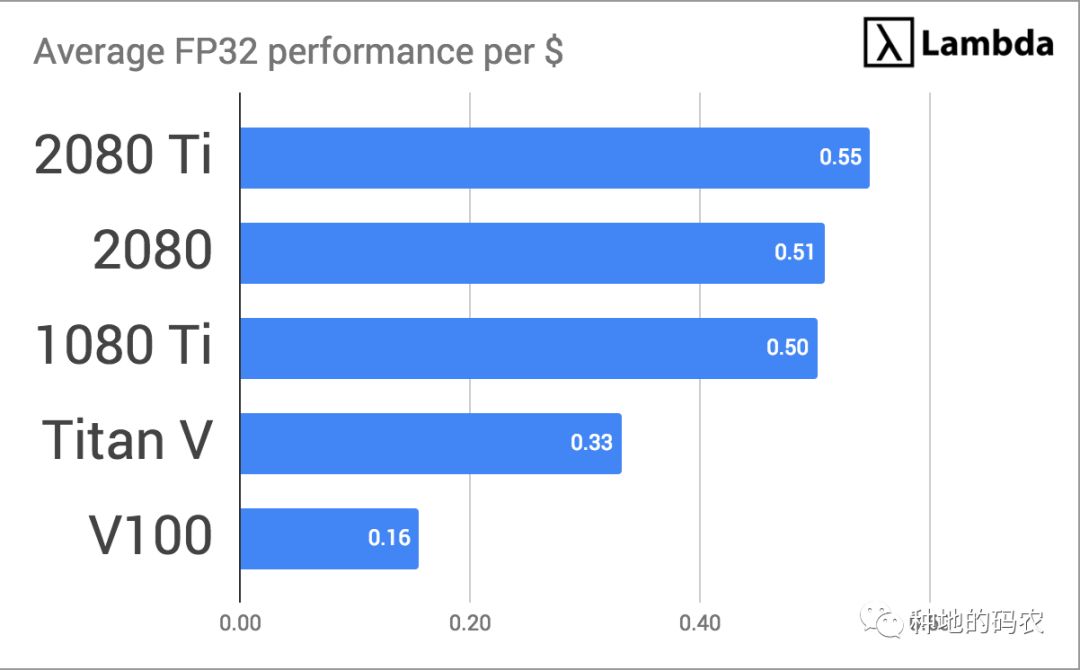

2080 Ti vs V100 2080 Ti真的那么快吗?
2080 Ti的速度比V100快80%,但是价格比V100便宜了非常多,这是为什么?答案很简单:NVIDIA希望细分市场,以便那些支付意愿比较高的人只购买他们的TESLA系列卡。RTX和GTX系列仍然提供较好的性价比。
如果您不是在使用AWS,Azure或者Google Cloud,那么贵买2080 Ti可能要好得多。但是,有一些关键的用例,V100可以派上用场:
-
如果你需要FP64计算,如果你正在进行计算流体动力学,N体模拟或者其他需要高数值京都(FP64)的工作,那么您需要购买Titan V100。如果您不确定是否需要FP64,则不需要。
-
如果你绝对需要32GB的内存,V100可能有意义。然而,这是很少见的,只有5%的用户有这样的需求。大多数人使用像ResNet、VGG、Inception、SSD或Yolo之类的。
所以,你还在想,为什么有人会购买V100?它归结为营销。
原始性能数据
FP32 吞吐量
| Model / GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| ResNet-50 | 209.89 | 286.05 | 298.28 | 368.63 | 203.99 |
| ResNet-152 | 82.78 | 110.24 | 110.13 | 131.69 | 82.83 |
| InceptionV3 | 141.9 | 189.31 | 204.35 | 242.7 | 130.2 |
| InceptionV4 | 61.6 | 81 | 78.64 | 90.6 | 56.98 |
| VGG16 | 123.01 | 169.28 | 190.38 | 233 | 133.16 |
| AlexNet | 2567.38 | 3550.11 | 3729.64 | 4707.67 | 2720.59 |
| SSD300 | 111.04 | 148.51 | 153.55 | 186.8 | 107.71 |
FP16 吞吐量
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 181.2 | 238.45 | 270.27 | 333.33 | 149.39 |
| ResNet-152 | 62.67 | 103.29 | 84.92 | 108.54 | 62.74 |
FP32 (Sako)
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 120.39 | 163.26 | 168.59 | 222.22 | 130.8 |
| ResNet-152 | 43.43 | 75.18 | 61.82 | 80.08 | 53.45 |
FP16 和1080 Ti加速比
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 1.21 | 1.60 | 1.81 | 2.23 | 1.00 |
| ResNet-152 | 1.00 | 1.65 | 1.35 | 1.73 | 1.00 |
FP32 训练加速
| Model/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| VGG16 | 0.92 | 1.25 | 1.29 | 1.70 | 1.00 |
| ResNet-152 | 0.81 | 1.41 | 1.16 | 1.50 | 1.00 |
实验方法
-
所有的模型都在合成数据集上训练,这将GPU性能和CPU预处理性能隔离开来。
-
对于每个GPU,对每个模型进行10次训练。测试每秒处理的图像数量,然后在10次实验中取平均值。
-
通过对图像/秒得分并将其除以特定模型的最小图像/秒得分来计算加速基准。这基本显示了相对基准的百分比改善。(在此使用了1080 Ti)

















 5637
5637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









