







Paper name
nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Paper Reading Note
URL: https://arxiv.org/pdf/2106.11810.pdf
TL;DR
- nuPlan 比赛,提出了规控领域新数据集
Introduction
背景
- 当前自动驾驶规划任务中使用专家系统的方法对于新场景适配较为困难,并且无法基于更多的训练数据进行扩展
- 提供合适的数据和评价指标对于 ML-based 方法研发有重要意义
- 当前 bmk 的问题
- 当前真实世界场景下的 bmk 主要是 shorterm motion forecasting (prediction),而不是 planning
- prediction 只关注其他车的行为,而 plannign 和自车行为有关
- a:缺乏 baseline navigation route;b:L2 distance-based metrics 对于并线等 multi-modal 场景合适;c:open-loop 测试无法引入其他车辆的影响。导致很难在短期(3-8秒)之外进行评估
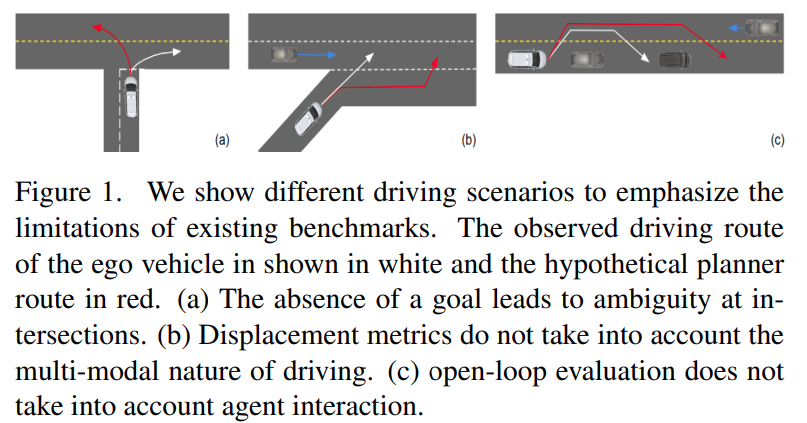
本文方案
- 提出了首个 closed-loop ML-based 规划 bmk
- 大规模驾驶数据集(4 个城市 (Boston, Pittsburgh, Las Vegas and Singapore),1500 h)
- 轻量级的 closed-loop simulator
- 面向 motion-planning 的评价指标,与违反交通规则、人类驾驶相似性、车辆动力学、目标实现等细分方向相关

Dataset/Algorithm/Model/Experiment Detail
实现方式
数据集难点
- 拉斯维加斯包括繁华的赌场接送点(PUDO),互动复杂,繁忙的十字路口,每个方向最多有8条平行车道
- 波士顿路线包括喜欢双重停车(double park)的司机
- 匹兹堡有自己的十字路口左转优先模式
- 新加坡以左手交通(left hand traffic)为特色
整体
- 提供获取地图的 API
- 数据集包含雷达点云、图片、定位信息、转向输入
自动标注
- 使用感知算法(PointPillars with CentePoint,a modified version multi-view fusion (MVF++) )离线处理数据,non-causal tracking 获取跟踪结果
标注场景
- 合并、车道变更、受保护或未受保护的左转或右转、与骑车人的互动、在人行横道或其他地方与行人的互动、与近距离或高加速度的互动、双驻车、停车控制十字路口和在施工区驾驶
测试 BMK
测试整体
- 提交包含 planner 代码的 docker 进行测试
- 使用数据可以在以下二选一
- 自动标注的轨迹
- 原始的传感器数据
- 当查询特定的时间步长时,planner 返回 ego-car 的规划位置和方向
- 提供的控制器会根据预定义的车辆模型控制车辆
任务
- open-loop:期望 planning 模块输出模仿 human driver;每个时间点规划的路线和 gt 路线对比计算得分,规划的路线不用于控制车辆
- close-loop:planner 输出的规划轨迹会给控制器,每个时间点会更根据车辆的新状态给出修正的规划轨迹
- non-reactive close-loop:其他车辆不进行交互,即按照 recorded 路径行驶
- reactive close-loop:non-reactive close-loop 中的大部分碰撞是因为其他车辆无法交互导致,这里为其他车辆都提供一个与 ego 车一样的 planner 进行交互
评价指标
- Traffic rule violation:碰撞率、碰撞时间、脱轨率等指标
- Human driving similarity:纵向速度误差、纵向停车位置误差和横向位置误差等指标;jerk/加速度也会和 human driver 对比
- Vehicle dynamics:jerk/加速度、转向率、震动等指标;并通过汽车运动学模型测试可行性
- Goal achievement:与目标点的 L2 距离
另外还有一些场景特定的评价指标,比如对于行人/骑车人等 interaction,会评估通过的相对速度;比较了 planner 和 human driver 对人行横道和无保护转弯(通行权)的决策之间的一致性。















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









